Lasso是一种数据降维方法,该方法不仅适用于线性情况,也适用于非线性情况。Lasso是基于惩罚方法对样本数据进行变量选择,通过对原本的系数进行压缩,将原本很小的系数直接压缩至0,从而将这部分系数所对应的变量视为非显著性变量,将不显著的变量直接舍弃。了解Lasso之前我们需要了解的知识
1.1 高维数据
何谓高维数据?高维数据指数据的维度很高,甚至远大于样本量的个数。高维数据的明显的表现是:在空间中数据是非常稀疏的,与空间的维数相比样本量总是显得非常少。在分析高维数据过程中碰到最大的问题就是维数的膨胀,也就是通常所说的“维数灾难”问题。研究表明,随着维数的增长,分析所需的空间样本数会呈指数增长。总体来说有以下特点:
1. 需要更多的样本,样本随着数据维度的增加呈指数型增长;
2. 数据变得更稀疏,导致数据灾难;
3. 在高维数据空间,预测将变得不再容易;
4. 导致模型过拟合。
1.2 过拟合
其实就是所建的机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在验证数据集以及测试数据集中表现不佳。模型过拟合即虽然在训练集上表现得很好,但是在测试集中表现得恰好相反,在性能的角度上讲就是协方差过大(variance is large),同样在测试集上的损失函数(cost function)会表现得很大。
1.3 如何解决过拟合问题?
(1)尽量减少选取变量的数量
可以人工检查每一项变量,并以此来确定哪些变量更为重要,保留那些更为重要的特征变量。这种做法非常有效,但是其缺点是当舍弃一部分特征变量时,也舍弃了问题中的一些信息。例如,所有的特征变量对于预测房价都是有用的,实际上并不想舍弃一些信息或者说舍弃这些特征变量。
(2)正则化
在正则化中将保留所有的特征变量,但是会减小特征变量的数量级。 当有很多特征变量时,其中每一个变量都能对预测产生一点影响。假设在房价预测的例子中,可以有很多特征变量,其中每一个变量都是有用的,因此不希望把任何一个变量删掉,这就导致了正则化概念的发生。
1.4 如何应用正则化去解决实际问题?
目标函数为:
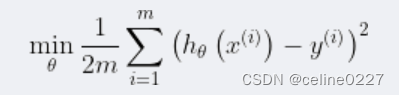
在优化目标的基础上,添加一些项(惩罚项):
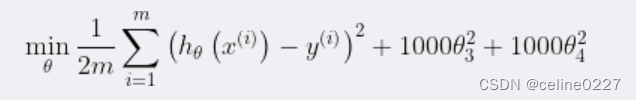
但是在真实问题中,一个预测问题可能有上百种特征,并不知道哪一些是高阶多项式的项,并不知道如何选择关联度更好的参数,如何缩小参数的数目等等。 因此在正则化里,要做的事情,就是减小损失函数中所有的参数值。
因此,我们需要修改代价函数,变成如下形式:
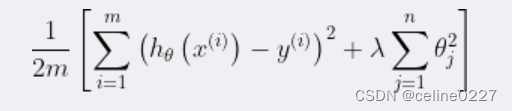
其中![]() 就是正则化项,
就是正则化项,为正则化参数,作用是控平衡拟合训练的目标和保持参数值较小。
二、初识Lasso
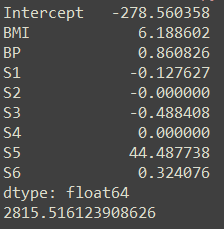
Lasso(Least absolute shrinkage and selection operator)方法是以缩小变量集(降阶)为思想的压缩估计方法。它通过构造一个惩罚函数,可以将变量的系数进行压缩并使某些回归系数变为0,进而达到变量选择的目的。
lasso回归的特色就是在建立广义线型模型的时候,这里广义线型模型包含一维连续因变量、多维连续因变量、非负次数因变量、二元离散因变量、多元离散因变,除此之外,无论因变量是连续的还是离散的,lasso都能处理,总的来说,lasso对于数据的要求是极其低的,所以应用程度较广;除此之外,lasso还能够对变量进行筛选和对模型的复杂程度进行降低。这里的变量筛选是指不把所有的变量都放入模型中进行拟合,而是有选择的把变量放入模型从而得到更好的性能参数。 复杂度调整是指通过一系列参数控制模型的复杂度,从而避免过度拟合(Overfitting)。 对于线性模型来说,复杂度与模型的变量数有直接关系,变量数越多,模型复杂度就越高。 更多的变量在拟合时往往可以给出一个看似更好的模型,但是同时也面临过度拟合的危险。
Lasso回归是在损失函数后,加L1正则化,如下所示: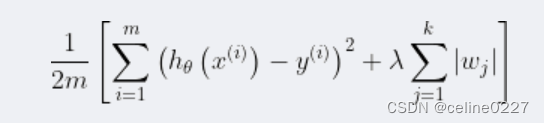
此外:还有L2正则化:![]() ,加了这种正则化的损失函数模型为:脊(岭)回归(Ridge Regression)。
,加了这种正则化的损失函数模型为:脊(岭)回归(Ridge Regression)。
2.1 惩罚函数
这边这个惩罚函数有多种形式,比较常用的有l1,l2,大概有如下几种:
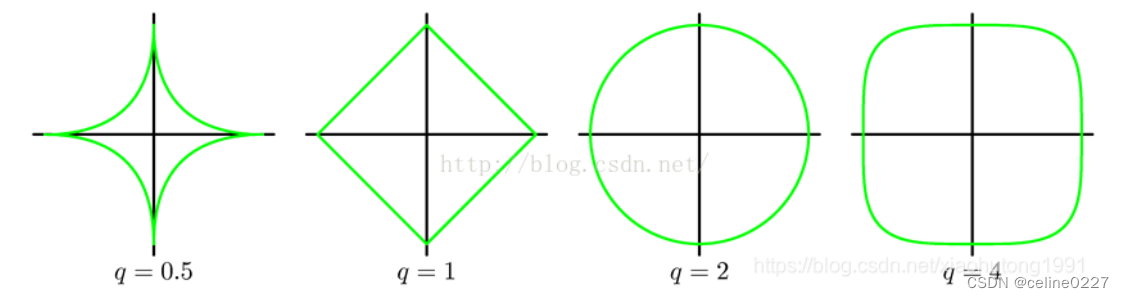
讲一下比较常用的两种情况,q=1和q=2的情况:
q=1,也就是今天想讲的lasso回归,为什么lasso可以控制过拟合呢,因为在数据训练的过程中,可能有几百个,或者几千个变量,再过多的变量衡量目标函数的因变量的时候,可能造成结果的过度解释,而通过q=1下的惩罚函数来限制变量个数的情况,可以优先筛选掉一些不是特别重要的变量,见下图:
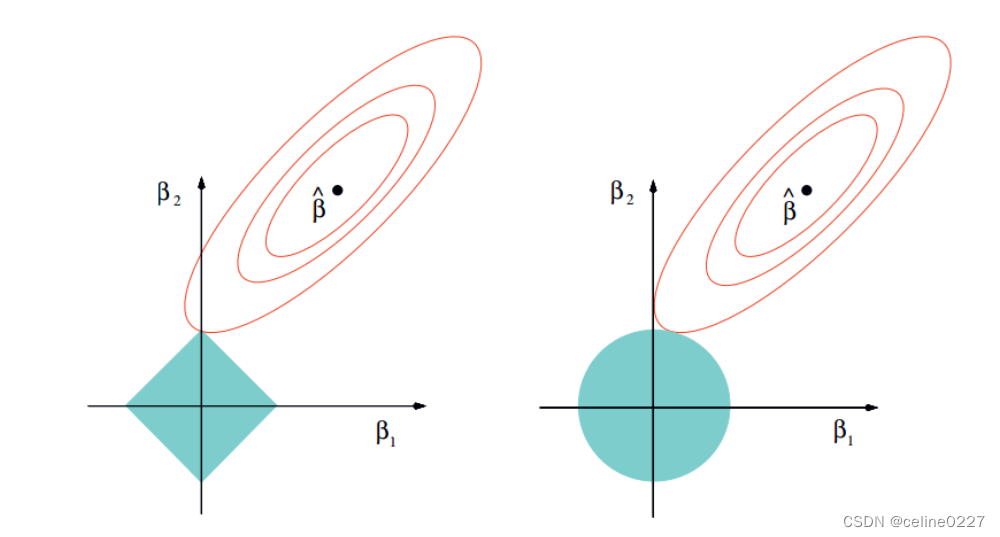
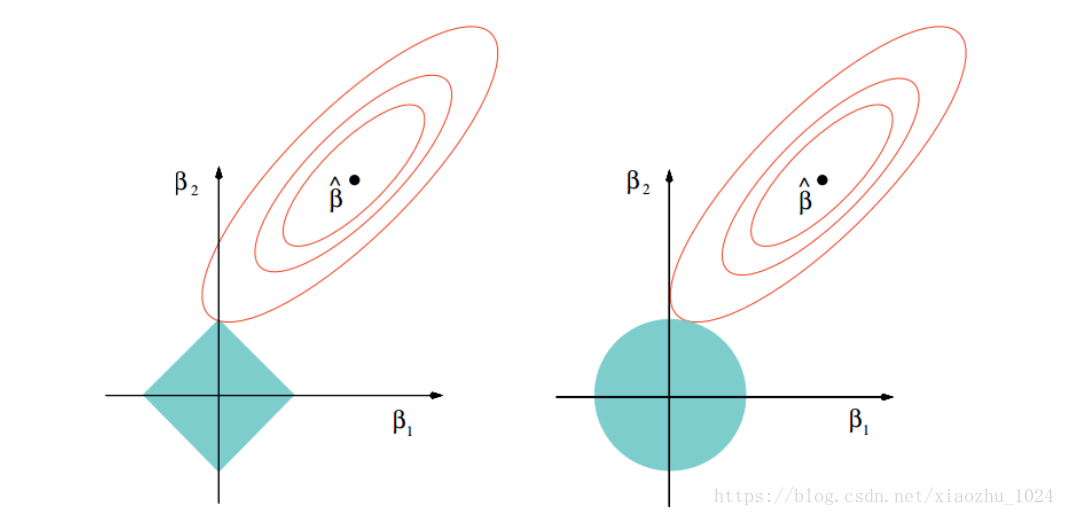
以二维数据空间为例,说明Lasso和Ridge两种方法的差异,左图对应于Lasso方法,右图对应于Ridge方法。
如上图所示,两个图是对应于两种方法的等高线与约束域。红色的椭圆代表的是随着λ的变化所得到的残差平方和,βˆ为椭圆的中心点,为对应普通线性模型的最小二乘估计。左右两个图的区别在于约束域,即对应的蓝色区域。
等高线和约束域的切点就是目标函数的最优解,Ridge方法对应的约束域是圆,其切点只会存在于圆周上,不会与坐标轴相切,则在任一维度上的取值都不为0,因此没有稀疏;对于Lasso方法,其约束域是正方形,会存在与坐标轴的切点,使得部分维度特征权重为0,因此很容易产生稀疏的结果。
所以,Lasso方法可以达到变量选择的效果,将不显著的变量系数压缩至0,而Ridge方法虽然也对原本的系数进行了一定程度的压缩,但是任一系数都不会压缩至0,最终模型保留了所有的变量。
由图也可以看出,Lasso的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。