IEEE多媒体汇刊Author:Bingjie Xu, Junnan Li, Yongkang Wong
摘要
为了与物体交互,人类会根据自己的意图引导注意力和移动身体。具体而言,提出的human intention-driven的HOI检测(iHOI)框架根据人体关节到物体实例的相关距离进行建模。也会利用人体注视来指示在弱监督情况下的参与上下文区域。除此之外,我们采用了一种hard negative采样策略来处理误分组问题。
1.介绍
以往的工作并没有特别考虑到人类经常表现出有目的的行为,并有意完成任务。在这篇工作中,我们提供了一个新的计算角度来利用两种视觉可见的意图形式:1)明确表达人类意图的human gaze。2)隐式表达人类意图的body posture。
在本文工作中,·我们旨在处理社交场景图片中的HOI精确检测和识别。我们提出了一个由意图驱动的JOI检测框架(iHOI),它由一个目标检测模块和三个分支构成。第一个分支利用独个特征,第二个分支对不同的人-物特征嵌入进行建模,第三个分支使用弱监督下的多注视文本域。人体姿态信息已由人体关节到物体实例的相关距离处理进特征空间中。本文主要贡献为:
(1)探索了如何通过意图来检测和识别社交场景中的HOI,通过gaze和姿态信息来辅助HOI检测。
(2)提出了一个有效的hard negative sample mining策略来处理HOI中误分组的问题。
(3)用切除实验试了一下两个benchmark,达到了SOTA。
2.相关工作
视觉关系检测:Nothing useful!
HOI理解:Nothing useful!
HOI中的gaze:人类注视方向的预测有助于显著性预测。Nothing useful!
3.方法
任务表述如下:给定一个2D图I作为输入,需要检测和识别其中的<人,动作,目标>三元组。
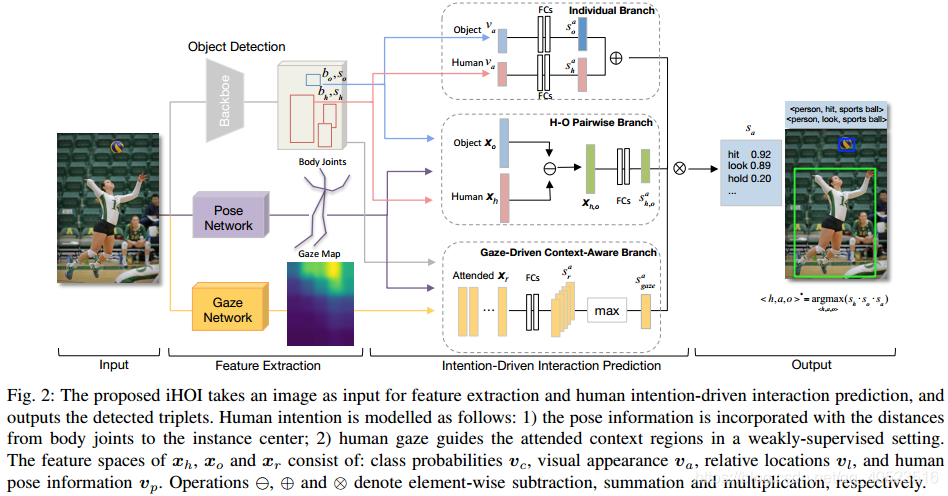
A.模型结构
首先,给定一张输入图片I,我们先使用Detectron中的Faster RCNN来检测所有的人和物,产生一系列检测到的bboxb=(b1,…bm),其中m代表检测实例的总数量。bbox分别为bh和bo,置信分数分别为sh和so。由于我们的目标是对意图建模,而不是提取特征,而且这两个实验数据集都缺乏人体关节的ground-truth,所以人体关节定位和注视方向通过从其他社交动作数据集(openpose)上迁移学习过来的。
第二,我们为每个候选动作预测动作预测分数sa,其中a是给定每个人-物bbox对的动作分类(bh和bo)。sa取决于:(1)基于单个人物外观sah和物体外观sao的动作预测置信,(2)基于人-物pairwise特征表示sah,o的动作预测置信,(3)基于gaze-driven文本表示sagaze的分数预测。形式上,给定bh,bo和各自的sh,so,最大的动作预测分数计算如下:
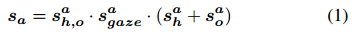
多标签分类使用sigmoid激活函数,使用二进制交叉熵损失进行训练。总的损失函数如下:
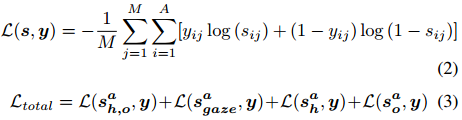
其中L是对M批样本取平均值。对于第j个预测,yij表示第i个动作的二值ground-truth的动作,sij表示sigmoid激活后第i个动作的预测得分。在训练时,由于想最大化每个分支的表现,所以独立训练每个分支。在推理阶段,我们把所有的分支进行融合从而得到最佳总得分。(单独训练为啥还要总loss?)
接下来描述结构的每个组件。
1)人-物pairwise分支:在训练中根据ground-truth人和物是成对的。给定检测到的bh和bo,我们需要学习到保留他们语义交互的成对特征。比如一个骑自行车的人的交互可以通过成对的视觉外观、物体上方的人以及估计的自行车标签来描述。
和最近的用于物体之间视觉关系的VTransE[1]相似,对每个bh和bo的特征空间x都包含了视觉外观,相关的空间布局和物体语义相似性,分别称为va,vl和vc。va是一个2048维的向量,它从目标检测器中的FC7层中提取而来获取每个bo的外观。
vl是一个包含{lx; ly; lw; lh}的四维向量。{lx,ly}指定bbox的坐标距离,{lw,lw}指定log-space里面的高/宽,都是相对于在Faster R-CNN中参数化而言的。vc是一个81维的目标分类器分数向量,由目标检测器产生,维数和MS-COCO中的类别数目一样。
与一般的视觉关系相比,由于我们的任务本质上是以人为中心的,所以我们利用人体姿态信息来扩展特征空间。我们使用2中的姿态估计网络openpose来提取每个人的身体关节位置。该网络的输出是十八个身体关节的位置。我们主要关注其中的(nose, neck, left and right shoulder, left and right elbow, left and right hip)等八个关节。对每个i∈1—8,我们计算他们到bh和bo的中心距离得到两个距离向量{dixh; diyh}和{dixo; diyo}。由于人-物对有不同的尺寸,我们对bh的宽度距离进行归一化。我们把所有八个关节的归一化距离向量进行拼接,得到两个编码了姿态信息的16维向量vhp = {dixh; diyh| i= 1—8} 和 vop ={dixo; diyo| i= 1—8} 。如果没有检测到所有八个关节,我们就将vp设为0。
将上述特征串联起来形成human的特征空间xh={vhc, vha, vhl, vhp}和object的特征空间xo={voc, voa, vol, vop }。计算pairwise特征嵌入3为:
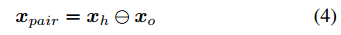
差分嵌入试图将pairwise关系表示为嵌入空间中的一个平移:human + interaction = object。pairwise特征求和也被实验过,但效果较差。pairwise嵌入通过一个FC层产生pairwise动作得分sah,o。
2)单独人和物分支:基于人和物的视觉外观的单独分类经常被别人用且贼jb有用。我们利用人流和对象流分别预测交互。在每个stream中有两个FC层,每个FC后面接一个dropout层。输入是分别为bh和bo提取的视觉外观va。按照后期融合策略,每个信息流先进行动作预测,然后根据人的外观和对象的外观sah,sao进行等比例的元素累加来融合两个预测分数。
3)gaze-driven环境敏感分支:我们观察到,行动者注视的区域通常包含对交互有用的信息。我们使用人类的目光作为引导来利用固定的场景区域。用4中提出的预训练双路径模型来预测被注视位置。只有当可视化区域位于人的眼睛位置和头部方向所定义的直线上时,预测才是合理的。
由于没有注视标签的ground-truth,所以我们做了手工定性检查。在100个随机的凝视预测中,有64个正确的预测,24个错误的预测,还有12个预测无法确定演员的眼睛在图像中看不见的地方,或者演员面对镜头的正面方向。注视预测模型以图像I和人眼中心位置(由姿态估计网络计算得到)为输入,输出注视位置的概率密度图G。
对图片中的每个人,我们从目标检测器产生的候选框b=(b1,……bm)选择五个最可能被注视的区域。对于每个注视区域b,我们给其分配一个注视权重gb,其中gb是将概率密度图G在b中的值相加,然后除以b的面积归一化得到:
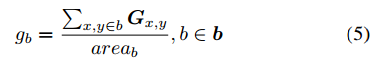
然后选择有最大gb的五个区域r=(r1,……r5)。对于每个选定的区域r,我们首先得到它相应的特征向量xr={vrc, vra, vrl, vrp}。然后送入一个FC层来为每个区域r得到动作分数aar。这个分支的预测分数计算如下:
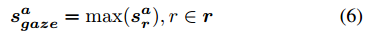
使用max(`)是因为这里人只能注视一个区域。注意如果不能预测gaze(即眼睛在图像中是不可见的,或者行为人面对着摄像机的正面),我们就将xr设为0。
B.困难负样本三元组挖掘
我们观察到误分组是假正HOI检测的常见类型。错误分组指的是HOI的类被正确预测,但是一个错误的对象实例被分配给了参与者(例如一个人正在切另一个人的蛋糕)。我们认为与定位不准确和分类错误的负三元组相比,这种负三元组由于缺少区分模式,使得模型在需要配对建议框的任务中更难处理。
我们提出了一种简单而有效的方法来挖掘这些困难负样本三元组。==对于每一张图像,我们故意从注释中把非交互的人-物对错误分组,并将它们的动作标签设为负值,即全部为零。==这些带负标签的人-物对形成负样本三元组。我们采用以图片为中心的训练策略,其中每个HOI三元组的mini-batch产生一个图像。(这是啥意思?)
C.推理
在推理过程中,我们需要为每个三元组<human,verb,object>计算HOI分数sh,o,a。给定每个人sh和物so的检测分数(直接由目标检测模块产生)和所有动作类别中的最大动作置信分数sa(等式1),sh,o,a = sh × so × sa。对于没有对象物体的动作(run,walk,smile等)直接使用human信息:sh,o,a = sh × sagaze × sah。
为了预测图像中的HOIs,我们必须计算所有检测到的三元组得分。然而在实践中,对每一个潜在的三元组进行评分是难以处理的,这需要高召回率的人-物建议框。为了解决这个问题,我们利用每个动作的预定义相关对象类别c作为先验知识,这是从相应数据集的HOI groundtruth中提取的。比如,物体“球”和动作“踢”相关,但是“书”不相关。与训练中根据ground-truth对人和物体进行配对不同,我们在推理/测试中对每个人-动作对过滤出检测到的与动作无关的物体。然后选择出每个相关类别中三元组分数sh,o,a最大化的物体来形成三元组。但对于HICO-DET,存在许多人与同一类别的多个对象交互的样本(例如一个人放牧多头牛),因此我们最多保留10个对象,对每个人-动作对进行sh,o,a排序。
使用为每个人和动作选择的物体,我们能得到<human,action,object>的三元组。人-物对的bbox,和他们对应的HOI三元组分数sh,o,a是模型的最终输出。
4.实验
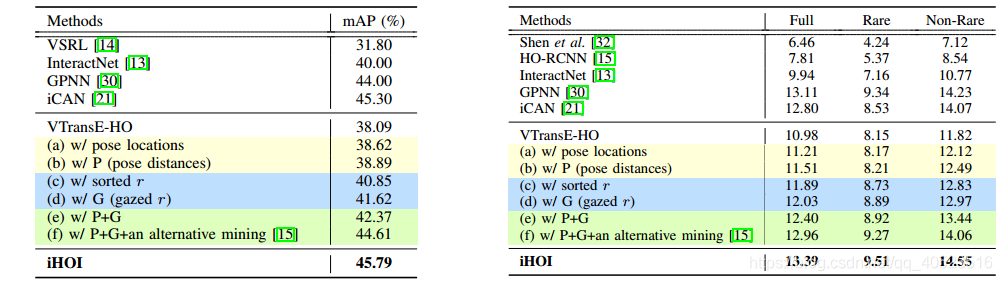

5.总结
1.提出社交场景检测的iHOI模型,通过姿态估计的gaze驱动,探索人的意图。其中姿态估计是通过openpose迁移学习得到的。
2.使用hard negative mining来处理误分组问题。
3.后续还要把gaze和intention在小物体上进行改进。
[1]H. Zhang, Z. Kyaw, S. Chang, and T. Chua, “Visual translation embedding network for visual relation detection,” in CVPR, 2017, pp. 3107–3115
[2]Z. Cao, T. Simon, S. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in CVPR, 2017, pp. 1302–1310
[3]A. Bordes, N. Usunier, A. Garc´ıa-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” in NIPS,2013, pp. 2787–2795
[4]A. Recasens, A. Khosla, C. Vondrick, and A. Torralba, “Where are they looking?” in NIPS, 2015, pp. 199–207