Lasso简介
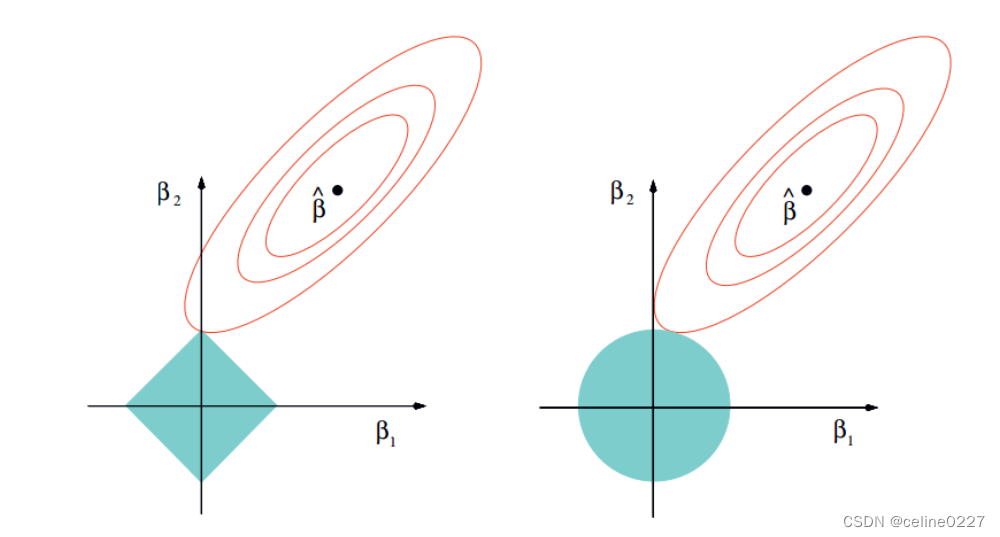
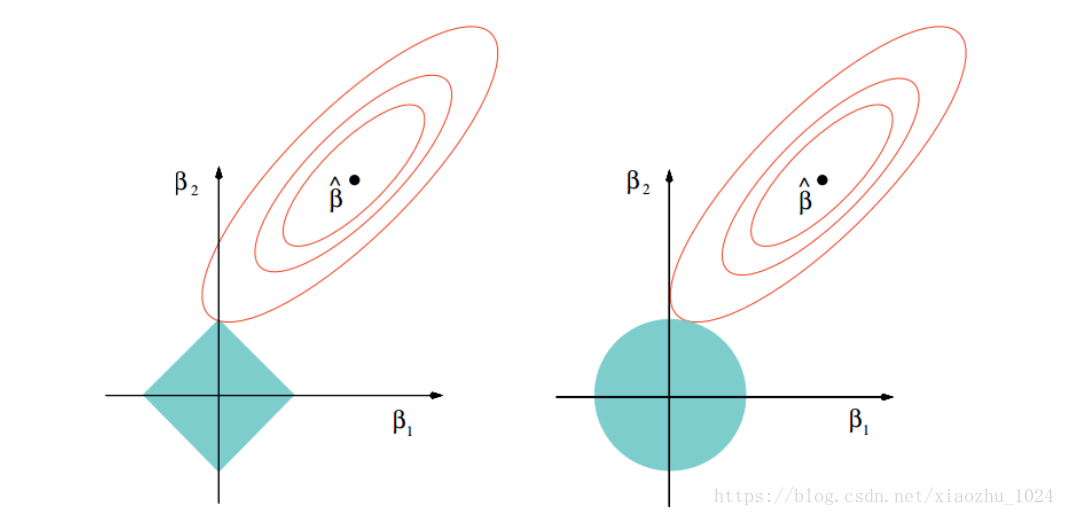
LASSO(Least Absolute Shrinkage and Selection Operator)是线性回归的一种缩减方式,通过引入 L 1 L_1 L1惩罚项,实现变量选择和参数估计。
∑ i = 1 N ( y i − β 0 + ∑ j = 1 p x i j β j ) 2 + λ ∑ j = 1 p ∣ β j ∣ \sum_{i=1}^{N}\left(y_{i}-\beta_{0}+\sum_{j=1}^{p} x_{i j} \beta_{j}\right)^{2}+\lambda \sum_{j=1}^{p}\left|\beta_{j}\right| i=1∑N(yi−β0+j=1∑pxijβj)2+λj=1∑p∣βj∣
R示例
简单的建模过程主要包括:
- 数据切分、清洗
- 建模,使用R的
glmnet包即可实现lasso - 评估,分类常使用混淆矩阵、ROC(使用
ROCR包),数值型预测常使用MAPE
以下用简单的数据集实现Lasso-LR:
这是由真实的医学数据抽样得到的一份demo数据,x1-x19分别代表不同的基因或者染色体表现数据,Y代表病人是否患有某种疾病。(由于数据敏感,因此都用 X i X_i Xi代替。)
rm(list=ls())
library(data.table)
dat_use <- fread('demo_data.csv',header = T)
head(dat_use)# y Genotype Age Gender X1 X2 X3 X4 X5 X6 X7 X8 X9 X10 X11 X12 X13 X14 X15 X16 X17 X18 X19
# 1: 1 0 19 0 2.09 1.85 1.93 5.54 5.08 6.20 8.82 8.19 8.09 4.77 4.53 4.48 3.50 3.23 3.22 0 0 0.46 0.64
# 2: 0 2 20 0 2.54 2.07 1.61 6.19 4.21 0.00 7.53 2.25 1.97 4.41 3.98 3.46 2.49 1.61 1.83 0 1 1.98 5.27
# 3: 1 1 32 1 2.17 2.22 1.95 6.67 5.39 0.00 7.89 5.89 3.00 4.49 2.88 0.03 2.87 2.45 1.23 0 1 1.28 2.00
# 4: 0 1 20 0 2.01 1.68 2.15 6.20 0.00 4.05 7.44 4.60 2.10 4.11 4.28 4.19 2.91 2.08 -0.96 1 0 6.20 2.83
# 5: 1 1 41 1 2.15 1.67 1.56 7.10 0.00 0.00 8.55 3.68 3.40 4.48 3.12 3.26 2.92 1.29 1.36 1 1 7.10 4.87
# 6: 1 1 47 1 1.93 1.62 2.63 6.43 5.21 5.76 8.13 7.95 6.96 4.36 4.47 4.27 2.96 2.52 2.38 0 0 1.22 0.17
数据预处理
首先将类别型变量转为哑变量,借助caret的dummyVars函数可以轻松获取哑变量
library(caret)
# Genotype 为数据中多类型的类别型变量,其他例如Age和Gender为二值0-1变量,无需再转换
# 首先将类别型变量转为facor类型
names_factor <- c('Genotype')
dat_use[, (names_factor) := lapply(.SD, as.factor), .SDcols = names_factor]
# 抽取出类别型变量对应的哑变量矩阵
dummyModel <- dummyVars(~ Genotype,data = dat_use,sep = ".")
dat_dummy <- predict(dummyModel, dat_use)
# 合并哑变量矩阵,并删除对应原始数据列
dat_model <- cbind(dat_use[,-c(names_factor),with=F],dat_dummy)
head(dat_dummy)# Genotype.0 Genotype.1 Genotype.2
# 1 1 0 0
# 2 0 0 1
# 3 0 1 0
# 4 0 1 0
# 5 0 1 0
# 6 0 1 0
切分数据集
# 设置随机数种子,便于结果重现
set.seed(1)
# split data
N <- nrow(dat_model)
test_index <- sample(N,0.3*N)
train_index <- c(1:N)[-test_index]
test_data <- dat_model[test_index,]
train_data <- dat_model[train_index,]
# 指定因变量列,
y_name <- 'y'
thedat <- na.omit(train_data)
y <- c(thedat[,y_name,with=F])[[1]]
x <- thedat[,c(y_name):=NULL]
x <- as.matrix(x)
# normalize(此步骤可省略,因为glmnet默认会标准化后建模,再返回变换后的真实系数)
# pp = preProcess(x,method = c("center", "scale"))
# x <- predict(pp, x)
建模
library(glmnet)
# fit the model
fit <- glmnet(x, y, alpha=1,family = 'binomial')
# 使用area under the ROC curve, CV 选择压缩参数lambda
# 再设置一次set.seed
set.seed(1)
fit_cv <- cv.glmnet(x, y, alpha=1, family = 'binomial', type.measure='auc')
plot(fit_cv)

可以看到压缩到5个变量时AUC最大,对应 l o g ( l a m b d a ) = − 3.67 log(lambda)=-3.67 log(lambda)=−3.67,抽取出对应5个变量的模型系数如下
# log(fit_cv$lambda.min)=-3.67
get_coe <- function(the_fit,the_lamb){Coefficients <- coef(the_fit, s = the_lamb)Active.Index <- which(Coefficients != 0)Active.Coefficients <- Coefficients[Active.Index]re <- data.frame(rownames(Coefficients)[Active.Index],Active.Coefficients)re <- data.table('var_names'=rownames(Coefficients)[Active.Index],'coef'=Active.Coefficients)# 计算系数的指数次方,表示x每变动一个单位对y的影响倍数re$expcoef <- exp(re$coef)return(re[order(expcoef)])
}
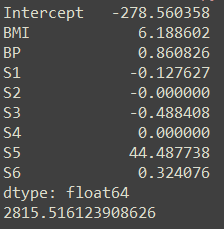
get_coe(fit_cv,fit_cv$lambda.min)# var_names coef expcoef
# 1: (Intercept) -1.12352837 0.3251306
# 2: X16 -0.20444072 0.8151031
# 3: Genotype.0 -0.15247051 0.8585842
# 4: Age 0.02762516 1.0280103
# 5: X14 0.15049722 1.1624121
# 6: X15 0.77624720 2.1733010
但医学上经常需要看每个变量在不同惩罚参数lambda下的压缩程度,从而结合实际背景进一步判别有效的影响因素,因此可借助以下图像进行分析,可以看到x15对y的影响最大(此去省略1000字)
get_plot<- function(the_fit,the_fit_cv,the_lamb,toplot = seq(1,50,2)){Coefficients <- coef(the_fit, s = the_lamb)Active.Index <- which(Coefficients != 0)coeall <- coef(the_fit, s = the_fit_cv$lambda[toplot])coe <- coeall[Active.Index[-1],]ylims=c(-max(abs(coe)),max(abs(coe)))sp <- spline(log(the_fit_cv$lambda[toplot]),coe[1,],n=100)plot(sp,type='l',col =1,lty=1, ylim = ylims,ylab = 'Coefficient', xlab = 'log(lambda)') abline(h=0) for(i in c(2:nrow(coe))){lines(spline(log(the_fit_cv$lambda[toplot]),coe[i,],n=1000),col =i,lty=i)}legend("bottomright",legend=rownames(coe),col=c(1:nrow(coe)),lty=c(1:nrow(coe)),cex=0.5)
}
# 传入最优lambda-1,从而保留更多变量
get_plot(fit,fit_cv,exp(log(fit_cv$lambda.min)-1))

评估
对于分类模型,最常用的评估指标莫过于AUC值了,使用ROCR包可获取AUC值,为了多维度的评估,将混淆矩阵,和各种recall/accuracy指标加入其中。
library(ROCR)
get_confusion_stat <- function(pred,y_real,threshold=0.5){# auctmp <- prediction(as.vector(pred),y_real)auc <- unlist(slot(performance(tmp,'auc'),'y.values'))# statisticpred_new <- as.integer(pred>threshold) tab <- table(pred_new,y_real)if(nrow(tab)==1){print('preds all zero !')return(0)}TP <- tab[2,2]TN <- tab[1,1]FP <- tab[2,1]FN <- tab[1,2]accuracy <- round((TP+TN)/(TP+FN+FP+TN),4)recall_sensitivity <- round(TP/(TP+FN),4)precision <- round(TP/(TP+FP),4)specificity <- round(TN/(TN+FP),4)# 添加,预测的负例占比(业务解释:去除多少的样本,达到多少的recall)neg_rate <- round((TN+FN)/(TP+TN+FP+FN),4)re <- list('AUC' = auc,'Confusion_Matrix'=tab,'Statistics'=data.frame(value=c('accuracy'=accuracy,'recall_sensitivity'=recall_sensitivity,'precision'=precision,'specificity'=specificity,'neg_rate'=neg_rate)))return(re)
}
# 结合数据预处理部分,得到模型在测试集上的表现
get_eval <- function(data,theta=0.5,the_fit=fit,the_lamb=fit_cv$lambda.min){thedat_test <- na.omit(data)y <- c(thedat_test[,y_name,with=F])[[1]]x <- thedat_test[,-c(y_name),with=F]x <- as.matrix(x)pred <- predict(the_fit,newx=x,s=the_lamb,type = 'response')print(get_confusion_stat(pred,y, theta))
}
# get_eval(train_data) 篇幅原因不再展示训练集的拟合效果
get_eval(test_data)
# $AUC
# [1] 0.8406198# $Confusion_Matrix# y_real
# pred_new 0 1# 0 20 8# 1 32 131# $Statistics# value
# accuracy 0.7906
# recall_sensitivity 0.9424
# precision 0.8037
# specificity 0.3846
# neg_rate 0.1466
可以看到模型在测试集上的表选比较不错,AUC值达到0.84,不过在specificity上表现欠佳,说明在负样本上的召回较差(52个负样本,只预测对了20个)。
Tips
本文为博主从自己的github主页复制迁移至此,原文链接在博客 https://hetal-cq.github.io/