Android 实现音频的裁剪,拼接和混音
基本流程
在项目中我们的音频一般都是指的mp3的文件,mp3文件作为一种编码压缩过的文件格式并不能直接对音频的数据进行很好的操作,我们都知道这种压缩过后的文件播放的时候也必须通过解码器才能播放,而解码出来的原始数据就是pcm数据。pcm数据包含了音频最原始的信息,对实现对pcm数据的处理就能实现对音频的处理。所以对MP3音频流程如下图
pcm文件关键属性
pcm文件有这样几个关键参数,分别是采样率,采样大小,和声道数。这几个指标是十分关键的,我们可以通过他们的乘积得到这段音频的码率,或者通过文件大小除以码率算出这段音频的长度。并且如果要对两端音频进行拼接或混音操作必须保证这几个关键参数的一致,这样才能将两段音频进行处理,当然如果采样率不同怎么办呢?这里就需要SSRC来对采样率进行转换了。我们在实际应用的过程中尽量要避免进行采样率的转换,因为对于现在手机来说,这个过程是十分耗时的。
Android中的解码器
Android系统本身为我们提供了非常好的解码器来对Mp3文件进行解码通过MediaExtractor类和mediaCodec类我们可以进行解码工作。MediaCodec:负责媒体文件的编码和解码工作,内部方法均为native,MediaExtractor:负责将指定类型的媒体文件从文件中找到轨道和媒体信息,并填充到MediaCodec的缓冲区中。
获取关于一个mp3的完整信息
MediaExtractor mediaExtractor = new MediaExtractor();try {mediaExtractor.setDataSource(musicFileUrl);} catch (Exception e) {Log.e(TAG,e.toString());return false;}mediaFormat = mediaExtractor.getTrackFormat(0);//采样率sampleRate = mediaFormat.containsKey(MediaFormat.KEY_SAMPLE_RATE) ?mediaFormat.getInteger(MediaFormat.KEY_SAMPLE_RATE) : 44100;//通道数 channelCount = mediaFormat.containsKey(MediaFormat.KEY_CHANNEL_COUNT) ?mediaFormat.getInteger(MediaFormat.KEY_CHANNEL_COUNT) : 1;//音频长度 duration = mediaFormat.containsKey(MediaFormat.KEY_DURATION) ? mediaFormat.getLong(MediaFormat.KEY_DURATION): 0;//mimemime = mediaFormat.containsKey(MediaFormat.KEY_MIME) ? mediaFormat.getString(MediaFormat.KEY_MIME) : "";try { //得到进行解码的解码器 mediaCodec = MediaCodec.createDecoderByType(mime);mediaCodec.configure(mediaFormat, null, null, 0);} catch (Exception e) {Log.e(TAG,e.toString());return false;}进行解码
MediaFormat outputFormat = mediaCodec.getOutputFormat();MediaCodec.BufferInfo bufferInfo;mediaCodec.start();int byteNumber1 =(outputFormat.containsKey("bit-width") ? outputFormat.getInteger("bit- width"):0) / 8;int byteNumber2 = (outputFormat.containsKey("pcm-encoding") ? outputFormat.getInteger("pcmencoding") :0) / 8;if(byteNumber1 != 0){byteNumber = byteNumber1;} else {byteNumber = byteNumber2;}inputBuffers = mediaCodec.getInputBuffers();outputBuffers = mediaCodec.getOutputBuffers();mediaExtractor.selectTrack(0);bufferInfo = new MediaCodec.BufferInfo();BufferedOutputStream bufferedOutputStream = FileFunction.GetBufferedOutputStreamFromFile(decodeFileUrl);while (!decodeOutputEnd) {if (decodeInputEnd) {break;} inputBufferIndex = mediaCodec.dequeueInputBuffer(timeOutUs); if (inputBufferIndex >= 0) {sourceBuffer = inputBuffers[inputBufferIndex];sampleDataSize = mediaExtractor.readSampleData(sourceBuffer, 0);if (sampleDataSize < 0) {decodeInputEnd = true;sampleDataSize = 0;} else {presentationTimeUs = mediaExtractor.getSampleTime();}mediaCodec.queueInputBuffer(inputBufferIndex, 0, sampleDataSize,presentationTimeUs,decodeInputEnd ? MediaCodec.BUFFER_FLAG_END_OF_STREAM : 0);if (!decodeInputEnd) {mediaExtractor.advance();}}outputBufferIndex = mediaCodec.dequeueOutputBuffer(bufferInfo, timeOutUs);if (outputBufferIndex < 0) {switch (outputBufferIndex) {case MediaCodec.INFO_OUTPUT_BUFFERS_CHANGED:outputBuffers = mediaCodec.getOutputBuffers();break;case MediaCodec.INFO_OUTPUT_FORMAT_CHANGED:outputFormat = mediaCodec.getOutputFormat();if(byteNumber3 != 0){byteNumber = byteNumber3;} else {byteNumber = byteNumber4;}break;default:break;}continue;}targetBuffer = outputBuffers[outputBufferIndex];byte[] sourceByteArray = new byte[bufferInfo.size];targetBuffer.get(sourceByteArray);targetBuffer.clear();mediaCodec.releaseOutputBuffer(outputBufferIndex, false);if ((bufferInfo.flags & MediaCodec.BUFFER_FLAG_END_OF_STREAM) != 0) {decodeOutputEnd = true;}if (sourceByteArray.length > 0 && bufferedOutputStream != null) {if (presentationTimeUs < startMicroseconds) {continue;}byte[] convertByteNumberByteArray = ConvertByteNumber(byteNumber, 2,sourceByteArray);byte[] resultByteArray =ConvertChannelNumber(channelCount,1,2,convertByteNumberByteArray);try {bufferedOutputStream.write(resultByteArray);} catch (Exception e) {Log.e(TAG,e.toString());}}if (presentationTimeUs > endMicroseconds) {break;}} catch (Exception e) {Log.e(TAG,e.toString());}}if (bufferedOutputStream != null) {try {bufferedOutputStream.close();} catch (IOException e) {Log.e(TAG,e.toString());}}//当采样率不是44100的时候通过SSRC将采样率变成一样的if (sampleRate != 44100) {Resample(sampleRate, decodeFileUrl);}if (mediaCodec != null) {mediaCodec.stop();mediaCodec.release();}if (mediaExtractor != null) {mediaExtractor.release();}} pcm的处理
下图是pcm数据的储存
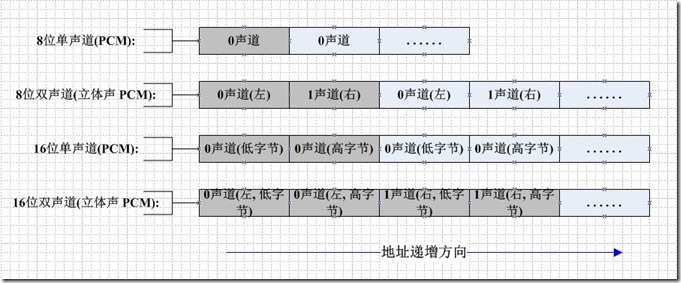
将两个pcm数据进行合并只需将这俩个pcm数据直接连续写入到一个文件中就可以得到一个拼接好的数据。但是这里要注意的是要控制好写入的buffer大小这样才能保证数据写入的速度,这里用的1kb的buffer可以保证非常快的写入速度。
DataInputStream ins1 = new DataInputStream(new BufferedInputStream(new FileInputStream(file1.file)));DataInputStream ins2 = new DataInputStream(new BufferedInputStream(new FileInputStream(file2.file)));DataOutputStream outputStream = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(file)));byte[] bytes = new byte[1024];byte[] bytes2 = new byte[1024];boolean isfinish1= false;boolean isfinish2 = false;while(!isfinish1){int temp = ins1.read(bytes);if(temp <= 0){isfinish1 = true;} else {outputStream.write(bytes);}}while(!isfinish2){int temp = ins2.read(bytes2);if(temp <= 0){isfinish2 = true;} else {outputStream.write(bytes2);}}ins1.close();ins2.close();outputStream.close();裁剪pcm和拼接pcm类似,一个是将两个文件写入一个文件,令一个则是将一个文件中的一段写入另一个新的文件,这里主要的问题是如何确定数据所代表的时间点。这里要通过计算得到开始写入和结束写入的数据位置。通过采样率 声道数 和 bit的数来得到每秒的数据量
下面是裁剪的代码
DataInputStream inputStream = new DataInputStream(new BufferedInputStream(new FileInputStream(source.file)));DataOutputStream outputStream = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(file)));int sum = 0;int audioFormat = 0;if(source.bit_num == 16){audioFormat = AudioFormat.ENCODING_PCM_16BIT;} else {audioFormat = AudioFormat.ENCODING_PCM_8BIT;}int bufferSize = AudioRecord.getMinBufferSize(source.sample_rage_hz,source.channel,audioFormat);byte[] buffer = new byte[bufferSize * 2];int sample = source.getSampleNuit();while(sum < end){inputStream.read(buffer,0,buffer.length);if(sum > start) {outputStream.write(buffer, 0, buffer.length);}sum = (bufferSize * 2 + sum * sample) / sample;}inputStream.close();outputStream.close();混音,对于pcm的混音原理比较简单 就是数据的加和,但是不同加和得到的效果是不一样的。我这里为了减少噪声,减少计算就用了最简单的线性叠加后求平均。就是两个pcm文件对应的数值向加除以2,当然为了可以调节这两个音频声音大小,可以在每个数据之前乘以一个系数。得到如下的公式
当然除了最简单的方法,还有复杂的方法比如归一化混音和重新采样法等。
short[] outPutShortArray = new short[512];byte[] mp3Buffer = new byte[(int)(7200 + (1024 * 1.25))];int firstAudioReadNumber;int secondAudioReadNumber;int outputShortArrayLength = 0;boolean firstAudioFinish = false;while(!firstAudioFinish){secondAudioReadNumber = second.read(secondBuffer);if(secondAudioReadNumber >= 0) {} else {second = new FileInputStream(new File(bg_source));secondBuffer = new byte[1024];second.read(secondBuffer);}firstAudioReadNumber = first.read(firstBuffer);if(firstAudioReadNumber > 0) {outputShortArrayLength = firstAudioReadNumber / 2;for (int index = 0; index < outputShortArrayLength; index++) {outPutShortArray[index] = CommonFunction.WeightShort(firstBuffer[index * 2],firstBuffer[index * 2+1],secondBuffer[index * 2],secondBuffer[index * 2 + 1],source_weight,bg_weight,isbig);}} else if(firstAudioReadNumber < 0){firstAudioFinish =true;}}pcm转换成mp3文件
现在我们有了处理好的pcm,需要将pcm转换成MP3,这个需要用到另一个开源库lame,我们可以很方便的从网站下载到lame的原代码下载地址。
将源码引入到项目,编写一个native-lib.cpp的文件,然后将所以有关的.c文件添加到编译的代码里面中。
add_library(native-libSHAREDsrc/main/cpp/native-lib.cppsrc/main/cpp/bitstream.csrc/main/cpp/encoder.csrc/main/cpp/gain_analysis.csrc/main/cpp/lame.csrc/main/cpp/id3tag.csrc/main/cpp/mpglib_interface.csrc/main/cpp/newmdct.csrc/main/cpp/presets.csrc/main/cpp/psymodel.csrc/main/cpp/quantize.csrc/main/cpp/fft.csrc/main/cpp/quantize_pvt.csrc/main/cpp/reservoir.csrc/main/cpp/set_get.csrc/main/cpp/tables.csrc/main/cpp/takehiro.csrc/main/cpp/util.csrc/main/cpp/vbrquantize.csrc/main/cpp/VbrTag.csrc/main/cpp/version.c)
然后对lame中的代码进行一下小修改
1)删除fft.c文件的47行的”include “vector/lame_intrin.h”“
2)修改set_get.h文件的24行的#include“lame.h”
3)将util.h文件的574行的”extern ieee754_float32_t fast_log2(ieee754_float32_t x);”
替换为 “extern float fast_log2(float x);”
这些跟ndk-builder是一样的,网上有很多教程。
然后,需要修改app -> build.gradle文件
android {
...defaultConfig {...externalNativeBuild{cmake{cFlags "-DSTDC_HEADERS"}}}
}然后进行调用
static lame_global_flags *glf = NULL;extern "C"
JNIEXPORT void JNICALL
Java_audio_jhon_com_myaudio_unit_LameUnit_close(JNIEnv *env, jclass type) {lame_close(glf);glf = NULL;
}extern "C"
JNIEXPORT jint JNICALL
Java_audio_jhon_com_myaudio_unit_LameUnit_flush(JNIEnv *env, jclass type, jbyteArray mp3buf_) {jbyte *mp3buf = env->GetByteArrayElements(mp3buf_, NULL);const jsize mp3buf_size = env->GetArrayLength(mp3buf_);int result = lame_encode_flush(glf, (u_char*)mp3buf, mp3buf_size);env->ReleaseByteArrayElements(mp3buf_, mp3buf, 0);return result;
}extern "C"
JNIEXPORT void JNICALL
Java_audio_jhon_com_myaudio_unit_LameUnit_init__IIIII(JNIEnv *env, jclass type, jint inSampleRate,jint outChannel, jint outSampleRate,jint outBitrate, jint quality) {if(glf != NULL){lame_close(glf);glf = NULL;}glf = lame_init();lame_set_in_samplerate(glf, inSampleRate);lame_set_num_channels(glf, outChannel);lame_set_out_samplerate(glf, outSampleRate);lame_set_brate(glf, outBitrate);lame_set_quality(glf, quality);lame_init_params(glf);
}extern "C"
JNIEXPORT jint JNICALL
Java_audio_jhon_com_myaudio_unit_LameUnit_encode(JNIEnv *env, jclass type, jshortArray buffer_l_,jshortArray buffer_r_, jint samples,jbyteArray mp3buf_) {jshort *buffer_l = env->GetShortArrayElements(buffer_l_, NULL);jshort *buffer_r = env->GetShortArrayElements(buffer_r_, NULL);jbyte *mp3buf = env->GetByteArrayElements(mp3buf_, NULL);const jsize mp3buf_size = env->GetArrayLength(mp3buf_);int result = lame_encode_buffer(glf,buffer_l,buffer_r,samples,(u_char*)mp3buf,mp3buf_size);env->ReleaseShortArrayElements(buffer_l_, buffer_l, 0);env->ReleaseShortArrayElements(buffer_r_, buffer_r, 0);env->ReleaseByteArrayElements(mp3buf_, mp3buf, 0);return result;
}对应的java代码
public class LameUnit {static {System.loadLibrary("native-lib");}public native static void close();public native static int encode(short[] buffer_l, short[] buffer_r, int samples, byte[] mp3buf);public native static int flush(byte[] mp3buf);/***进行初始化传入采样率,和声道数,输出的采样率和码率**/public native static void init(int inSampleRate, int outChannel, int outSampleRate, int outBitrate, int quality);public static void init(int inSampleRate, int outChannel, int outSampleRate, int outBitrate) {init(inSampleRate, outChannel, outSampleRate, outBitrate, 7);}
}LameUnit可以帮助我们将pcm合成的数据转换成经过编码的MP3数据。直接读取pcm的数据然后通过lame进行编码后写入到新的文件里。
boolean isBig = false;if(ByteOrder.nativeOrder() == ByteOrder.BIG_ENDIAN){isBig = true;}LameUnit.init(44100, 1,44100, 128);FileInputStream inputStream = new FileInputStream(in1.file);DataOutputStream outputStream = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(output)));byte[] buffer = new byte[1024];short[] buffer2 = new short[512];byte[] mp3Buffer = new byte[(int)(7200 + (1024 * 1.25))];boolean isFinish =false;while(!isFinish){int num = inputStream.read(buffer);if(num > 0){for(int i = 0;i<(num /2);i++){buffer2[i] = CommonFunction.GetShort(buffer[i*2],buffer[i*2 + 1],isBig);}} else if(num < 0) {isFinish = true;}if(num > 0){int encodedSize = LameUnit.encode(buffer2,buffer2,num / 2,mp3Buffer);if(encodedSize > 0){outputStream.write(mp3Buffer,0,encodedSize);}}}final int flushResult = LameUnit.flush(mp3Buffer);if (flushResult > 0) {outputStream.write(mp3Buffer, 0, flushResult);}inputStream.close();outputStream.close();LameUnit.close();特别注意的问题
1.编码过程中设计了大量二进制文件转换转换成short,或者short转换为二进制,这里设计到一个概念就是内存大小端问题,对于大小端要进行不同的数据转换处理。在Android中我们可以很简单的得到内存是以大端存储还是以小端存储。
boolean isbig = false;if (ByteOrder.nativeOrder() == ByteOrder.BIG_ENDIAN) {isbig = true;} else {isbig = false;}2.关于文件的读写,一定要用有缓存的那个读写方式,并且保证好缓存的大小,太大浪费太小效率又不高。