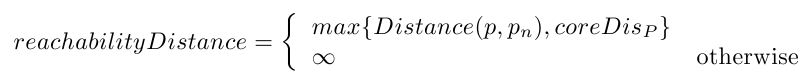前几天写了一篇详解版,感觉可能太详细了阅读量不高,所以修改精简成这篇。
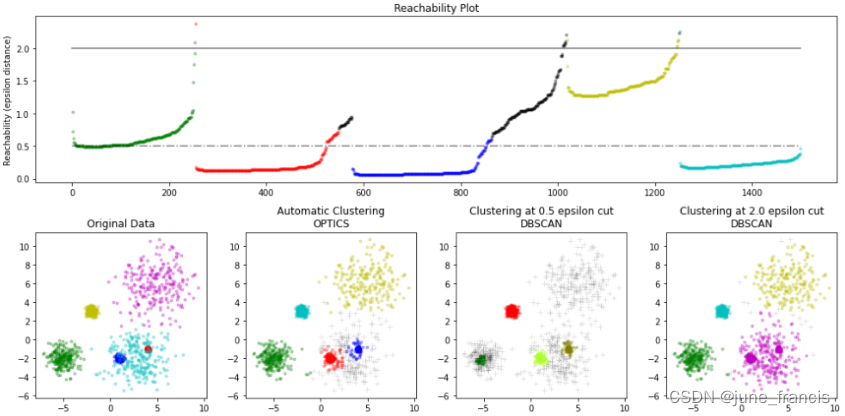
很多人不理解OPTICS算法绘出的图该怎么理解。为什么波谷就算一类,有个波峰又算另一类了,本篇在第三部分的第2、3节详细讲这个是什么判别分类的。
本篇会添加一些个人思考过程,可能有不严谨的地方,希望在评论区讨论指正。
另外,学习本篇,需要有DBSCAN的基础。如果没基础可以先看看这篇《详解DBSCAN聚类》
一、OPTICS重要的新定义
在DBSCAN的基础上,给定 M i n P t s MinPts MinPts 和 e p s eps eps 后,OPTICS又提出了下面几个新定义:
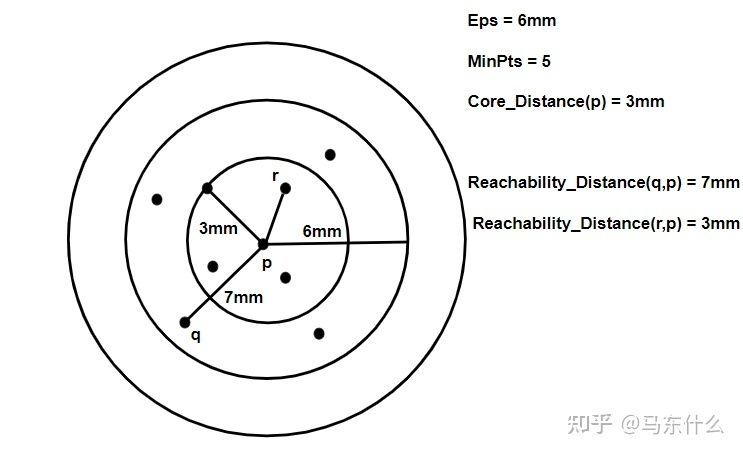
(1)核心距离coreDist:当前核心点 p p p 的邻域中,与核心点 p p p 距离升序排第 M i n P t s − 1 MinPts - 1 MinPts−1位的样本点,与 p p p 的距离作为 p p p 的核心距离(-1是因为邻域包含了p本身)

这里 N ( p ) N(p) N(p)指的是p的邻域点数。
个人理解:因为OPTICS一开始会设定 e p s = i n f eps=inf eps=inf,所以所有点都是核心点,所以 c o r e D i s t ( p ) coreDist(p) coreDist(p)的计算也不需要区分条件 N ( p ) < M i n P t s N(p) < MinPts N(p)<MinPts,除非你数据集的总样本量 < M i n P t s MinPts MinPts
(2)可达距离reach_dist:当前核心点 p p p 下,其他样本点 i i i 到 p p p 的可达距离为 m a x ( i 与 p 间的距离 , p 的核心距离 ) max(i与p间的距离, p的核心距离) max(i与p间的距离,p的核心距离)
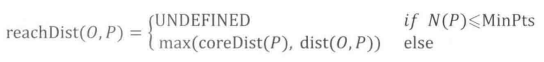
个人理解:同(1)
两种距离的举例如下图所示,图片来自知乎@马东什么,我觉得非常的直观
二、算法流程
先给出简洁的流程,如下。
1、中文描述(最精简)
计算样本点两两距离,填值到 d i s t M a t distMat distMat
全体样本点作为核心点集合 c o r e _ p o i n t s core\_points core_points
计算每个样本点的核心距离 c o r e _ d i s t core\_dist core_dist,方法是取 d i s t M a t distMat distMat每一列升序第 M i n P t s MinPts MinPts的值
数据集中随机选择一个点作为核心点 p p p
计算数据集中其他点 i i i到点 p p p的可达距离 r e a c h _ d i s t [ i ] reach\_dist[i] reach_dist[i],以键值对{ i i i : r e a c h _ d i s t [ i ] reach\_dist[i] reach_dist[i]}存在字典 S e e d s Seeds Seeds中
OK,点 p p p已经用过,不再参与后续任何计算
当 S e e d s Seeds Seeds不空时,循环:
(1) S e e d s Seeds Seeds按值升序排列,取第0个即离上一个核心点最近的点 q q q,作为当前核心点
(2)计算数据集中其他未处理的点 i i i到点 q q q的可达距离 r e a c h _ d i s t [ i ] reach\_dist[i] reach_dist[i],取新旧中的较小值,更新到 S e e d s Seeds Seeds中
(3)OK,点 q q q已经用过,从 S e e d s Seeds Seeds中删除,且不再参与后续任何计算
2、算法流程(精简)
为了更好理解一点,我将通过接近python的伪代码+中文描述来写流程
2.1 初始化:
给定邻域最小样本量MinPts, 数据集D
# OPTICS的半径初始化为inf
eps = inf
# 判断样本是否已处理的列表,初始化为0,表示未处理过,若处理过则为1
processed_list = np.full(shape=(len(D),), fill_value=0)
# 距离矩阵,distMat[i,j]表示样本i与样本j之间的距离
distMat = np.zeros((len(D), len(D)))
# 可达距离的列表,reach_dist[i]表示样本i到当前核心点的可达距离
# 初始为inf而非上面定义所说的undefined是因为好用一个公式计算
# 即 reach_dist[i] = \
# min(max(distMat[i,p],core_dist[p]), 旧reach_dist[i])
reach_dist = np.full(shape=(len(D),), fill_value=inf)
# 结果序列,这里的order并不是指可达距离的升序(虽然有关系),是指处理的顺序
order_list = []
2.2 算法开始
计算样本点两两距离,填值到distMat
全体样本点作为核心点集合core_points
计算每个样本点的核心距离core_dist,方法是取distMat每一列升序第MinPts的值
# 随机选择一个当作当前核心点p
p = core_points[0]
# 获得p周围eps内的邻居点,因eps=inf,实际上就是数据集其他所有样本点
Neighbors_points = getNeighbors(p, eps)
# 标记当前核心点p已处理并放入结果队列
processed_list[p] = 1
ordered_list.append(p)# 字典形式的有序队列,用于升序排列样本点的可达距离
# 键值对是{样本索引i:i到当前核心点p的可达距离}
Seeds = {}
# 更新Seeds中各点到当前核心点的p的可达距离,并升序排序Seeds
# update(Neighbors_points, p, Seeds, core_dist)
############## 第一次update ######################
# 为更直观,不另写一个函数update,而是将update过程直接写在下方
# 遍历核心点p的未处理的邻居
for neigbor in Neighbor_points:if processed_list[neighbor] == 1:continue# 计算p的邻居点neighbor与点p的新可达距离,并取新旧间的最小值reach_dist[neighbor] = \min(max(distMat[neighbor,p],core_dist[p]), reach_dist[neighbor])# 在有序队列中添加or更新键值对,此处的update是字典内置方法Seeds.update({neighbor:reach_dist[neighbor]})
############## 第一次update结束 ####################### 再按Seeds顺序遍历
# 提醒一下,Seeds现在是p的未处理过的邻居,也即数据集中未处理过的样本
while len(Seeds)!=0:# 取离p最近的那个点,即Seeds中按可达距离升序排列后的第0个样本q = sorted(Seeds.items(), key=operator.itemgetter(1))[0][0] del Seeds[q]# 标记当前核心点q已处理并放入结果队列processed_list[q] = 1ordered_list.append(q)Neighbors_of_q = getNeighbors(q, eps)# 更新Seeds中各点到当前核心点q的可达距离,并升序排序Seeds# update(Neighbor_of_q, q, Seeds, core_dist)############ 第二次update ############## 为更直观,不另写一个函数update,而是将update过程直接写在下方# 遍历核心点q的未处理的邻居for neigbor in Neighbor_of_q:if processed_list[neighbor] == 1:continue# 计算q的邻居点neighbor与点q的新可达距离,并取新旧间的最小值reach_dist[neighbor] = \min(max(distMat[neighbor,q],core_dist[q]), reach_dist[neighbor])# 在有序队列中添加or更新键值对,此处的update是字典内置方法Seeds.update({neighbor:reach_dist[neighbor]})############# 第二次update结束 ##########
三、一个简单的例子,讲述算法流程
1、例子来源:《机器学习笔记(十一)聚类算法OPTICS原理和实践》
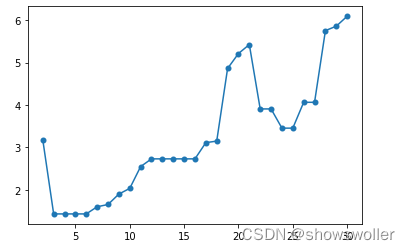
已知样本数据集为: D = [ 1 , 2 ] , [ 2 , 5 ] , [ 8 , 7 ] , [ 3 , 6 ] , [ 8 , 8 ] , [ 7 , 3 ] , [ 4 , 5 ] D = {[1, 2], [2, 5], [8, 7], [3, 6], [8, 8], [7, 3], [4,5]} D=[1,2],[2,5],[8,7],[3,6],[8,8],[7,3],[4,5],坐标轴上分布如下,我已经用黄色圆圈序号标明其在样本中的索引。
设定 e p s = i n f eps=inf eps=inf, M i n P t s = 2 MinPts=2 MinPts=2,
先计算了 d i s t M a t distMat distMat, c o r e _ d i s t core\_dist core_dist。
初始化 r e a c h _ d i s t reach\_dist reach_dist全 i n f inf inf,
记录了每一步处理的核心对象(核心点),并及时在 p r o c e s s e d _ l i s t processed\_list processed_list标记为已处理
可以看到 S e e d s Seeds Seeds的更新、 S e e d s Seeds Seeds的排序、选新的核心对象计算可达距离 是交替进行的
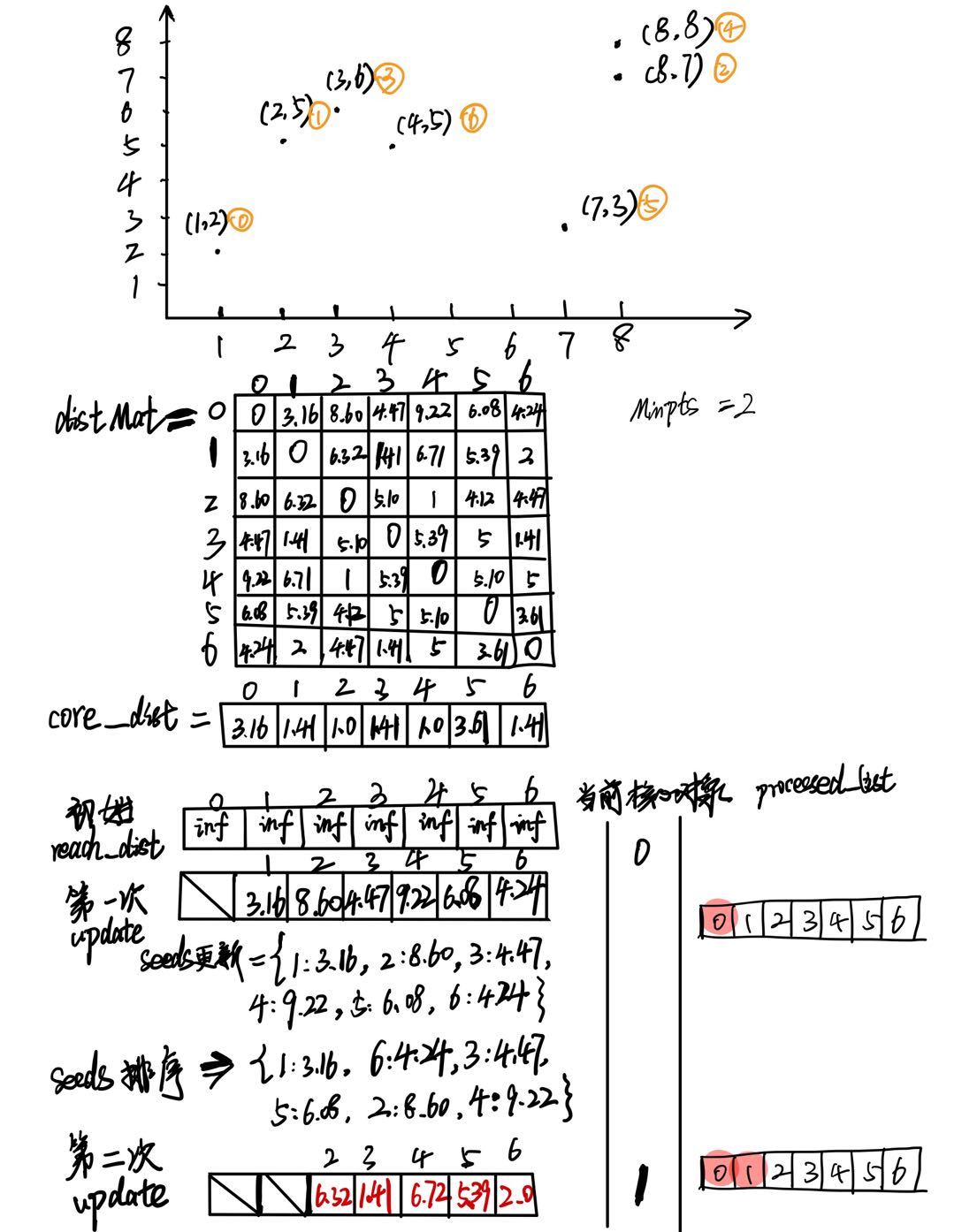
第一次update只是针对第一个选中的核心点,所以只有一次。
第二次update是 S e e d s Seeds Seeds不空的循环,会一直到结束(当 S e e d s Seeds Seeds为空)
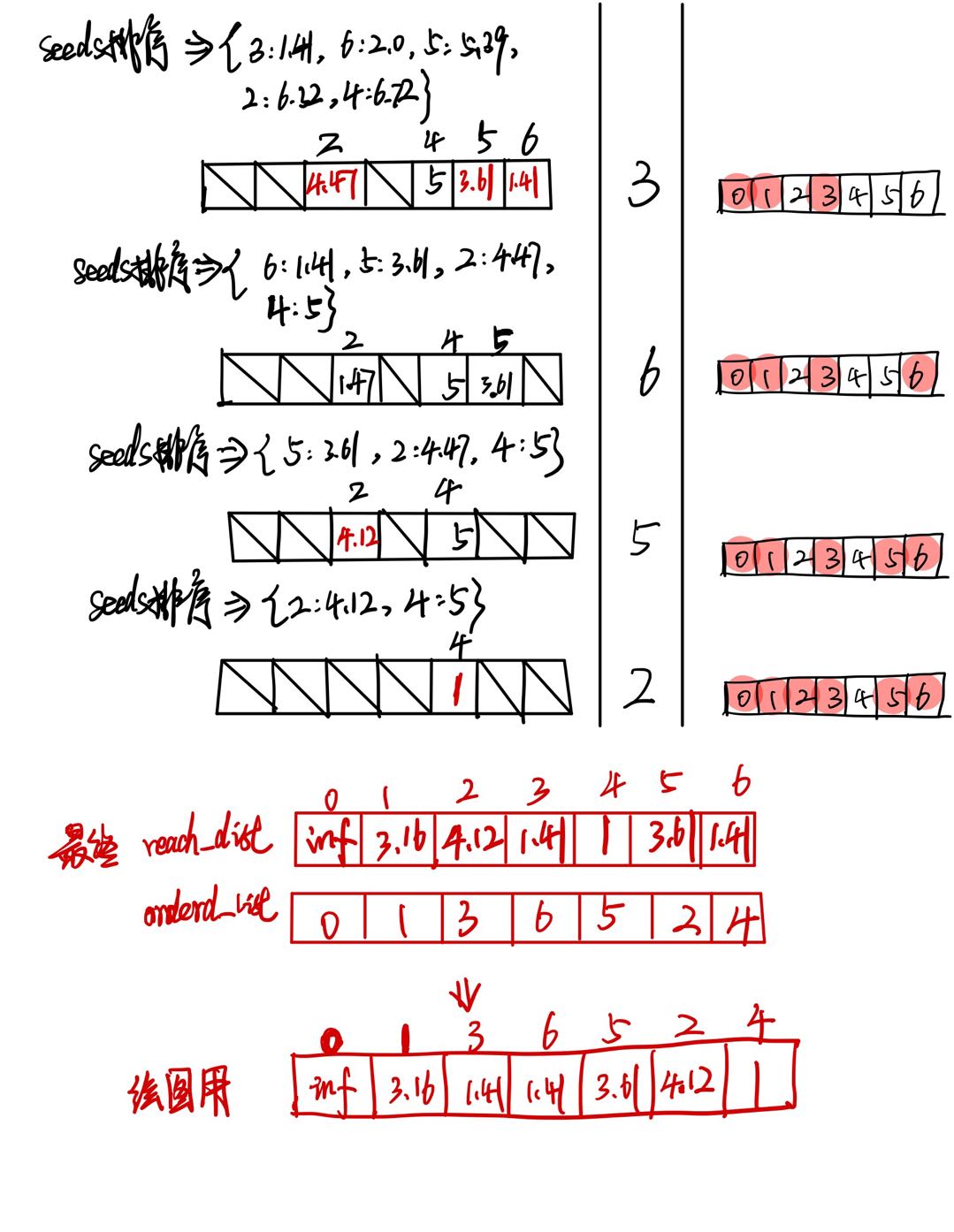
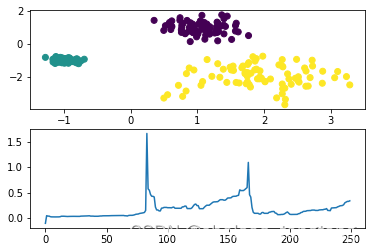
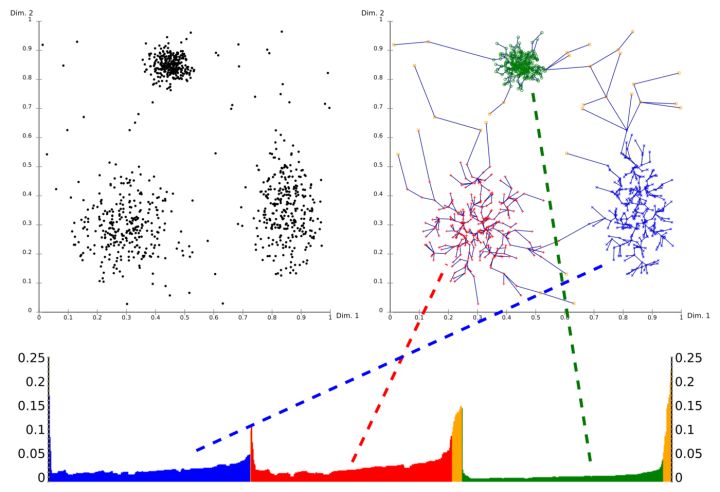
最终的 r e a c h _ d i s t reach\_dist reach_dist 是按照样本顺序给出的, o r d e r e d _ l i s t ordered\_list ordered_list 是按照核心点的处理顺序的(也与可达距离有关),为了绘图,我们需要将 r e a c h _ l i s t reach\_list reach_list 按照 o r d e r e d _ l i s t ordered\_list ordered_list 的顺序重排列。如上图。
然后,再用这个重排列的数据绘图如下。
2、重点来了!如何理解这张 r e a c h _ d i s t — p o i n t s reach\_dist—points reach_dist—points图并实现分类
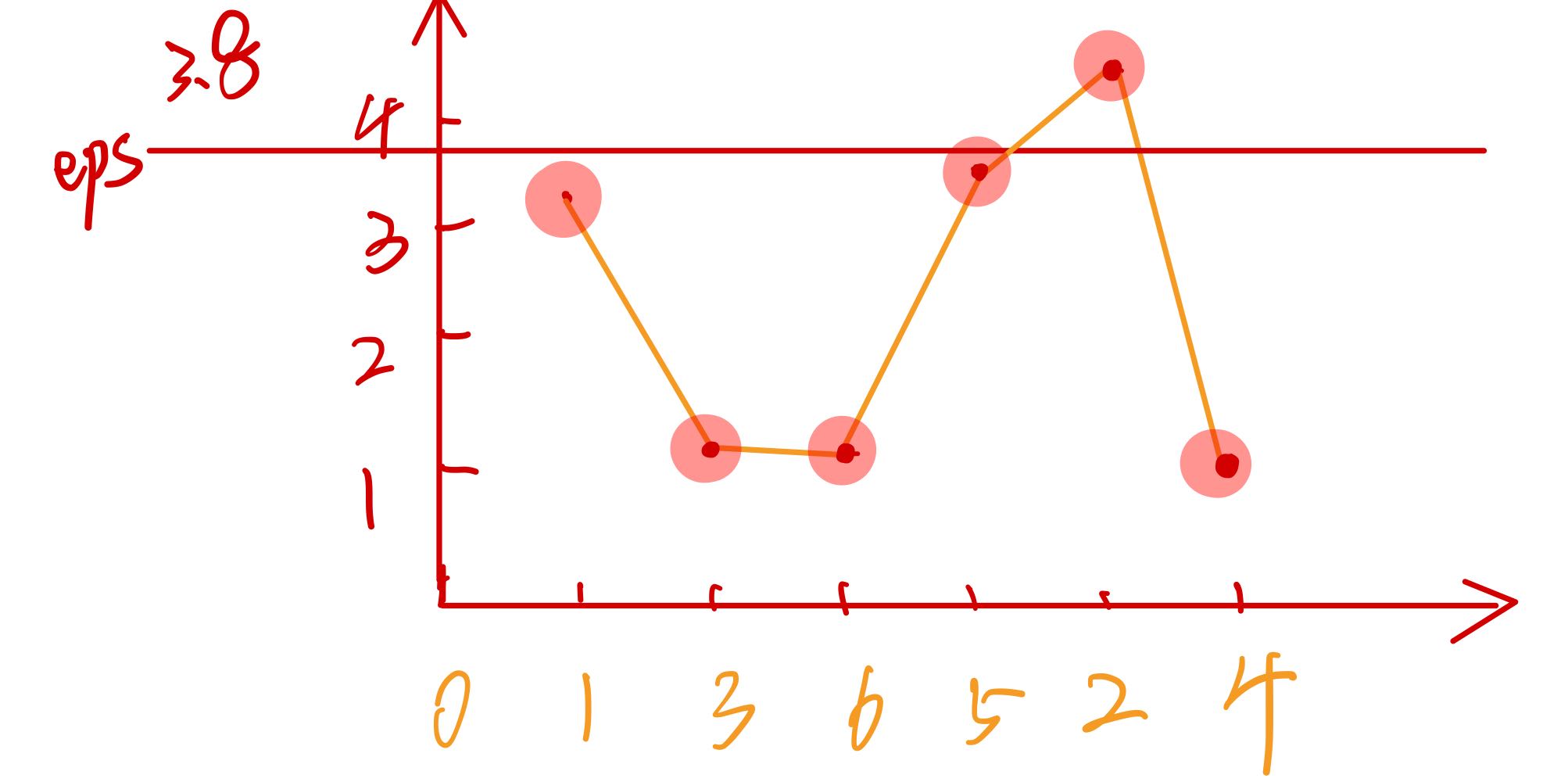
假设 e p s = 3.8 eps=3.8 eps=3.8
(1)首先,样本点0,值为 i n f inf inf不用绘制出来,因为 r e a c h _ d i s t reach\_dist reach_dist 的原始定义其实应该是全 u n d e f i n e d undefined undefined 而不是 i n f inf inf,未定义的值当然不用绘制了
(2)然后,样本点1,显然离样本点0的可达距离 < eps,那么归到与样本点0一类是没有问题的
(3)然后,样本点3,显然离样本点1的可达距离 < eps,那么归到与样本点0一类是没有问题的。
如果你是这样想就错了!
只是就本例的数据集来说,确实可以看出3到1更近。
从更广义的样本来说,样本点3离样本0和1谁更近是不知道的,即 r e a c h _ d i s t ( 3 , 0 ) reach\_dist(3,0) reach_dist(3,0)与 r e a c h _ d i s t ( 3 , 1 ) reach\_dist(3,1) reach_dist(3,1)谁小不知道,可以举例为:
样本点1到核心点0的 r e a c h _ d i s t ( 1 , 0 ) = 3.16 reach\_dist(1,0) = 3.16 reach_dist(1,0)=3.16 <
样本点3到核心点0的 r e a c h _ d i s t ( 3 , 0 ) = 3.3 reach\_dist(3,0) = 3.3 reach_dist(3,0)=3.3 <
样本点3到核心点1的 r e a c h _ d i s t ( 3 , 1 ) = 3.5 reach\_dist(3,1) = 3.5 reach_dist(3,1)=3.5
这样的话就是样本点3到核心点0的距离更近,也满足这样的 o r d e r e d _ l i s t ordered\_list ordered_list 顺序0->1->3
所以:我们可以发现这样的一个规律:
1与前面的集合{0}中的某点可达距离最近为3.16
3与前面的集合{0,1}中的某点可达距离最近为1.41
6与前面的集合{0,1,3}中的某点可达距离最近为1.41
5与前面的集合{0,1,3,6}中的某点可达距离最近为3.61
(4)对于样本点2,为什么就要归入第二类呢?因为
2与前面的集合{0,1,3,6,5}中的某点可达距离最近为4.12 > eps,所以分在第一类已经不合适了,又因为核心距离 c o r e _ d i s t [ 2 ] = 1.0 < e p s core\_dist[2]=1.0<eps core_dist[2]=1.0<eps,所以归入第二类
(5)对于样本点4,可达距离小于eps,为什么也要归入第二类呢?因为
4与前面的集合{0,1,3,6,5,2}中的某点可达距离最近为1,
但是显然,样本点4不能与前面{0,1,3,6,5}的可达距离,必然比样本点2与前面的可达距离还要远(否则在 o r d e r _ l i s t order\_list order_list 中样本点4应该排在2前面)
4与前面的集合中的可达距离最近为1,还得是靠样本点2才能这么小。所以样本点4与归入2所在的第二类。
3、总结一下根据 r e a c h _ d i s t — p o i n t s reach\_dist—points reach_dist—points图如何定义簇
(可惜上面的例子没有噪声点样本。)
注意此时eps已不再是inf,而是依据图自定义的。
从结果队列 o r d e r _ l i s t order\_list order_list 按顺序取出样本点,直到结果队列为空:
若该点的可达距离 <= eps,则属于当前聚类簇
否则:若该点的核心距离 > eps,为噪声点
若该点的核心距离 < eps,为新的聚类簇
四、numpy实现的代码
参考:武大博士的知乎——《聚类算法之OPTICS算法》
其他参考链接:
三、3、定义簇部分 ——《dbscan和optics(完结撒花~)》
二、1、算法流程(最精简)部分—— ——曾依灵, 许洪波, 白硕. 改进的OPTICS算法及其在文本聚类中的应用[C]// 全国信息检索与内容安全学术会议. 2007:51-55.