Intention Oriented Image Captions with Guiding Objects
原文地址
时间:2019 CVPR
Intro
image caption的过程缺少可控性,一张图片中可以包括很多个目标,但是一个描述只能包括其中一小部分

尽管我们能找到并分类出所有目标,但是我们不能强制语言模型描述我们关心的目标
本文提出了image captions with guiding objects(CGO)模型,CGO模型可以保证用户选择的目标包含在一个caption中,它可以是任何从图片中检测到的目标,即便在训练集中没有遇到过
Approach
给定一张图片,CGO能够将选择的目标融合到生成的句子中,这个过程中,两个LSTM生成目标两侧的文本,一个记为LSTM-L,另一个记为LSTM-R
Problem Formulation
给定图片 I I I,我们想要生成序列 y = ( y 1 , y 2 , . . . , y T ) y=(y_1,y_2,...,y_T) y=(y1,y2,...,yT),词汇表的长度为 V V V,记 θ \theta θ是encoder-decoder的参数,我们的目标是找到最佳的参数,使得
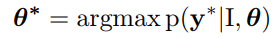
且
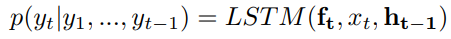
其中 f t f_t ft是图片的特征,在不同模型中的使用方法不同,比如在NIC中,图片特征图 f f f仅仅在time step = 0的时候提供,而使用attention机制的模型会在每一步attend image feature
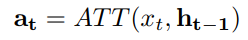
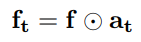
如果我们想要生成包括某个词的序列,则目标序列变成 y = ( y 1 , . . . , y k , . . . , y T ) y=(y1,...,y_k,...,y_T) y=(y1,...,yk,...,yT),其中 y k y_k yk就是想要包括的词,此时的目标为
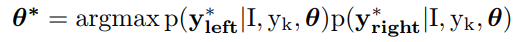
LSTM-L
给定图片 I I I和词 y k y_k yk,LSTM-L生成左边的序列
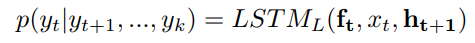
然而这里存在一个问题,因为目标可以在序列的任何位置,比如’there is a banana and an apple on the table’以及’there is an apple and a banana on the table‘,且LSTM-L无法得知右边的序列,如图所示

目标在被描述之前就已经被决定了,就像人类在描述物体前已经得到了物体的大部分信息,因此,我们首先假设有一个集合的目标会出现在描述中,然后设定这些目标的顺序是安排好的,然后我们就可以得到一系列应当出现在右侧序列的目标标签,我们记目标标签为 S = { o b j e c t 1 , . . . , o b j e c t m } S=\{object_1,...,object_m\} S={object1,...,objectm}, S S S中的目标不会出现在LSTM-L生成的序列中,但会影响生成的内容,如上图(b)所示,序列S也作为LSTM-L的输入,现在LSTM-L以图片 I I I,序列 S S S和 y k y_k yk作为输入
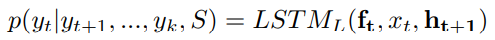
当生成<END>的时候,序列生成结束,句子到达句首,计算损失为
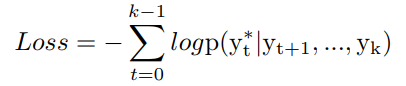
LSTM-R
当左边的序列生成完成后,LSTM-R以LSTM-L的生成结果作为输入,然后完成另一部分的生成,现在模型训练目标为
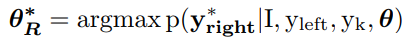
实践中,我们没有将右边的序列当作部分序列来训练,而是使用通常的LSTM误差,两者的区别在于

全序列的误差,可以看作为左边序列长度为0的情况
Novel Word Embedding
CGO中,当一个novel object 被选择为guiding object的时候,我们可以使用另一个见过的与这个object相似的object,可以通过WordNet或者word2vec中word embeeding的距离来选择,传统的image caption中,使用相似的embedding并不能生成novel word,而CGO中的novel word因为不是通过decoder生成的是直接写入句子的,所以能够生成(copy)novel word
Model details
实验中LSTM-R LSTM-L都使用up-down模型
Result


Conclusion
本文提出了CGO来进行object guided image caption,以图片和期望的object词作为输入,模型可以生成包括object的caption,这个过程是由LSTM-L和LSTM-R分别从Object词两边生成句子完成的
问题
本文的生成效果很好,只是反向地生成句子,围绕着词的两侧生成句子是反直觉的