目录
- 二叉搜索树
- 二叉搜索树概念
- 增删查改接口
- 插入
- 递归插入
- 查找
- 递归查找
- 删除
- 递归删除
- 成员函数
- 拷贝构造
- 拷贝赋值
- 析构
- 二叉搜索树的应用
- 二叉搜索树的性能分析
二叉搜索树
二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树

增删查改接口
插入
//增删查改
bool insert(const T& val)
{Node* node = new Node(val);if (!_root) {_root = node;}else {Node* cur = _root;Node* parent = nullptr;while (cur) {//插入的结点val值比根大if (cur->_key < val) {parent = cur;cur = cur->_right;}//插入的结点val值比根小else if (cur->_key > val) {parent = cur;cur = cur->_left;}else {//插入失败return false;}}// 判断插入的值是在根的左边还是根的右边if (parent->_key > val) parent->_left = node;else parent->_right = node;}return true;
}
递归插入
bool InsertR(const T& val)
{return _InsertR(_root, val);
}bool _InsertR(Node*& root, const T& val)
{//直到走到null位置处,也正是插入结点的适当位置if (!root){root = new Node(val);return true;}//如果比根小那么就去左子树找插入位置if (root->_key > val) {return _InsertR(root->_left, val);}//如果比根大,那么就去右子树找插入位置else if (root->_key < val) {return _InsertR(root->_right, val);}else {//二叉搜索树并不会存在重复的值,如果val既不大于也不小于那就是相等了return false;}
}
查找
//查找
Node* Find(const T& val)
{Node* cur = _root;while (cur){//比根大if (cur->_key < val){cur = cur->_right;}//比根小else if (cur->_key > val){cur = cur->_left;}else{//返回查找到的结点return cur;}}return nullptr;
}
递归查找
Node* _FindR(Node* root, const T& val)
{//直到走到null还没有找到就返回nullif (!root) return nullptr;//比根大if (root->_key < val)return _FindR(root->_right, val);//比根小else if (root->_key > val)return _FindR(root->_left, val);//找到了elsereturn root;
}
//递归版本Node* FindR(const T&val)
{return _FindR(_root,val);
}
删除
搜索树的删除需要考虑三种情况
删除一个值等于key的结点,分情况分析:

1、要删除的是6、9、0…,这个几个结点的特征是属于叶子结点,而删除叶子结点只需要将结点的父亲指向孩子的左或者孩子的右都行。

2、要删除的结点是8、1…,这几个结点的特征时属于只有一个孩子的结点,删除的方式是通过父亲去接管孩子的孩子,再把孩子给删除
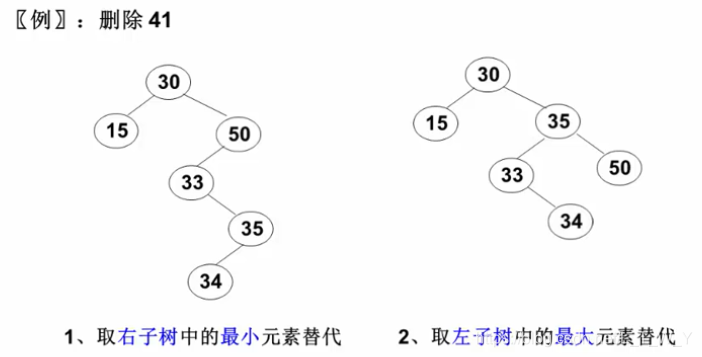
3、要删除的结点是5、7,这两个结点的特征是拥有两个孩子,并不好处理,也不满足1、2的特征
如果能够通过一个解决办法直接将特征3的复杂度降低为特征1的复杂度就会变得很好处理。
解决办法:替换法删除,去左右子树中找一个能够替换自己位置的结点,替换自己删除
这里可以通过搜索树的性质来决定:
1、左子树最大值得结点就是左子树最右边的结点:4
2、右子树最小值的结点就是右子树最左的结点:6
通过这两个结点去替换要删除的结点
先看删除val值为5的结点,通过替换法,将问题复杂度直接降低为特征1

先看删除val值为7的结点,通过替换法,将问题复杂度直接降低为特征2

而在这里的特征2的处理方式同样也能解决特征1的问题,所以在替换法删除结点的时候都采用特征2的处理方式
//删除
bool Erase(const T& val)
{Node* parent = nullptr;Node* cur = _root;while (cur) {//如果val值的结点小于根结点那就去左子树找if (cur->_key > val) {parent = cur;cur = cur->_left;}//如果val值的结点大于根结点那就去右子树找else if (cur->_key < val) {parent = cur;cur = cur->_right;}else //找到的情况{//处理特征2,考虑左边为null,删除只有一个孩子的结点if (!cur->_left) {if(_root == cur){_root = cur->_right;}else{if (parent->_left == cur)parent->_left = cur->_right;elseparent->_right = cur->_right;}delete cur;}//考虑右边为nullelse if (!cur->_right) {if(_root == cur){_root = cur->_left;}if (parent->_left == cur)parent->_left = cur->_left;elseparent->_right = cur->_left;delete cur;}//处理特征3else {Node* minparent = cur;Node* minRight = cur->_right;while (minRight->_left) //找右子树的最左结点,右子树的最左结点适合当替代结点{minparent = minRight;minRight = minRight->_left;}cur->_key = minRight->_key; //替换if (minparent->_left == minRight) //这里需要考虑两个最左的情况 minparent->_left = minRight->_right ; //左子树的最左elseminparent->_right = minRight->_right; //右子树的最左delete minRight;}return true;}}return false;
}
递归删除
bool EraseR(const T&val)
{return _EraseR(_root, val);
}bool _EraseR(Node*& root, const T& val) //注意这里传递的是指针的别名
{if (root->_key > val) {return _EraseR(root->_left, val);}else if (root->_key < val) {return _EraseR(root->_right, val);}else //找到了{if (!root->_left) {Node* del = root;root = root->_right; //root是指针的别名delete del; //删除值为val的结点}else if (!root->_right) {Node* del = root;root = root->_left; //root是指针的别名delete del; //删除值为val的结点}else {Node* minright = root->_right;while (minright->_left) {minright = minright->_left; //找到右子树的最左值}T min = minright->_key;_EraseR(root->_right ,min);//将问题规模缩小到在右子树中删除替换结点,使用递归删除复用前面删除一个结点的逻辑root->_key = min;//使用min将原结点的值覆盖达到替换的目的}return true; //删除成功返回true}return false;
}
成员函数
拷贝构造
//拷贝构造
BSTree(const BSTree<T>& root)
{_root = copy(root._root);
}
//使用前序遍历的思想,将每一个结点都开辟出来,返回的过程中链接在一起
Node* copy(Node *root)
{ if (!root){return nullptr;}else {Node* copynode = new Node(root->_key);copynode->_left = copy(root->_left);copynode->_right = copy(root->_right);return copynode;}}
拷贝赋值
//拷贝赋值 ,现代写法,借助形参对象来构造*this对象,交换他们的_root
BSTree<T>& operator=(BSTree<T> Tree)
{swap(_root, Tree._root);return *this;
}
析构
~BSTree()
{_Destroy(_root);_root = nullptr; //防止野指针
}
//释放结点申请的内存,使用后序遍历的思想,从最后一个结点开始倒着删除
void _Destroy(Node *root)
{if (!root) return;_Destroy(root->_left);_Destroy(root->_right);delete root;
}
二叉搜索树的应用
搜索二叉树的kv模型只要在现有的基础上增加键值对就行,相关的代码博主已经上传在git上: link.
1、 K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:以单词集合中的每个单词作为key,构建一棵二叉搜索树在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
void func()
{BSTree<string, string> bs;bs.Insert("administration","管理");bs.Insert("translate", "翻译");bs.Insert("modern", "现代");bs.Insert("tape", "磁带");bs.Insert("hard disk", "硬盘");bs.Insert("computer", "电脑");string str; while (cin >> str){BSTNode<string, string>* ret = bs.FindR(str);if (!ret)cout << "拼写错误没有该单词" << endl;elsecout << ret->_key << ":" << ret->_value << endl;}
}
2、 KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方式在现实生活中非常常见:比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出现次数就是<word, count>就构成一种键值对。比如:实现一个简单的英汉词典dict,可以通过英文找到与其对应的中文,具体实现方式如下:<单词,中文含义>为键值对构造二叉搜索树,注意:二叉搜索树需要比较,键值对比较时只比较Key查询英文单词时,只需给出英文单词,就可快速找到与其对应的
BSTree<string, int> bs;
string str[] = {"电脑","cpu","电脑","硬盘","硬盘","显卡","显卡","显示器"};
for (const auto &ref : str)
{BSTNode<string, int>* ret = bs.FindR(ref);if (!ret) //如果词典中没有ref这个单词就插入一个单词bs.InsertR(ref, 1);elseret->_value++; //对重复存在的单词计数
}
bs.Inorder();
二叉搜索树的性能分析
1、插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
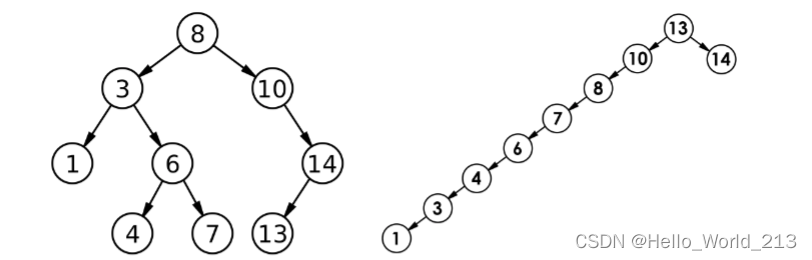
2、但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:
最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:O(log n)

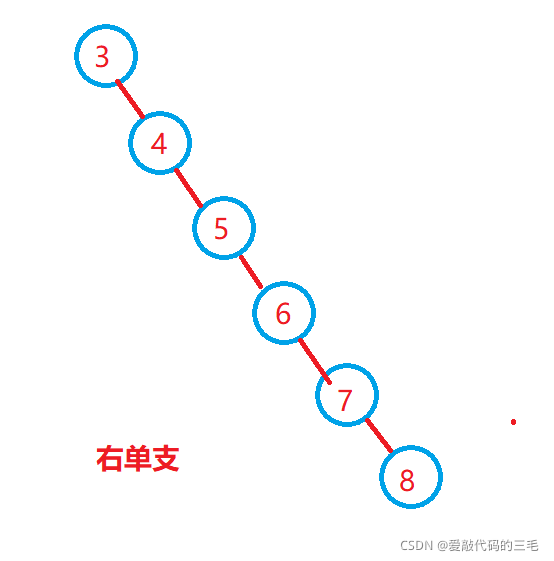
最坏情况下,二叉搜索树为右单支,其平均比较次数为:O(n / 2)