又搬来了来自清华大学与UCLA的工作,提出了一种基于动态token稀疏化的高效视觉transformer,通过分层剪枝66%的输入tokens,可减少31%~37%的FLOPs,并将模型运行速度提高了40%以上,保证精度下降在0.5%以内,可应用于各种视觉 transformer模型中。动态 Token 稀疏化实现高效的视觉 Transformer (来自清华大学,周杰,鲁继文团队,UCLA)50 DynamicViT:动态 Token
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。 这篇文章观察到视觉 Transformer 模型的最终预测结果往往是由一小部分信息量比较大的 tokens 决定的,而大部分的 tokens 其实是冗余的。因此,基于这一观察,本文提出了一种 token 稀疏化的框架,使得视觉 Transformer 模型在前向传播的过程中根据输入图片,动态地识别出冗余的 tokens 并剪掉。通过逐渐地剪掉约 66% 的输入图片的 tokens,DynamicViT 可以在将精度掉点控制在 0.5% 以内的前提下,节约 31%∼37% 的计算量,并提高 40% 以上的吞吐量。
论文地址:https://arxiv.org/pdf/2106.02034.pdf
计算机视觉领域的巨大进步和发展部分原因是以视觉 Transformer 架构为代表的通用视觉模型的发展带来的。视觉 Transformer 已经在目标检测,语义分割等诸多下游任务中取得了广泛的应用。就像针对 CNN 的研究那样,领域也同样致力于 Transformer 类模型加速算法的研究,希望这类模型能够更好地应用在实时移动设备上。之前领域大量研究致力于 CNN 的加速,比如剪掉 CNN 中不太重要的权重。在视觉 Transformer 模型中,我们有一种新的思路。因为 Transformer 将输入图像分割成多个独立的小块 (叫做 Patch 或者 token),这为我们提供了另一种引入稀疏性的正交方法,即我们可以剪掉不重要的 tokens,因为这些冗余的 tokens 对最终模型预测结果的影响很小。
DynamicViT 通过一个极其轻量化的预测模块,来动态地决定哪个 token 应该被剪掉,这个预测模块将被加到 Transformer 模型的多个层里面。对于每个输入图片,预测模块会产生一个针此输入的二进制决策掩码,以决定哪些 tokens 的信息量比较小,需要被剪掉,哪些 tokens 的信息量较大,需要被保留。
如下图1所示,预测模块添加到 Transformer 模型的多个层里面,这样一张输入图片可以在通过模型的过程中,逐渐地减小 tokens 的数量,也就是以一种分层的方式进行稀疏化。一旦一个 token 在某一层之后被剪掉,它就永远不会在模型的前向传播中使用。
虽然在模型中引入了这些额外的预测模块,但是它们所带来的额外计算开销与剪掉冗余 tokens 带来的计算开销的节省相比是相当小的。
预测模块的权重可以随着 Transformer 骨干模型的权重端到端地训练,为此,作者采取了两种专门的策略:
-
采用 Gumbel-Softmax[1] 来克服从分布中采样的不可微问题,从而实现端到端训练。
-
关于如何根据学习到的二进制决策掩码来剪掉冗余的 tokens:对于每个输入图片而言,其二进制决策掩码中0值的位置肯定是不一样的。因此,在训练过程中直接消除每个输入图片的冗余的 tokens 将无法实现并行计算,也无法计算预测模块的反向传播。而且,直接将被剪掉的 tokens 设置为零向量也不可以,因为零向量仍然会影响 Attention 矩阵的计算。
因此,作者提出了一种称为注意力掩码的策略,基于二进制决策掩码把注意力矩阵中被剪掉的 tokens 与其他 tokens 的 attention 丢弃。作者还改了原始的训练目标函数,增加了一项 loss 来限制剪掉 tokens 的比例。
在推断阶段,针对不同的每个输入图片,可以将冗余的 tokens 剪掉,不再需要考虑操作是否可微,这将大大加快模型的推理速度。
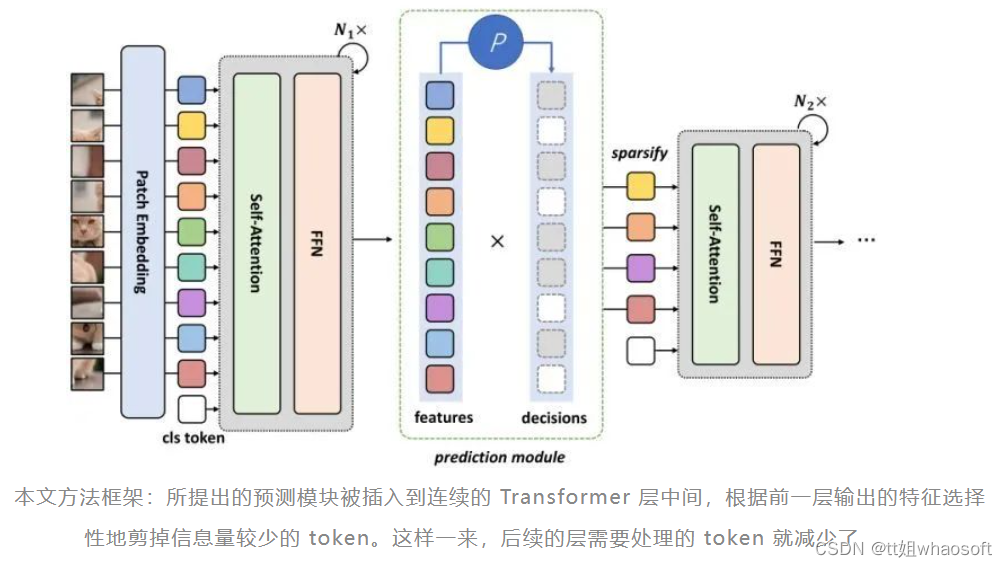 通过预测模块进行 Token 的分层稀疏化
通过预测模块进行 Token 的分层稀疏化
这里 "分层 (Hierarchical)" 的含义是:随着模型的层数由浅到深,token 的数量逐渐减小,即随着计算的进行,逐渐丢弃无信息的 tokens。举个例子:前几层是1000个,中间几层是500个,最后几层只有200个。这个过程是 "分层 (Hierarchical)" 的。
 局部特征编码了某个 token 的信息,而全局特征包含了整个图像的上下文,因此两者都包含了信息。
局部特征编码了某个 token 的信息,而全局特征包含了整个图像的上下文,因此两者都包含了信息。
c) 因此,作者结合局部和全局特征来获得局部-全局嵌入,并将它们输入到另一个 MLP,以预测丢弃/保留 tokens 的概率:

通过注意力掩码进行端到端的训练

 Dynamic ViT 的训练和推理
Dynamic ViT 的训练和推理


实验结果

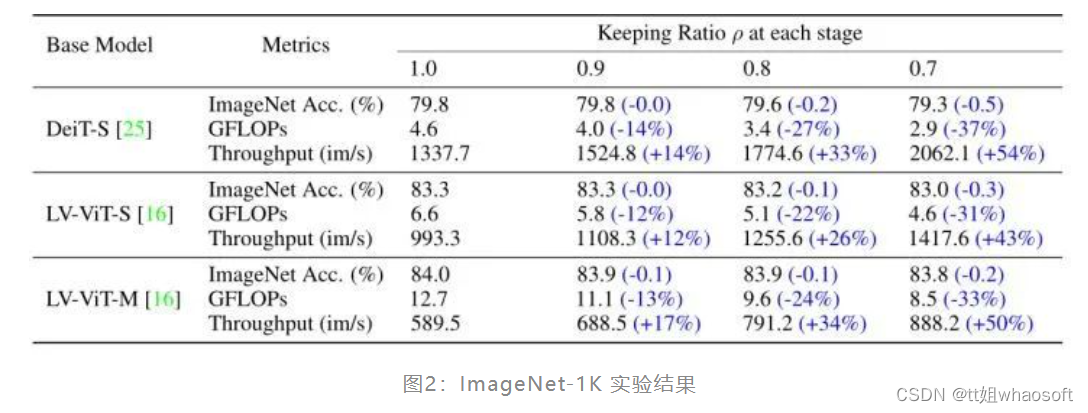
ImageNet-1K 实验结果
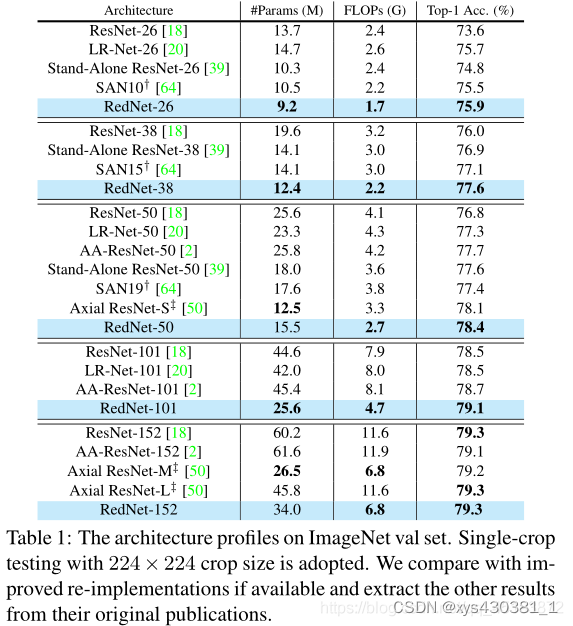
在几种不同的视觉 Transformer 模型的结果如下图1所示。DynamicViT 适用于不同类型的 Transformer 模型中,作者汇报了 ImageNet-1K 精度,计算量和吞吐量 (吞吐量是在单个 NVIDIA RTX 3090 GPU 上测量的,Batch size 固定为32)。DynamicViT 可以减少 31%~37% 的计算成本,并在运行时加速 43%~54% 的推理速度,而性能影响可以忽略 (0.2%~0.5%)。
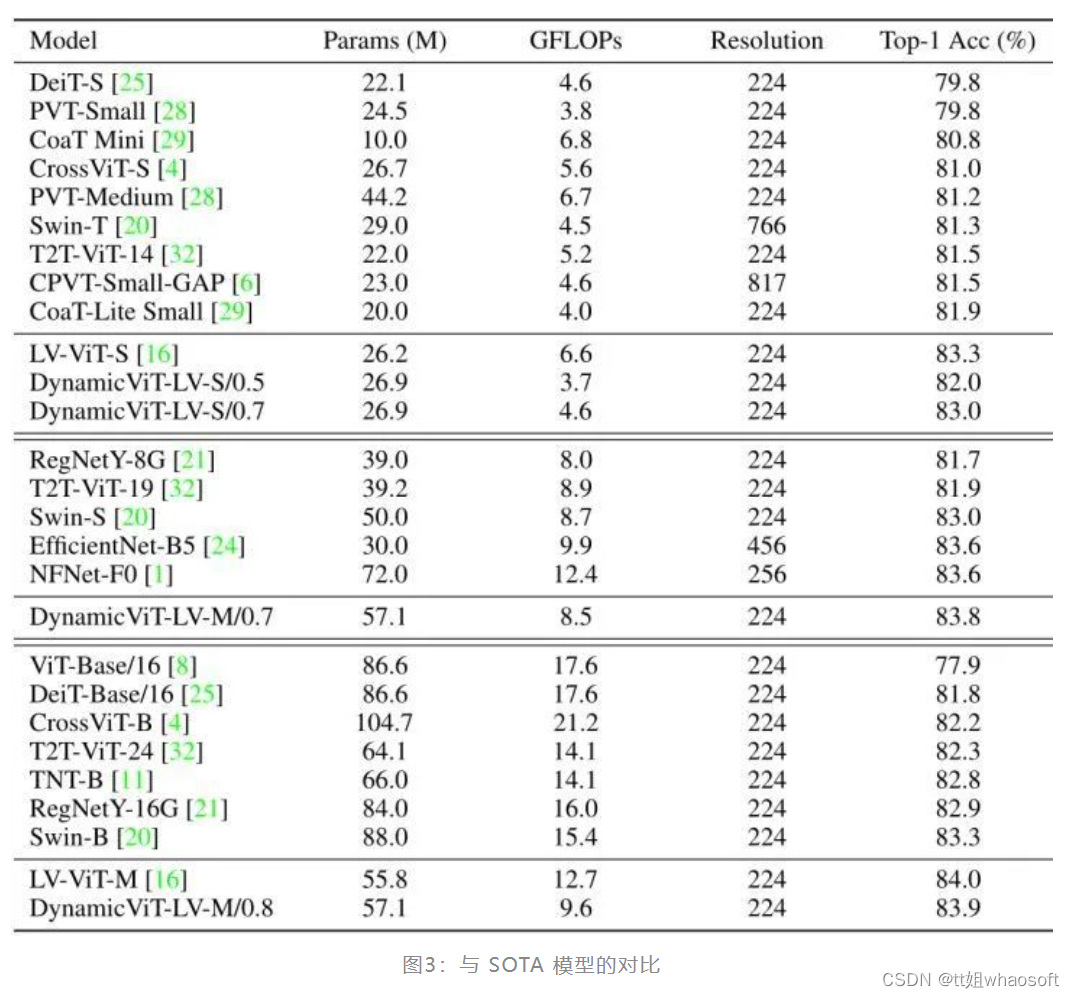
与 SOTA 模型对比
如下图3所示是 DynamicViT 与其他 SOTA 的分类模型对比的结果。可以观察到,DynamicViT 表现出良好的复杂性/精度权衡。值得注意的是 DynamicViT-LV-M/0.7 击败了先进的 CNN 模型 EfficientNet-B5 和 NFNet-F0。 whaosoft aiot http://143ai.com
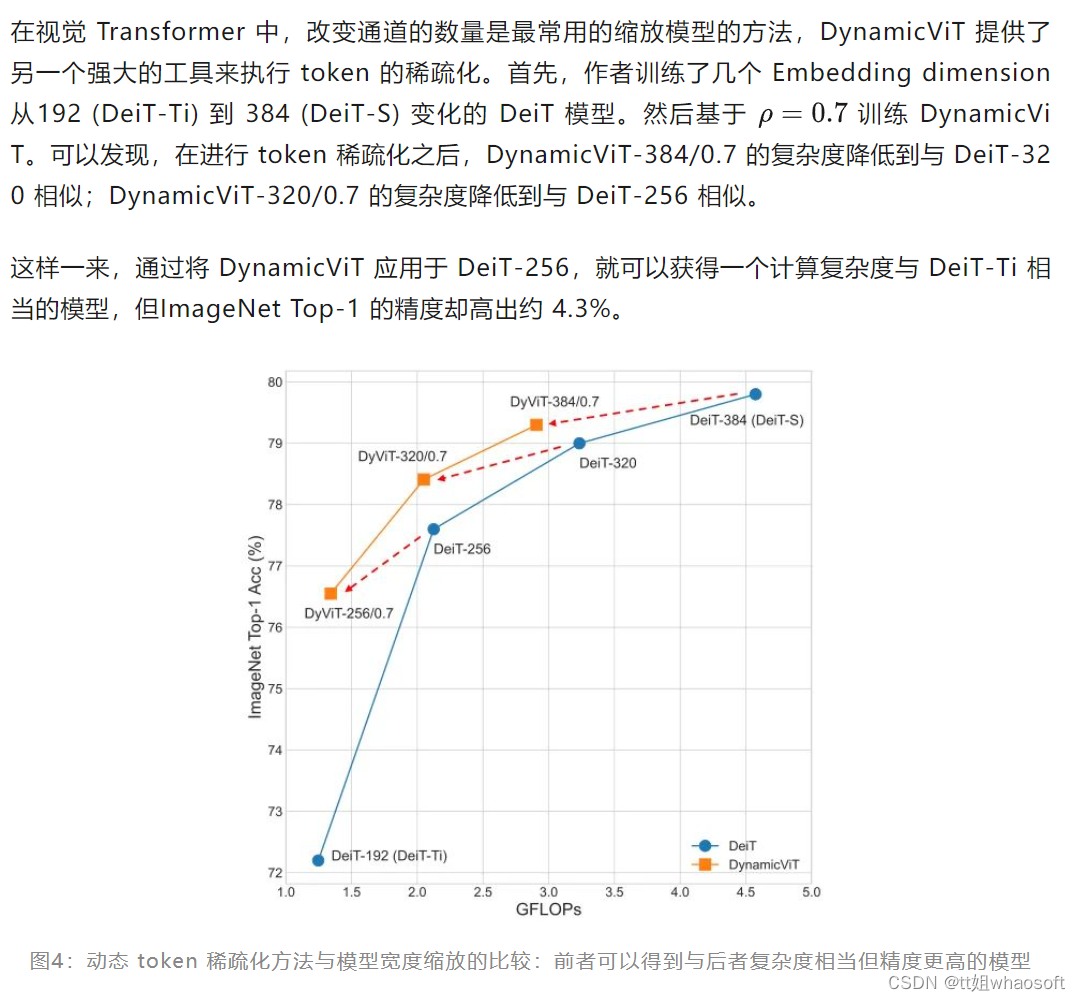
 DynamicViT 用于模型的缩放
DynamicViT 用于模型的缩放
可视化结果
为了进一步观察 DynamicViT 的行为,作者在下图5可视化了稀疏化的过程。图5展示了原始输入图像和3个阶段后的稀疏化结果,其中掩码表示相应的 tokens 被剪掉了。可以观察到每张图片都通过分层的 token 稀疏化,DynamicViT 都会逐渐丢弃掉信息量相对较少的 tokens,最终聚焦于图像中的物体。这一现象还说明,DynamicViT 可以有更好的可解释性,即:它可以定位图像中对分类结果贡献最大的重要部分。
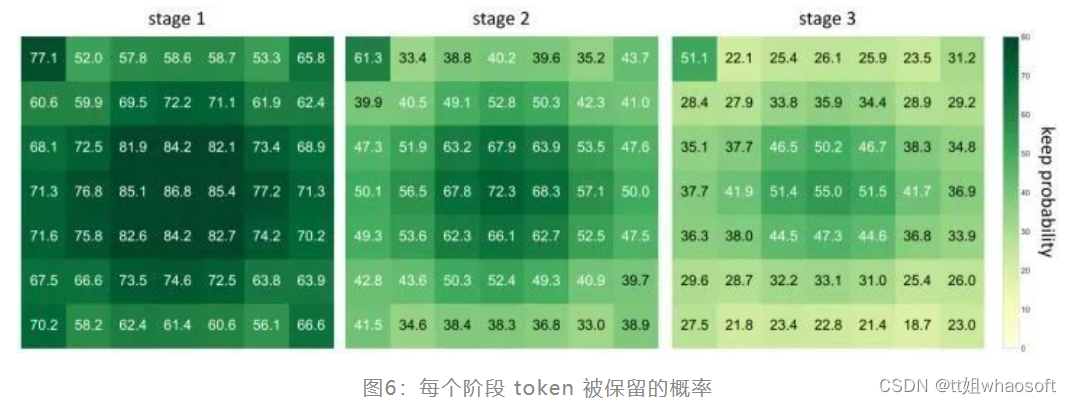
 除了以上不同样本的可视化结果之外,作者还对稀疏化 token 决策的统计特征感兴趣。也就是说,DynamicViT 究竟从数据集学习了什么样一般的模式?作者使用 DynamicViT 为 ImageNet 验证集中的所有图像生成决策,并计算所有3个阶段中每个 token 的保留概率,如图6所示。作者将结果通过 Pooling 操作变成维度是 7×7,使得它们更容易可视化。作者发现图像中间的 tokens 往往被保留,这也是合理的。因为在大多数图像中,物体一般位于图片的中心。
除了以上不同样本的可视化结果之外,作者还对稀疏化 token 决策的统计特征感兴趣。也就是说,DynamicViT 究竟从数据集学习了什么样一般的模式?作者使用 DynamicViT 为 ImageNet 验证集中的所有图像生成决策,并计算所有3个阶段中每个 token 的保留概率,如图6所示。作者将结果通过 Pooling 操作变成维度是 7×7,使得它们更容易可视化。作者发现图像中间的 tokens 往往被保留,这也是合理的。因为在大多数图像中,物体一般位于图片的中心。
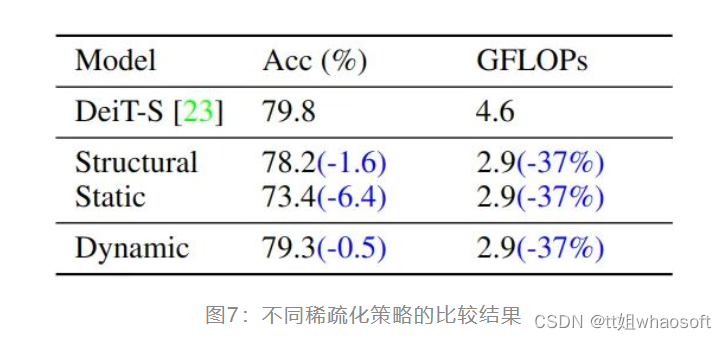
不同稀疏化策略的比较
如下图7所示,为了讨论动态稀疏化是否优于其他的稀疏化策略,作者进行了消融实验,结果如下图7所示。一种方法是结构化下采样 (structural downsampling),这种方法作者使用了一个 2×2 大小的 average pooling,这种方法与 DynamicViT 有类似的 FLOPs。另一种稀疏化的策略是静态 token 稀疏化 (static token sparsification),即稀疏化 token 与输入无关。通过实验可以发现,虽然这三种策略的计算复杂度相似,但 DynamicViT 的精度是最高的。
总结一下哦
DynamicViT 是一种动态 token 稀疏化的框架,使得视觉 Transformer 模型在前向传播的过程中根据输入图片,动态地识别出冗余的 tokens 并剪掉。通过逐渐地剪掉约 66% 的输入图片的 tokens,DynamicViT 可以在将精度掉点控制在 0.5% 以内的前提下,节约 31%∼37% 的计算量,并提高 40% 以上的吞吐量。