目录
二叉搜索树的概念及结构
概念
结构
二叉搜索树的基本操作
默认成员函数
默认构造函数与拷贝构造函数
赋值重载
析构函数
二叉搜索树的插入
非递归
递归
二叉搜索树的遍历
中序遍历---升序(左根右)
中序遍历---降序(右根左)
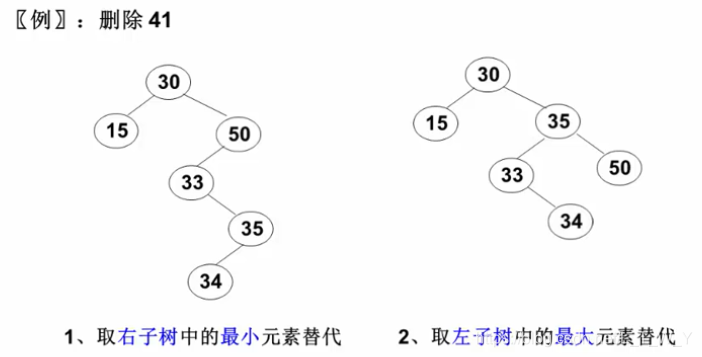
二叉搜索树的删除
非递归
递归
二叉搜索树的查找
非递归
递归
代码
二叉搜索树的概念及结构
概念
二叉搜索树也称二叉排序树或者二叉查找树,它是在普通二叉树上加入一些特性所形成的:
- 1,若左子树非空,则左子树上所有结点的值均小于根结点的值。
- 2,若右子树非空,则右子树上所有结点的值均大于根结点的值。
- 3,其左右子树也分别是一棵二叉搜索树。
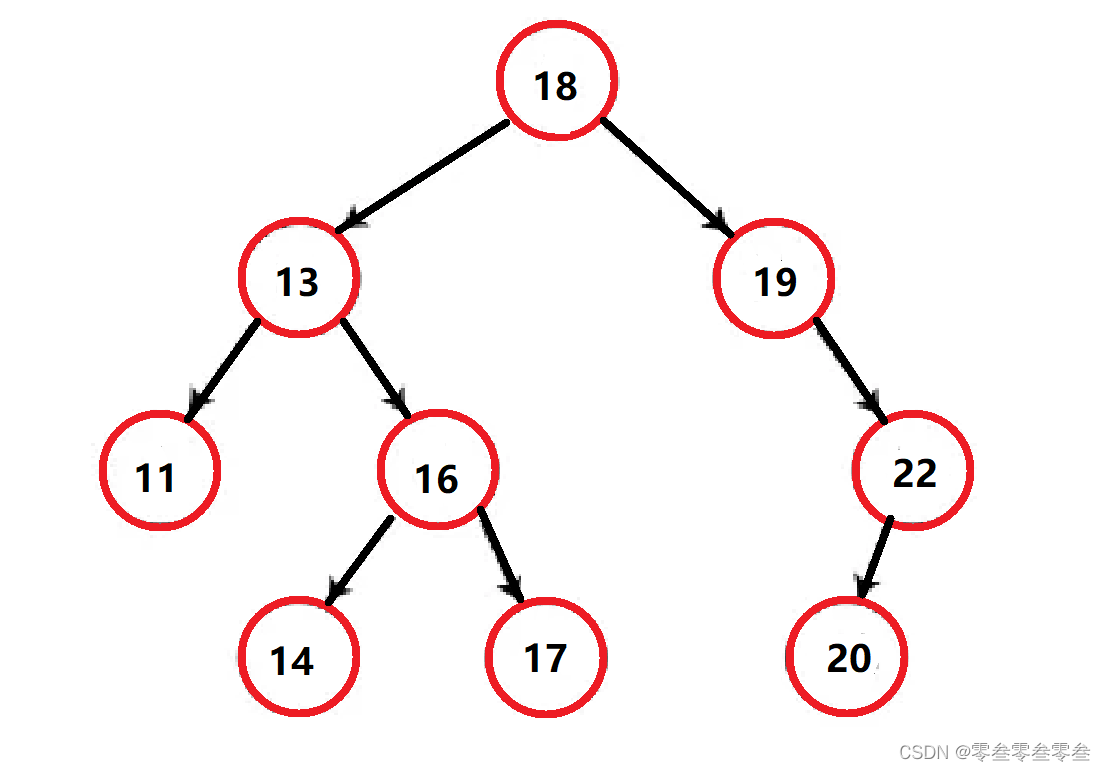
由二叉搜索树的概念可知,左子树结点值 < 根结点值 < 右子树结点值;所有当二叉搜索树进行中序遍历也就是左根右遍历时,可以得到升序的结果;如果是右根左遍历,就可以得到降序的结果。
结构
二叉搜索树的物理结构更适合采用链式结构,_left存储比根结点值小的结点地址,_right存储比根结点值大的结点地址。
二叉搜索树的基本操作
对于二叉搜索树的基本操作,我们选择把它的基本操作与其根结点地址封装到一个类中。
默认成员函数
二叉搜索树的默认成员函数都需要自己来实现,因为构造与析构涉及到开辟空间与释放空间的操作,而拷贝构造与赋值操作涉及到深拷贝的问题。
默认构造函数与拷贝构造函数
默认构造函数只需要实现一个无参的构造函数就可以,其作用就是将_root置空。
// 构造BSTree():_root(nullptr) {}而拷贝构造函数需要进行深拷贝,就是将被拷贝的二叉搜索树每个结点值拷贝到新开辟结点中,并将新开辟的结点连接成与被拷贝的二叉搜索树结构一样。该拷贝构造过程需要使用到前序遍历的思想,因为先要有双亲结点,才能有左右孩子结点。
// 拷贝构造BSTree(const BSTree& b):_root(_CopyBSTree(b._root)){}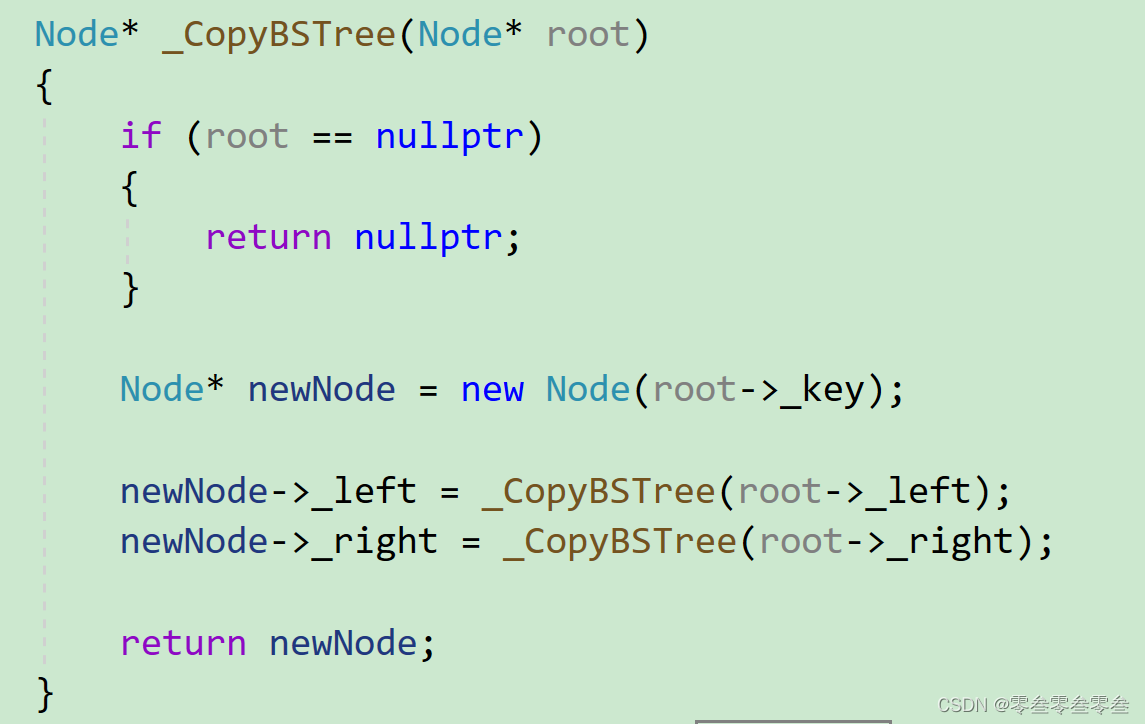
赋值重载
赋值重载需要利用到拷贝构造,也就是让被拷贝的二叉搜索树拷贝构造一棵新的二叉搜索树,再让这课新树与需要赋值的树进行交换,即完成赋值。
// 赋值重载BSTree<K>& operator=(BSTree<K> b){swap(_root, b._root);return *this;}析构函数
析构函数的实现就是通过后序遍历,将二叉搜索树中每一个结点依次释放即可。
// 析构~BSTree(){_DestroyBSTree(_root);_root = nullptr;}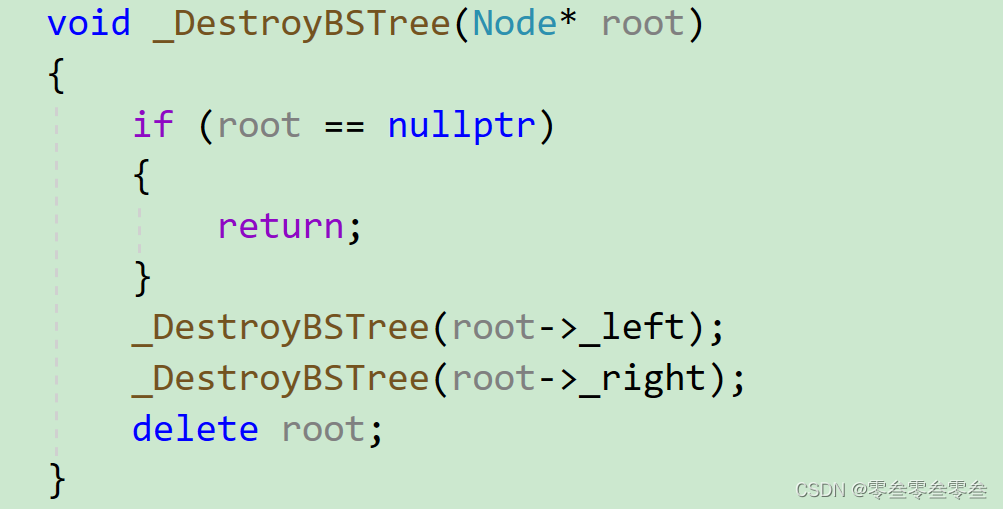
二叉搜索树的插入
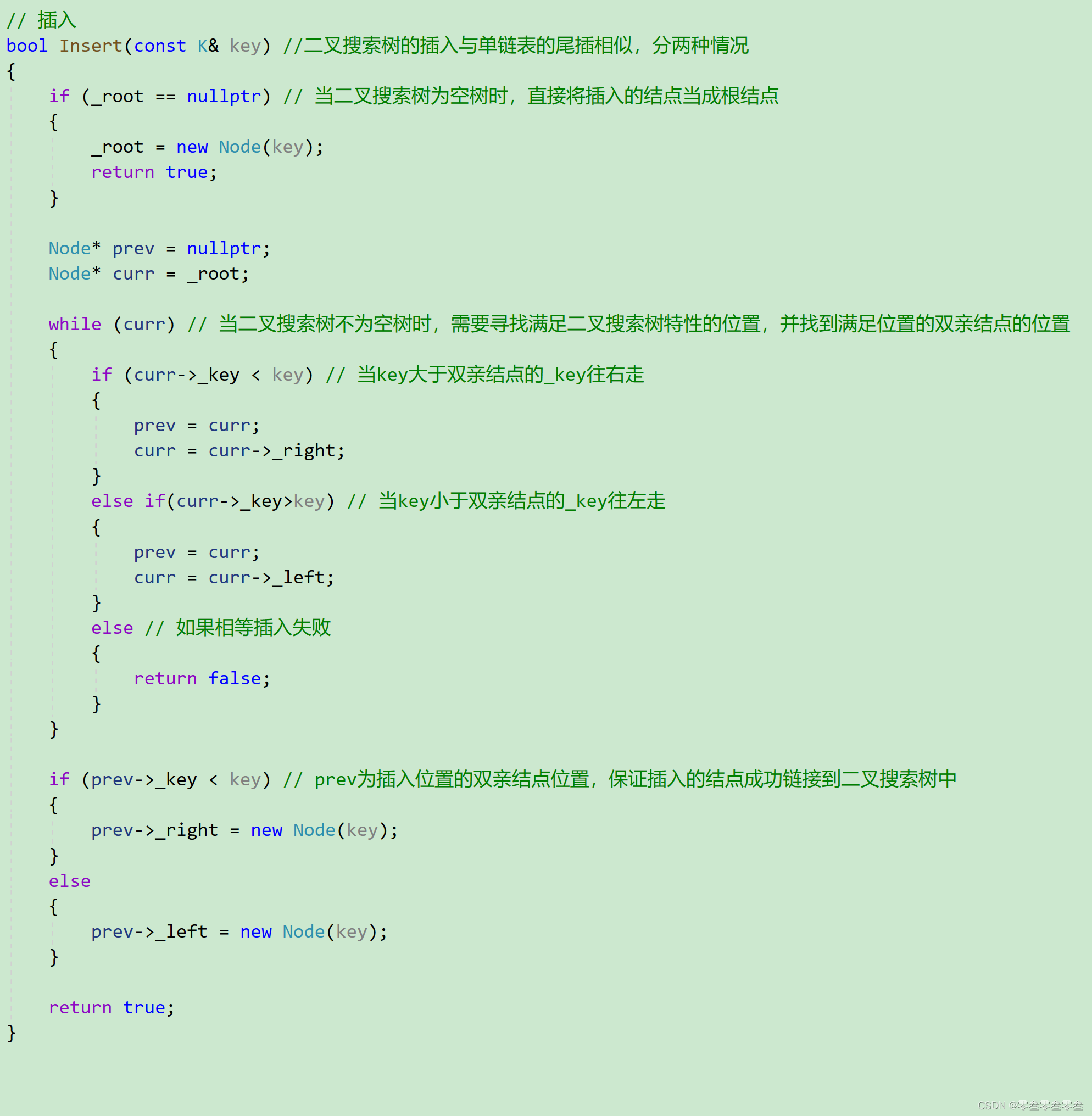
若原二叉搜索树为空树,则直接将新结点插入到根;否则,根据根结点的值进行判断插入,若插入的值小于根,则插入到左子树中,若插入的值大于根,则插入到右子树中。
需要注意的是,若插入的值在原二叉搜索树中已经存在了,则插入失败;而且插入的这个新结点一定是叶子结点。
非递归
递归
// 插入---递归bool InsertR(const K& key){return _InsertR(_root, key);}
二叉搜索树的遍历
二叉搜索树的中序遍历是最有意义的。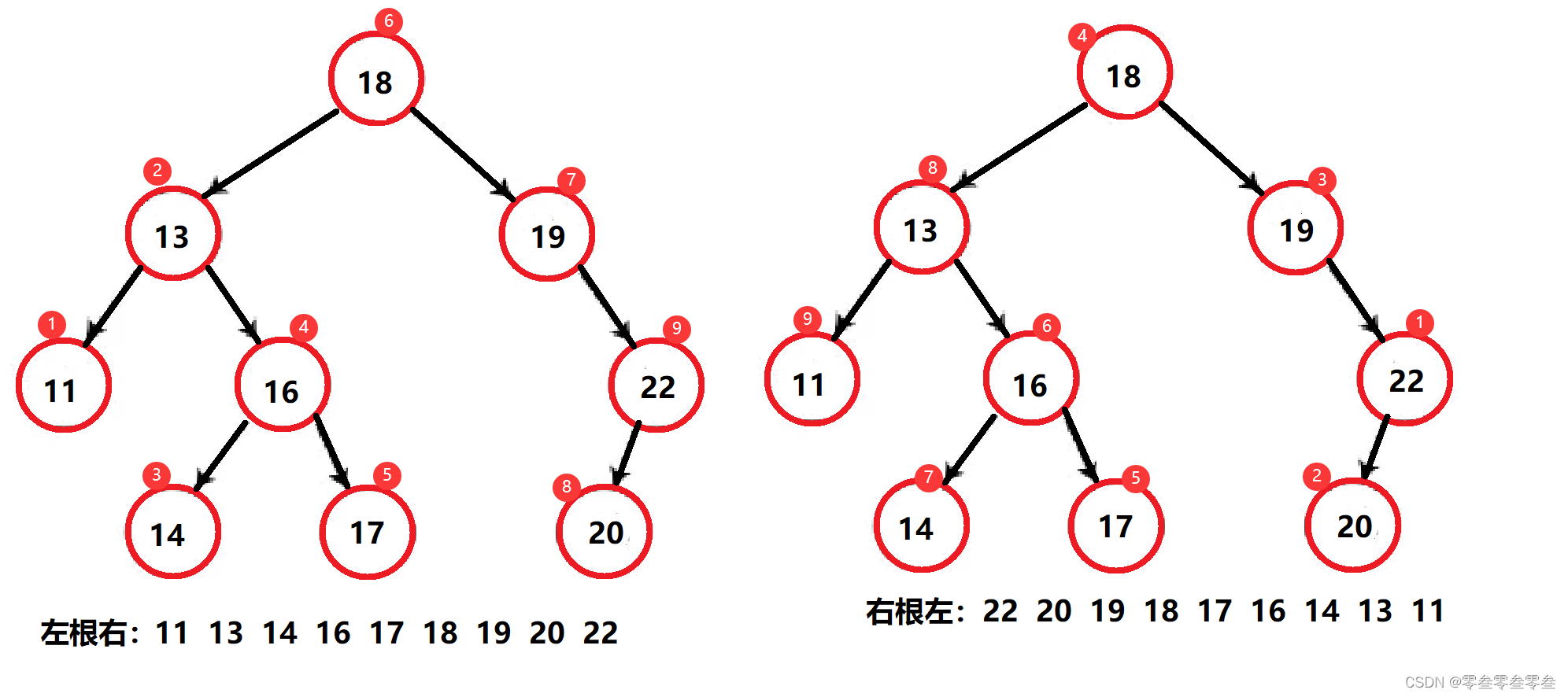
中序遍历---升序(左根右)
void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}// 中序遍历---升序void InOrder(){_InOrder(_root);cout << endl;}中序遍历---降序(右根左)
void _InOrderReverse(Node* root){if (root == nullptr){return;}_InOrderReverse(root->_right);cout << root->_key << " ";_InOrderReverse(root->_left);}// 中序遍历---降序void InOrderReverse(){_InOrderReverse(_root);cout << endl;}二叉搜索树的删除
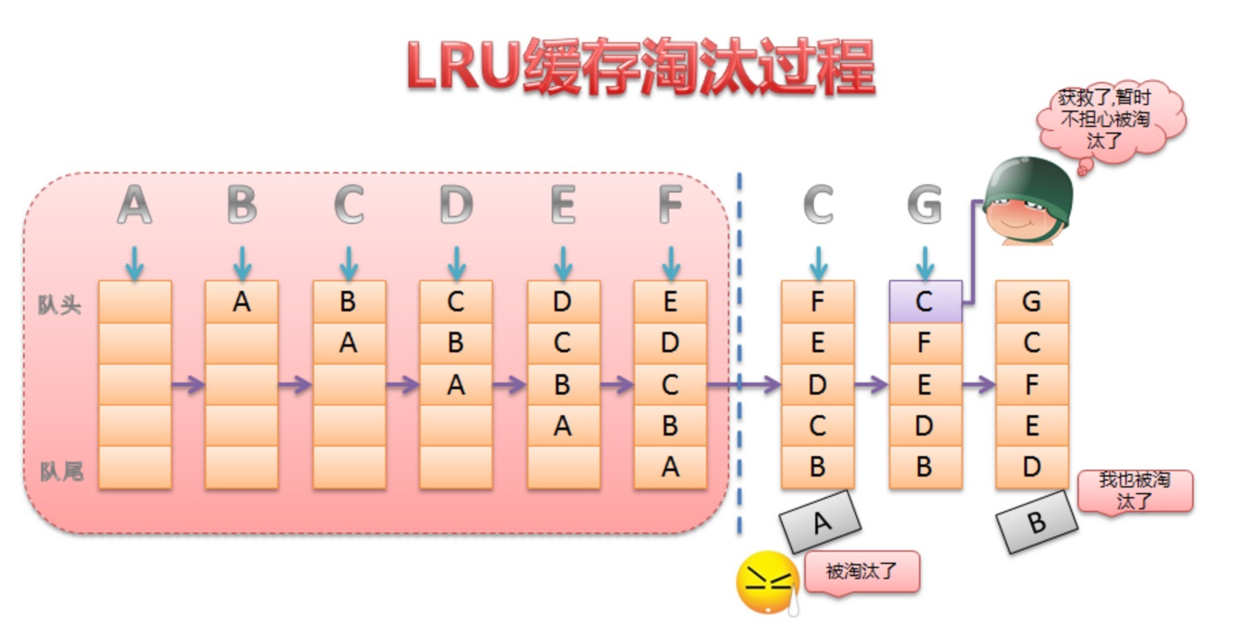
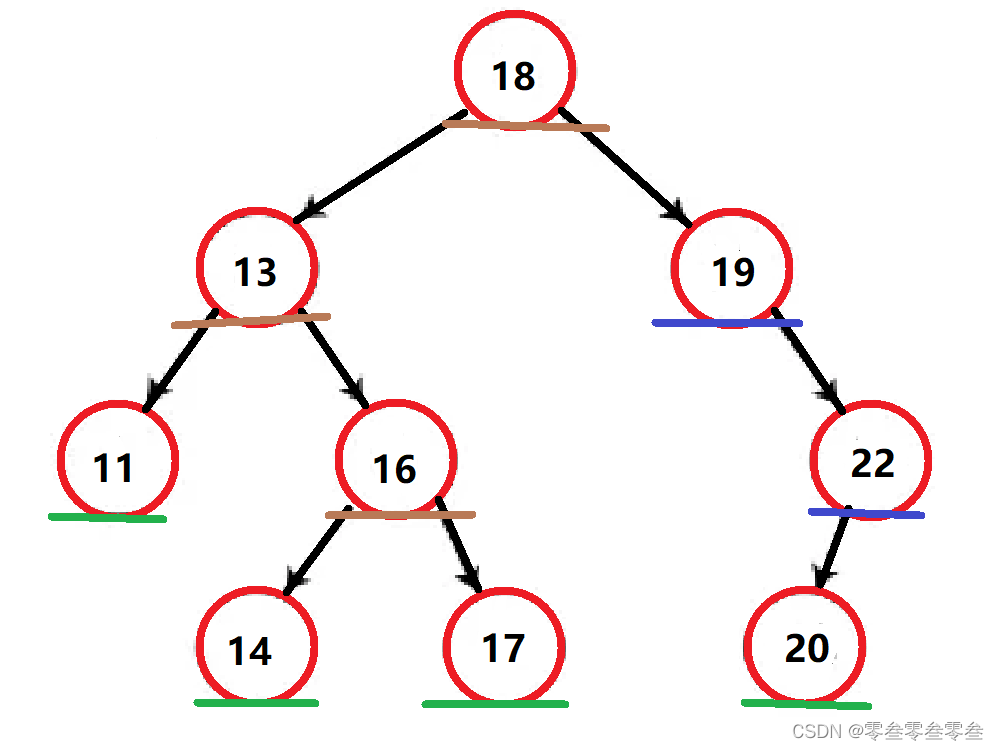 删除分为三种情况:
删除分为三种情况:
1,若删除的是11,14,17,20这样的叶子结点,可以直接删除,并将其双亲结点指向自己的指针置空。
2,若删除的是19,20这样有一个孩子的结点,则可以将自己的孩子给其双亲托管,再删除自己。
3,若删除的是18,13.16这样有两个孩子的结点,可以使用替换删除法:去要删除结点的左右子树中找到可以顶替自己的结点,也就是在其左子树中找最大的结点或者在其右子树中找最小结点。找到之后保存该结点(该结点的特征与1或者2一样)的值,并删除该结点,最后将保存的值给要删除的结点。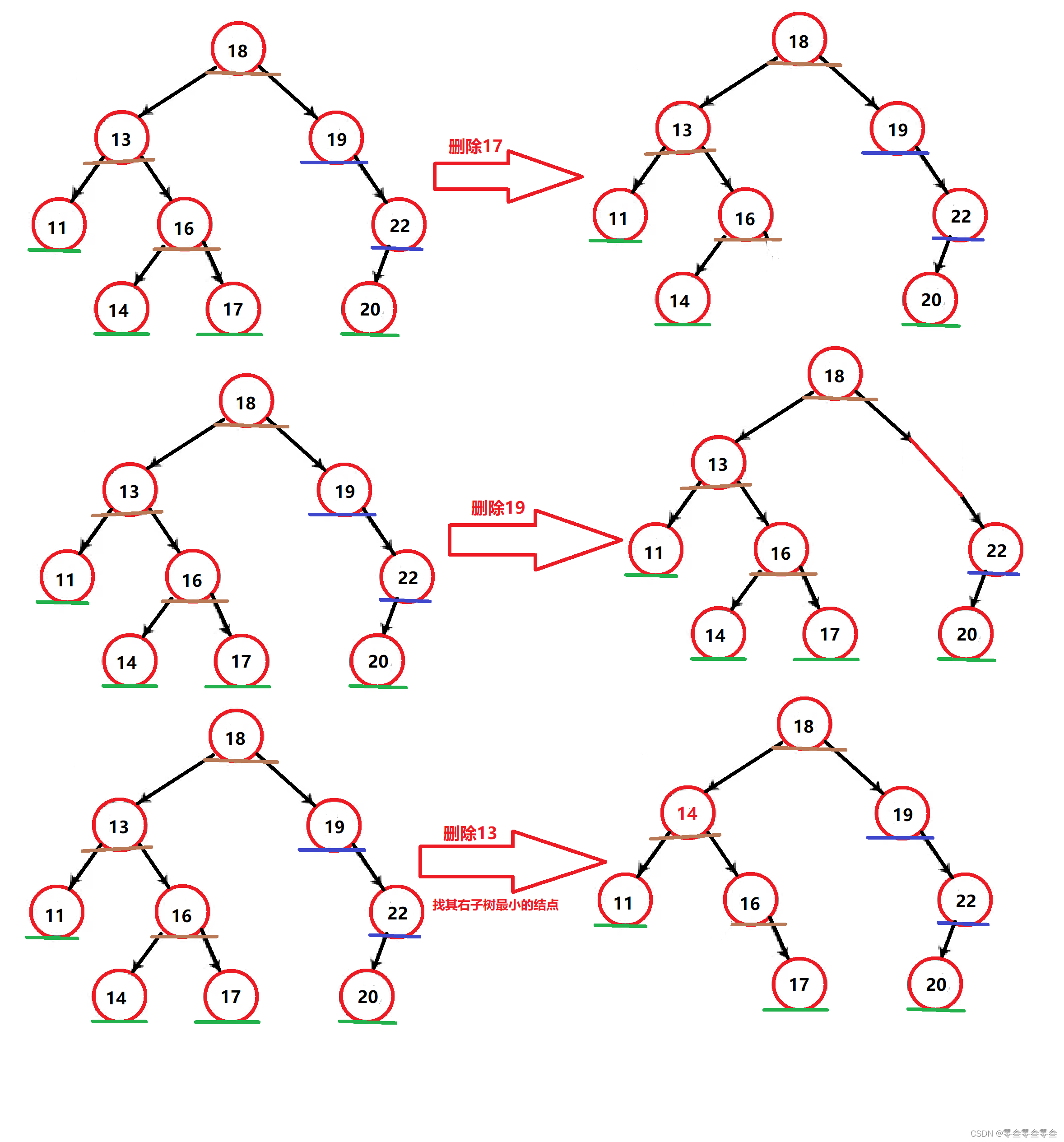
非递归

递归
// 删除---递归bool EraseR(const K& key){return _EraseR(_root, key);}
二叉搜索树的查找
二叉搜索树的查找就是从根结点开始,沿着某个分支逐层向下比较的过程。先将要查找的值与根结点值比较,如果相等则查找成功;如果不相等,若查找的值小于根结点值,则在根结点的左子树上查找,否则在根结点的右子树上查找;没有找到则返回nullptr。
非递归

递归
// 查找---递归Node* FindR(const K& key){return _FindR(_root, key);}
二叉搜索树的插入删除查找的时间复杂度为O(n),因为二叉搜索树不能保证自身的结构不是一棵单支树,所以二叉搜索树需要进行优化成AVL树和红黑树。
代码
#pragma once
#include <iostream>
#include <cstdbool>
using namespace std;template <class K>
struct BSTreeNode
{struct BSTreeNode<K>* _left;struct BSTreeNode<K>* _right;K _key;BSTreeNode(const K& key=K()):_left(nullptr),_right(nullptr),_key(key){}
};template <class K>
class BSTree
{typedef struct BSTreeNode<K> Node;private:Node* _root;void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->_left);cout << root->_key << " ";_InOrder(root->_right);}void _InOrderReverse(Node* root){if (root == nullptr){return;}_InOrderReverse(root->_right);cout << root->_key << " ";_InOrderReverse(root->_left);}bool _InsertR(Node* &root,const K& key){if (root == nullptr){root = new Node(key);return true;}if (root->_key < key){return _InsertR(root->_right, key);}else if(root->_key>key){return _InsertR(root->_left, key);}else{return false;}}Node* _FindR(Node* root, const K& key){if (root == nullptr) // 查找失败{return nullptr;}if (root->_key < key) // 大于根结点值,往根结点的右子树上查找{return _FindR(root->_right, key);}else if(root->_key>key) // 小于根结点值,往根结点的左子树上查找{return _FindR(root->_left, key);}else // 查找成功{return root; // 查找成功}}bool _EraseR(Node*& root, const K& key){if (root == nullptr){return false;}if (root->_key < key){return _EraseR(root->_right, key);}else if (root->_key > key){return _EraseR(root->_left, key);}else // 找到了要删除的结点{if (root->_left == nullptr){Node* del = root;root = root->_right;delete del;return true;}else if(root->_right==nullptr){Node* del = root;root = root->_left;delete del;return true;}else{Node* min = root->_right;while (min->_left){min = min->_left;}K tmp = min->_key;_EraseR(root, tmp);root->_key = tmp;return true;}}}Node* _CopyBSTree(Node* root){if (root == nullptr){return nullptr;}Node* newNode = new Node(root->_key);newNode->_left = _CopyBSTree(root->_left);newNode->_right = _CopyBSTree(root->_right);return newNode;}void _DestroyBSTree(Node* root){if (root == nullptr){return;}_DestroyBSTree(root->_left);_DestroyBSTree(root->_right);delete root;}public: // 构造BSTree():_root(nullptr) {}// 拷贝构造BSTree(const BSTree& b):_root(_CopyBSTree(b._root)){}// 赋值重载BSTree<K>& operator=(BSTree<K> b){swap(_root, b._root);return *this;}// 析构~BSTree(){_DestroyBSTree(_root);_root = nullptr;}// 插入bool Insert(const K& key) //二叉搜索树的插入与单链表的尾插相似,分两种情况{if (_root == nullptr) // 当二叉搜索树为空树时,直接将插入的结点当成根结点{_root = new Node(key);return true;}Node* prev = nullptr;Node* curr = _root;while (curr) // 当二叉搜索树不为空树时,需要寻找满足二叉搜索树特性的位置,并找到满足位置的双亲结点的位置{if (curr->_key < key) // 当key大于双亲结点的_key往右走{prev = curr;curr = curr->_right;}else if(curr->_key>key) // 当key小于双亲结点的_key往左走{prev = curr;curr = curr->_left;}else // 如果相等插入失败{return false;}}if (prev->_key < key) // prev为插入位置的双亲结点位置,保证插入的结点成功链接到二叉搜索树中{prev->_right = new Node(key);}else{prev->_left = new Node(key);}return true;}// 中序遍历---升序void InOrder(){_InOrder(_root);cout << endl;}// 中序遍历---降序void InOrderReverse(){_InOrderReverse(_root);cout << endl;}// 查找Node* Find(const K& key) // 二叉搜索树的查找与单链表的查找相似{Node* curr = _root;while (curr){if (curr->_key < key){curr = curr->_right;}else if (curr->_key > key){curr = curr->_left;}else{return curr;}}return nullptr; // return curr; 也行}// 删除bool Erase(const K&key){Node* prev = nullptr;Node* curr = _root;while (curr) // 寻找值为key的结点,prev为该结点的双亲结点{if (curr->_key < key) // 如果key大于当前结点的_key,则往右走{prev = curr;curr = curr->_right;}else if(curr->_key>key) // 如果key小于当前结点的_key,则往左走{prev = curr;curr = curr->_left;}else // 找到_key为key的结点---该结点分为三类:1,没有左右孩子结点 2,有一个孩子结点 3,左右孩子结点都{if (curr->_left == nullptr) // 如果该结点没有左孩子结点,则需要将该结点的右结点给其双亲结点{if (curr == _root) // 如果删除的是根结点,则将_root改为其右子树{_root = curr->_right;}else {if (prev->_left == curr) // 判断删除的结点是双亲的左孩子还是右孩子{prev->_left = curr->_right;}else{prev->_right = curr->_right;}}delete curr;return true;}else if (curr->_right == nullptr) // 如果该结点没有右孩子结点,则需要将该结点的左结点给其双亲结点{if (curr == _root) // 如果删除的是根结点,则将_root改为其左子树{_root = curr->_left;}else{if (prev->_left == curr)// 判断删除的结点是双亲的左孩子还是右孩子{prev->_left = curr->_left;}else{prev->_right = curr->_left;}}delete curr;return true;}else // 如果删除的结点左右孩子都有,则进行替换删除{/*Node* minPrev = curr; Node* min = curr->_right; // 寻找删除结点的右子树中最小结点while (min->_left){minPrev = min;min = min->_left;}if (minPrev == curr) // 避免最小结点是删除结点的右孩子结点{minPrev->_right = min->_right;}else{minPrev->_left = min->_right;}curr->_key = min->_key;delete min;*/Node* min = curr->_right; // 选出右子树最小的结点while (min->_left){min = min->_left;}K tmp = min->_key; // 保存右子树最小结点的值Erase(tmp); // 将tmp值的结点删除_root->_key = tmp; // 再将tmp的值赋给有两个孩子的结点,想当将这个结点删除return true;}}}return false; // 没有找到删除的结点,则说明删除失败,返回false}// 插入---递归bool InsertR(const K& key){return _InsertR(_root, key);}// 查找---递归Node* FindR(const K& key){return _FindR(_root, key);}// 删除---递归bool EraseR(const K& key){return _EraseR(_root, key);}};