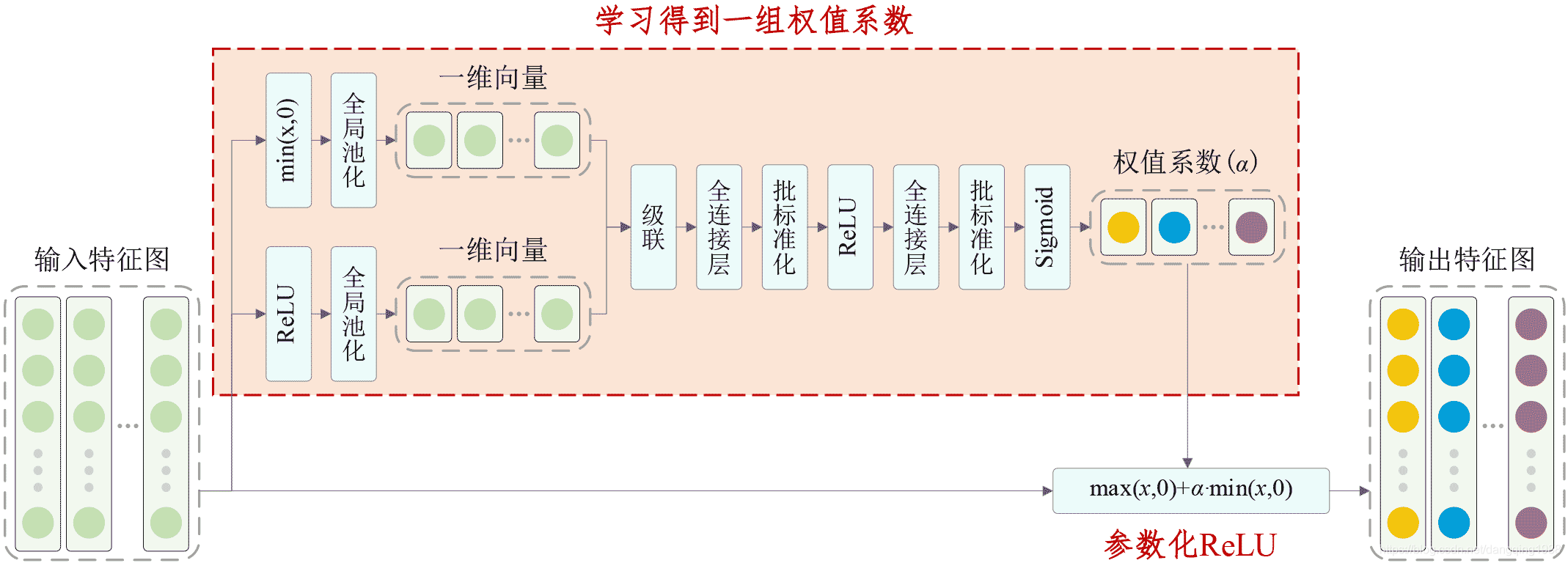
简介:
之前对堆排序认识的不是很透彻,今天回过头来再把堆排序的知识整理整理!以及排升序为什么要建大堆,排降序要建小堆。
正文:
首先我们要知道:
①堆的逻辑是一颗完全二叉树;
②它使用的是顺序存储(也就是数组);
③它的作用:一般都是用于找最值。
排序也就是对数组的元素按照大小规则进行摆放。
堆排序的过程:
1、建堆
2、对建好的堆进行向下调整。
可能有人会疑问?堆已经建立好了,为什么还要向下调整?
来看看下面的解释:
我们先给定一个数组arr[ ] = { 7, 6, 3, 5, 4, 1, 2 }; 将其排成一个大堆。如下图:

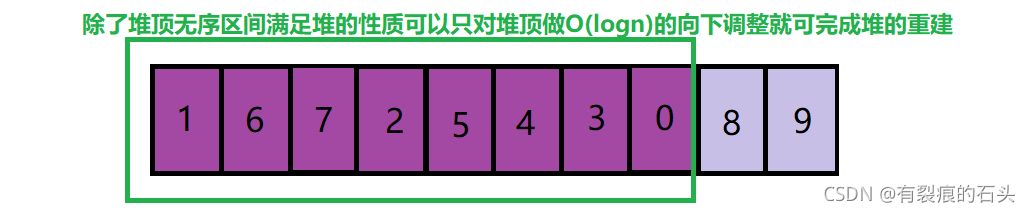
当我们建好堆之后,我们发现这个堆层序遍历下来是一个降序的。那么要将它变成一个升序的顺序,就要将它逆序。
也就是交换堆顶和最后一个元素的位置,然后从堆顶开始向下调整,每交换一个位置,就多一个数据已经排好升序。
可能看到这还很迷糊。没关系,继续看下面的图。

我们可以看到,排升序的话,使用大堆是非常方便的,我们每次向下调整都可以得到剩余数据的最大值,即堆顶元素。然后放到最后,使用分治的思想,每调整一次,要排序的数据就少一个。当交换到最后一个结点时,数组已经排好序了。
因为是从堆顶选择第一个元素与最后一个元素交换,所以堆排序实质上还是选择排序。
那么有人会疑惑为什么不使用小堆排升序呢?
我们再想想:首先使用堆排序主要是用堆顶元素,如果使用小堆排升序,此时堆顶的元素是最小的,当我们取出堆顶元素时,此时小根堆的性质就变了,那么下次就找不到第二小的元素了,还要重新建堆。所以不能使用小堆排升序。有兴趣的可以自己来画图走一走。
堆排序的代码如下:
void Swap(int *a, int *b)
{int tmp = *a;*a = *b;*b = tmp;
}
//建大堆
void AdjustDown(int arr[], int size, int root){int left = 2 * root + 1;int right = 2 * root + 2;int max;//没有左孩子if (left >= size){return;}//右孩子存在且大于左孩子if (right < size && arr[right] > arr[left]){max = right;}else{max = left;}if (arr[root] >= arr[max]){return;}Swap(arr + root, arr + max);AdjustDown(arr, size, max);
}
void CreateHeap(int arr[], int size){for (int i = (size - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, size, i);}
}
void HeapSort(int arr[], int size){CreateHeap(arr, size);for (int i = 0; i < size; i++){Swap(arr, arr + size - i - 1);AdjustDown(arr, size - i - 1, 0);}
}