残差网络的创建、训练、测试、调参加粗样式
在Keras中实现残差网络模型的创建,并通过模型来实现对图片的分类。
残差网络的预备知识
- 网络越深越好?
随着网络层级的不断增加,模型精度不断得到提升,而当网络层级增加到一定的数目以后,训练精度和测试精度迅速下降,这说明当网络变得很深以后,深度网络就变得更加难以训练了。在不断加神经网络的深度时,模型准确率会先上升然后达到饱和,再持续增加深度时则会导致准确率下降。

- 深层网络的优点与缺点?
- 当使用的深度神经网络层数越来越深,非线性函数的嵌套越来越多,实现的函数越来越复杂,即提取到了更抽象的图像特征(在比较浅的层提取到边缘特征,在深层中提取到了更多复杂的特征),虽然实现了对图片更精确的分类,但与此同时也产生了问题:梯度消失。
- 在深层神经网络中,梯度信号往往会快速降到0,使梯度优化变得很慢。更具体一点,在反向传播过程过程中,每经过一层,梯度就要乘以权重,层数越多,梯度就会议指数级的速度降到0,。或者,另一种情况,梯度爆炸。
- 神经网络在反向传播过程中要不断地传播梯度,而当网络层数加深时,梯度在传播过程中会逐渐消失(假如采用Sigmoid函数,对于幅度为1的信号,每向后传递一层,梯度就衰减为原来的0.25,层数越多,衰减越厉害),导致无法对前面网络层的权重进行有效的调整。
残差网络正是为了解决这个问题。
-
残差网络为什么能解决梯度消失的问题?
-
假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。
-
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好。
-
残差网络的结构

左边是普通的结构,右边是残差网络的结构。

-
在上图的残差网络结构图中,通过“shortcut connections(捷径连接)”的方式,直接把输入x传到输出作为初始结果,输出结果为H(x)=F(x)+x,当F(x)=0时,那么H(x)=x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的残差F(x) := H(x)-x,因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。

经过“shortcut connections(捷径连接)”后,H(x)=F(x)+x,如果F(x)和x的通道相同,则可直接相加,那么通道不同怎么相加呢。上图中的实线、虚线就是为了区分这两种情况的: -
实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是3x3x64的特征图,由于通道相同,所以采用计算方式为H(x)=F(x)+x
-
虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是3x3x64和3x3x128的特征图,通道不同,采用的计算方式为H(x)=F(x)+Wx,其中W是卷积操作,用来调整x维度的。
残差网络的创建
残差网络中使用的标准恒等映射模块:
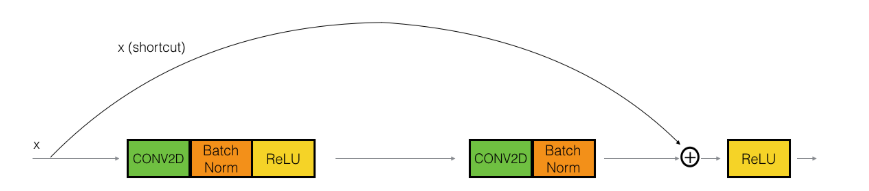
本文使用的恒等映射结构:

路径=主要路径+捷径连接
- 主要路径的第一部分:
- CONV2D:卷积核1x1,步长=1,padding=‘valid’
- BatchNormalization: axis=3,对通道维度做归一化
- 激活函数:ReLU
- 主要路径上的第二部分:
- CONV2D:卷积核fxf,步长=1,padding=‘same’
- BatchNorm: axis=3
- 激活函数:ReLU
- 主要路径上的第三部分:
- CON2D:卷积核1x1,步长=1,padding=‘valid’
- BatchNorm: axis=3
- 注意:这一部分没有激活函数
- 主要路径上的第四部分:
- 捷径连接
- 应用激活函数:ReLU
残差网络恒等映射的代码实现
实用场景:输入与输出能够互相直接相加。捷径部分(输入X)与输出部分(F(X))维度能够匹配,直接相加。
# GRADED FUNCTION: identity_blockdef identity_block(X, f, filters, stage, block):"""Implementation of the identity block as defined in Figure 4Arguments:X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)f -- integer, specifying the shape of the middle CONV's window for the main pathfilters -- python list of integers, defining the number of filters in the CONV layers of the main pathstage -- integer, used to name the layers, depending on their position in the networkblock -- string/character, used to name the layers, depending on their position in the networkReturns:X -- output of the identity block, tensor of shape (n_H, n_W, n_C)"""# defining name basisconv_name_base = 'res' + str(stage) + block + '_branch'bn_name_base = 'bn' + str(stage) + block + '_branch'# Retrieve FiltersF1, F2, F3 = filters# Save the input value. You'll need this later to add back to the main path. X_shortcut = X# First component of main pathX = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)X = Activation('relu')(X)### START CODE HERE #### Second component of main path (≈3 lines)X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name = bn_name_base + '2b')(X)X = Activation('relu')(X)# Third component of main path (≈2 lines)X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X)X = BatchNormalization(axis=3, name = bn_name_base + '2c')(X)# Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)X = layers.add([X, X_shortcut])X = Activation('relu')(X)### END CODE HERE ###return X
测试恒等映射
tf.reset_default_graph()with tf.Session() as test:np.random.seed(1)#tf.placeholder(dtype,shape=None,name=None)A_prev = tf.placeholder("float", [3, 4, 4, 6])X = np.random.randn(3, 4, 4, 6)A = identity_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')test.run(tf.global_variables_initializer())##set_learning_phase() 将学习阶段设置为固定值。参数可以选择0或1。1代表训练集阶段,0代表测试集阶段out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})print("out = " + str(out[0][1][1][0]))
输出:
out = [ 0.94823 -0. 1.1610144 2.747859 -0. 1.36677 ]
残差网络的卷积模块
实用场景:输入与输出维度不匹配,不能够直接相加。解决办法,在捷径X上乘以一个权重,使WX能够与输出的维度匹配。
结构:

路径=捷径连接+主路径
- 主要路径的第一部分:
- CONV2D:卷积核1x1,步长=s,padding=‘valid’,滤波器个数:F1
- BatchNormalization: axis=3,对通道维度做归一化
- 激活函数:ReLU
- 主要路径上的第二部分:
- CONV2D:卷积核fxf,步长=1,padding=‘same’,滤波器个数:F2
- BatchNorm: axis=3
- 激活函数:ReLU
- 主要路径上的第三部分:
- CON2VD:卷积核1x1,步长=1,padding=‘valid’,滤波器个数:F3
- BatchNorm: axis=3
- 注意:这一部分没有激活函数
- 捷径连接:
- CONV2D:卷积核1x1,步长=s,padding=‘valid’,滤波器个数:F3
- BatchNorm: axis=3
- 捷径连接上没有激活函数,恒等映射
捷径连接上使用1x1卷积核,步长s,会使得宽与高缩短s
- 最后一部分:
- 捷径连接+主路径
- 激活函数
代码实现如下:
# GRADED FUNCTION: convolutional_blockdef convolutional_block(X, f, filters, stage, block, s = 2):"""Implementation of the convolutional block as defined in Figure 4Arguments:X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)f -- integer, specifying the shape of the middle CONV's window for the main pathfilters -- python list of integers, defining the number of filters in the CONV layers of the main pathstage -- integer, used to name the layers, depending on their position in the networkblock -- string/character, used to name the layers, depending on their position in the networks -- Integer, specifying the stride to be usedReturns:X -- output of the convolutional block, tensor of shape (n_H, n_W, n_C)"""# defining name basisconv_name_base = 'res' + str(stage) + block + '_branch'bn_name_base = 'bn' + str(stage) + block + '_branch'# Retrieve FiltersF1, F2, F3 = filters# Save the input valueX_shortcut = X##### MAIN PATH ###### First component of main path X = Conv2D(F1, (1, 1), strides = (s,s), name = conv_name_base + '2a', padding='valid', kernel_initializer = glorot_uniform(seed=0))(X)X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)X = Activation('relu')(X)### START CODE HERE #### Second component of main path (≈3 lines)X = Conv2D(F2, (f, f), strides = (1, 1), name = conv_name_base + '2b',padding='same', kernel_initializer = glorot_uniform(seed=0))(X)X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)X = Activation('relu')(X)# Third component of main path (≈2 lines)X = Conv2D(F3, (1, 1), strides = (1, 1), name = conv_name_base + '2c',padding='valid', kernel_initializer = glorot_uniform(seed=0))(X)X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)##### SHORTCUT PATH #### (≈2 lines)X_shortcut = Conv2D(F3, (1, 1), strides = (s, s), name = conv_name_base + '1',padding='valid', kernel_initializer = glorot_uniform(seed=0))(X_shortcut)X_shortcut = BatchNormalization(axis = 3, name = bn_name_base + '1')(X_shortcut)# Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)X = layers.add([X, X_shortcut])X = Activation('relu')(X)### END CODE HERE ###return X
在该部分代码的主要 实现中:需要保证主路径上最后的输出的维度,要与捷径上的维度相一致。主要路径上最后的输出维度的信道数量由最后一步卷积的滤波器数量F3决定。因此对于捷径上,卷积的滤波器数量必须也为F3。输出的第二和第三维度主要由卷积核的大小以及步长决定。
测试输出结果:
tf.reset_default_graph()with tf.Session() as test:np.random.seed(1)A_prev = tf.placeholder("float", [3, 4, 4, 6])X = np.random.randn(3, 4, 4, 6)A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')test.run(tf.global_variables_initializer())out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})print("out = " + str(out[0][1][1][0]))
测试输出为:
out = [ 0.09018461 1.2348979 0.46822017 0.03671762 -0. 0.65516603]
建立一个50层的残差模型
结构

模型结构:
- 补零:对输入进行补零,行和列都加3行和3列0,(3x3)
- 第一部分:
- Conv2D:滤波器数量=64,卷积核=(7x7),步长=(2x2)
- BatchNormaliazation: 对通道进行批量标准化。
- Activation:ReLU
- MaxPooling2D: 卷积核=(2x2),步长=(2x2)
- 第二部分:
- convolutional_block 1个 : 上面创建的函数,如下的结构:
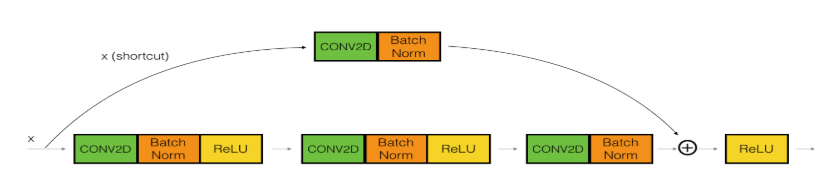
滤波器数量从前到后分别为[64,64,256], f = 3,s = 1
主路径上:
第一个卷积 :(1x1), s = 1, padding = ‘valid’, F1=64
+第二个卷积: (3x3), s = 1, padding = ‘same’, F2=64
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F2=256
捷径上:
卷积:(1x1), s = 1, padding = ‘valid’,F3 = 256 - identity_block 2个 (因为主结构上乘2,因此这里是2个恒等映射块):之前创建的恒等映射结构:

主路径上:
第一个卷积 :(1x1), s = 1, padding = ‘valid’, F1=64
+第二个卷积: (3x3), s = 1, padding = ‘same’, F2=64
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F2=256
捷径上:X
- 第三部分:
- convolutional_block 1个 :
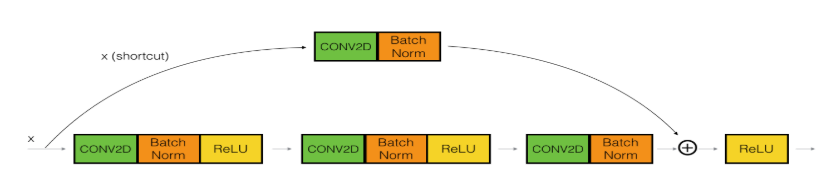
滤波器数量从前到后分别为[128,128,512], f = 3,s = 2
主路径上:
第一个卷积 :(1x1), s = 2, padding = ‘valid’, F1=128
+第二个卷积: (3x3), s = 1, padding = ‘same’, F2=128
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F2=512
捷径上:
卷积:(1x1), s = 2, padding = ‘valid’,F3 = 512 - identity_block 3个 (因为主结构上乘3,因此这里是3个恒等映射块):之前创建的恒等映射结构:

主路径上:
第一个卷积 :(1x1), s = 1, padding = ‘valid’, F1=128
+第二个卷积: (3x3), s = 1, padding = ‘same’, F2=128
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F2=512
捷径上:X
- 第四部分:
- convolutional_block 1个 :
滤波器数量从前到后分别为[256,256,1024], f = 3,s = 2
主路径上:
第一个卷积 :(1x1), s = 2, padding = ‘valid’, F1=256
+第二个卷积: (3x3), s = 1, padding = ‘same’, F2=256
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F2=1024
捷径上:
卷积:(1x1), s = 2, padding = ‘valid’,F3 = 1024 - identity_block 5个 (因为主结构上乘5,因此这里是5个恒等映射块):之前创建的恒等映射结构:
主路径上:
第一个卷积 :(1x1), s = 1, padding = ‘valid’, F1=256
+第二个卷积: (3x3), s = 1, padding = ‘same’,F2=256
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F3=1024
捷径上:X
- 第五部分:
- convolutional_block 1个 :
滤波器数量从前到后分别为[512, 512, 2048], f = 3,s = 2
主路径上:
第一个卷积 :(1x1), s = 2, padding = ‘valid’, F1=512
+第二个卷积: (3x3), s = 1, padding = ‘same’, F2=512
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F2=2048
捷径上:
卷积:(1x1), s = 2, padding = ‘valid’,F3 = 2048 - identity_block 2个 (因为主结构上乘2,因此这里是2个恒等映射块):之前创建的恒等映射结构:
主路径上:
第一个卷积 :(1x1), s = 1, padding = ‘valid’, F1=256
+第二个卷积: (3x3), s = 1, padding = ‘same’,F2=256
+第三个卷积: (1x1), s = 1, padding = ‘valid’, F3=2048
捷径上:X
- 第六部分:
- 池化层AveragePooling2D :(2x2)
- 全连接层Flatten() + Dense() ,全连接层激励函数:Softmax
sigmoid和softmax是神经网络输出层使用的激活函数,分别用于两类判别和多类判别。
binary cross-entropy和categorical cross-entropy是相对应的损失函数。
50层残差网络代码
# GRADED FUNCTION: ResNet50def ResNet50(input_shape = (64, 64, 3), classes = 6):"""Implementation of the popular ResNet50 the following architecture:CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYERArguments:input_shape -- shape of the images of the datasetclasses -- integer, number of classesReturns:model -- a Model() instance in Keras"""# Define the input as a tensor with shape input_shapeX_input = Input(input_shape)# Zero-PaddingX = ZeroPadding2D((3, 3))(X_input)# Stage 1X = Conv2D(64, (7, 7), strides = (2, 2), name = 'conv1', kernel_initializer = glorot_uniform(seed=0))(X)X = BatchNormalization(axis = 3, name = 'bn_conv1')(X)X = Activation('relu')(X)X = MaxPooling2D((3, 3), strides=(2, 2))(X)# Stage 2X = convolutional_block(X, f = 3, filters = [64, 64, 256], stage = 2, block='a', s = 1)X = identity_block(X, 3, [64, 64, 256], stage=2, block='b')X = identity_block(X, 3, [64, 64, 256], stage=2, block='c')### START CODE HERE #### Stage 3 (≈4 lines)# The convolutional block uses three set of filters of size [128,128,512], "f" is 3, "s" is 2 and the block is "a".# The 3 identity blocks use three set of filters of size [128,128,512], "f" is 3 and the blocks are "b", "c" and "d".X = convolutional_block(X, f = 3, filters=[128,128,512], stage = 3, block='a', s = 2)X = identity_block(X, f = 3, filters=[128,128,512], stage= 3, block='b')X = identity_block(X, f = 3, filters=[128,128,512], stage= 3, block='c')X = identity_block(X, f = 3, filters=[128,128,512], stage= 3, block='d')# Stage 4 (≈6 lines)# The convolutional block uses three set of filters of size [256, 256, 1024], "f" is 3, "s" is 2 and the block is "a".# The 5 identity blocks use three set of filters of size [256, 256, 1024], "f" is 3 and the blocks are "b", "c", "d", "e" and "f".X = convolutional_block(X, f = 3, filters=[256, 256, 1024], block='a', stage=4, s = 2)X = identity_block(X, f = 3, filters=[256, 256, 1024], block='b', stage=4)X = identity_block(X, f = 3, filters=[256, 256, 1024], block='c', stage=4)X = identity_block(X, f = 3, filters=[256, 256, 1024], block='d', stage=4)X = identity_block(X, f = 3, filters=[256, 256, 1024], block='e', stage=4)X = identity_block(X, f = 3, filters=[256, 256, 1024], block='f', stage=4)# Stage 5 (≈3 lines)# The convolutional block uses three set of filters of size [512, 512, 2048], "f" is 3, "s" is 2 and the block is "a".# The 2 identity blocks use three set of filters of size [256, 256, 2048], "f" is 3 and the blocks are "b" and "c".X = convolutional_block(X, f = 3, filters=[512, 512, 2048], stage=5, block='a', s = 2)# filters should be [256, 256, 2048], but it fail to be graded. Use [512, 512, 2048] to pass the gradingX = identity_block(X, f = 3, filters=[256, 256, 2048], stage=5, block='b')X = identity_block(X, f = 3, filters=[256, 256, 2048], stage=5, block='c')# AVGPOOL (≈1 line). Use "X = AveragePooling2D(...)(X)"# The 2D Average Pooling uses a window of shape (2,2) and its name is "avg_pool".X = AveragePooling2D(pool_size=(2,2))(X)### END CODE HERE #### output layerX = Flatten()(X)X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X)# Create modelmodel = Model(inputs = X_input, outputs = X, name='ResNet50')return model
分析:
- 实现对图片的多分类,类别数=6,图片输入尺寸是64x64x3
- 结构:CONV2D ->BATCHNORM -> RELU -> MAXPOOL
-> CONVBLOCK -> IDBLOCK2
-> CONVBLOCK -> IDBLOCK3
-> CONVBLOCK -> IDBLOCK5
-> CONVBLOCK -> IDBLOCK2
-> AVGPOOL -> TOPLAYER
调用模型
- 建立模型
model = ResNet50(input_shape = (64, 64, 3), classes = 6)
- 编译模型,设置优化器
model.compile(optimizer=‘adam’, loss=‘categorical_crossentropy’, metrics=[‘accuracy’])
- 载入图像数据(训练集和测试集)
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()# Normalize image vectors
X_train = X_train_orig/255.
X_test = X_test_orig/255.# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).Tprint ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
输出结果:
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
训练集是1080张手指比出0-5的图片,实现对0-5的分类
测试集是120张
- 训练模型
model.fit(X_train, Y_train, epochs = 20, batch_size = 32)
训练结果:
Epoch 1/20
1080/1080 [==============================] - 74s 69ms/step - loss: 2.2709 - acc: 0.4694
Epoch 2/20
1080/1080 [==============================] - 58s 53ms/step - loss: 0.9711 - acc: 0.6963
Epoch 3/20
1080/1080 [==============================] - 56s 52ms/step - loss: 0.6797 - acc: 0.7574
Epoch 4/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.4348 - acc: 0.8546
Epoch 5/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.2945 - acc: 0.8935
Epoch 6/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.1313 - acc: 0.9500
Epoch 7/20
1080/1080 [==============================] - 53s 49ms/step - loss: 0.1155 - acc: 0.9537
Epoch 8/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.1082 - acc: 0.9731
Epoch 9/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.2099 - acc: 0.9343
Epoch 10/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.0725 - acc: 0.9759
Epoch 11/20
1080/1080 [==============================] - 53s 49ms/step - loss: 0.1339 - acc: 0.9583
Epoch 12/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.0562 - acc: 0.9824
Epoch 13/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.0189 - acc: 0.9944
Epoch 14/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.0132 - acc: 0.9944
Epoch 15/20
1080/1080 [==============================] - 53s 49ms/step - loss: 0.0732 - acc: 0.9778
Epoch 16/20
1080/1080 [==============================] - 55s 51ms/step - loss: 0.0494 - acc: 0.9824
Epoch 17/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.0322 - acc: 0.9907
Epoch 18/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.0176 - acc: 0.9926
Epoch 19/20
1080/1080 [==============================] - 55s 51ms/step - loss: 0.0246 - acc: 0.9907
Epoch 20/20
1080/1080 [==============================] - 54s 50ms/step - loss: 0.0451 - acc: 0.9843
训练结果分析:
- 损失函数:起始值比较高,但是从第二次优化开始就大幅度下降,且随着优化次数增多,一直在下降,最终降低到一个比较小的值。
- 准确率:准确率刚开始不是很高,在0.5左右,随着优化的进行,准确率越来越高。
这一次训练采用了20次优化,实际上从这一次训练结果可以看出,没有必要采用这么高的优化次数,由于训练样本的数量比较大,如果训练次数太多,将会导致训练时间大幅度延长,在以后调节参数观察训练结果的时候,需要等待比较长的时间。将优化次数设置的小一点,是比较合理的。
- 测试模型
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
测试结果:
120/120 [==============================] - 5s 38ms/step
Loss = 2.3651149749755858
Test Accuracy = 0.5833333293596904
分析:
- 损失函数:损失函数和训练集相比比较大
- 准确率:处于一半的水准
模型的泛化性能并不好。