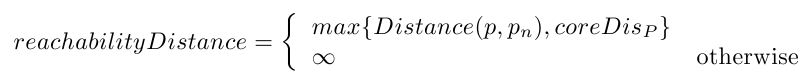1 简介
随着数据爆发式增长,分析数据从而提取隐藏在数据中的信息变的越来越重要。聚类分析是数据分析的一个主要方法,聚类(clustering)是将数据对象进行分类的过程,使同一类中的对象之间具有很高的相似度,而不同类中的对象高度相异。与分类不同,聚类不依赖预先定义的类和类标号,属于观察式学习。简而言之,在聚类中,分类的标准和类型数量均是未知的。
近来聚类分析算法得到了相当多的关注。传统的聚类分析算法存在三个问题。第一,需要输入参数,并且输入参数难以获取。第二,算法对输入参数特别敏感,设置的细微不同可能导致差别很大的聚类。第三,高维数据集常常具有非常倾斜的分布,全局密度参数不能刻画内置的聚类结构。
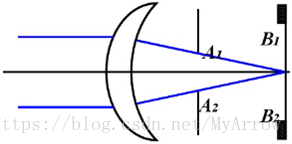
如图1所示,我们不能依靠一个唯一的密度参数同时识别A B C1 C2和C3。我们只能同时识别{A,B,C}或者{C1,C2,C3}。在第二种情况下,A和B中的对象都被认为是噪声。
为了解决上述问题,我们提出一种新聚类算法,即OPTICS算法,OPTICS是ordering point to idenfy the cluster structure缩写。OPTICS算法不显示地产生数据聚类,它只是对数据对象集中的对象进行排序,输出一个有序的对象列表(cluster-ordering)。cluser-ordering包含了足够的信息用来提取聚类,即对对象进行分类。和传统的聚类算法相比,OPTICS算法的最大优点是对输入参数不敏感。
2 基本概念
【定义0】
给定对象半径ε内的邻域称为该对象的ε邻域。
如果对象的ε邻域至少包含最小数据MinPts的对象,则该对象称为核心对象。
【定义1】p到q直接密度可达
1) p到q的距离小于ε。
2) p的ε邻域内的对象的数量 ≥ MinPts。满足此条件的对象称为核心对象。
【定义2】p到q密度可达
存在p1, ..., pn, p1 = p, pn = q,其中pi到pi+1是直接密度可到。
【定义3】p和q密度相通
存在一个对象o,p和q都是从o密度可达的。
【定义4】聚类和噪声  ,
, , C是一个聚类如果满足如下条件:
, C是一个聚类如果满足如下条件:
1) 最大化  ,如果
,如果 且p到q密度可达,则
且p到q密度可达,则 。
。
2) 连通性  ,则p到q是密度相通的。
,则p到q是密度相通的。
噪声:不属于任何聚类的对象。
【定义5】对象p的核心距离 
【定义6】可达距离 
3 OPTCIS算法
OPTICS算法生成一个有序对象列表,每个对象拥有两个属性,核心距离和可达距离。利用这个列表,可以获得任何领域半径小于 的聚类。
的聚类。
/*
*功能:对数据集合SetOfObjects中的对象进行排序
*输入参数
*@SetOfObjects 待分析的数据集合
*@ε 邻域半径
*@MinPts 若对象的ε 邻域内的对象数量>=MinPts,则此对象为核心对象
*输出参数
*@OrderedFile 已经排好序的对象列表
*/
OPTICS (SetOfObjects, ?, MinPts, OrderedFile)OrderedFile.open();FOR i FROM 1 TO SetOfObjects.size DOObject := SetOfObjects.get(i);IF NOT Object.Processed THENExpandClusterOrder(SetOfObjects, Object, ?,MinPts, OrderedFile)OrderedFile.close();
END; // OPTICSExpandClusterOrder(SetOfObjects, Object, ?, MinPts,OrderedFile);neighbors := SetOfObjects.neighbors(Object, ?);Object.Processed := TRUE;Object.reachability_distance := UNDEFINED;Object.setCoreDistance(neighbors,??, MinPts);OrderedFile.write(Object);IF Object.core_distance <> UNDEFINED THEN//OrderSeeds是优先级队列,可达距离越小,优先级越高OrderSeeds := NULL;UpdateSeeds(OrderSeeds, neighbors, Object);WHILE NOT OrderSeeds.empty() DO currentObject := OrderSeeds.next();neighbors:=SetOfObjects.neighbors(currentObject, ?);currentObject.Processed := TRUE;currentObject.setCoreDistance(neighbors, ?, MinPts);OrderedFile.write(currentObject);IF currentObject.core_distance<>UNDEFINED THENUpdateSeeds(OrderSeeds, neighbors, currentObject);
END; // ExpandClusterOrderUpdateSeeds(OrderSeeds,neighbors,coreObject)for(n:neighbors)if n.Processedcontinue;iNewReachDistacnce := reachability_distance between coreObject with nif n.reachability_distance == UNDEFINEDn.reachability_distance = iNewReachDistacnce;OrderSeeds.insert(n);else if iNewReachDistacnce < n.reachability_distanceOrderSeeds.remove(n);n.reachability_distance = iNewReachDistacnce;OrderSeeds.insert(n);
END; //UpdateSeeds上面的算法是有bug的。假如:D={ b,e,f,g,a,c,d} ,其中a是核心对象,b/c/d到a的欧几里得距离均为,e/f/g均为噪声,e到b的欧几里得距离小于,如果按照上述的算法输出可能为b,e,a,c,d,f,g,这显然是错误的。下面是我改进后的算法:
---------------------------------------------------------------------START-----------------------------------------------------------------
ExpandClusterOrder(SetOfObjects, Object,?, MinPts,OrderedFile);
neighbors := SetOfObjects.neighbors(Object,?);
Object.reachability_distance := UNDEFINED;
Object.setCoreDistance(neighbors,??, MinPts);
IF Object.core_distance <> UNDEFINED THEN//只处理核心对象
Object.Processed := TRUE;
OrderedFile.write(Object);
OrderSeeds.update(neighbors, Object);
WHILE NOT OrderSeeds.empty() DO//可达距离小的对象优先处理
currentObject := OrderSeeds.next();
neighbors:=SetOfObjects.neighbors(currentObject,?);
currentObject.Processed := TRUE;
currentObject.setCoreDistance(neighbors,?, MinPts);
OrderedFile.write(currentObject);
IF currentObject.core_distance<>UNDEFINED THEN
OrderSeeds.update(neighbors, currentObject);
END; // ExpandClusterOrder
---------------------------------------------------------------------END-----------------------------------------------------------------
如下算法是从OPTICS算法输出的有序列表中获取聚类的算法,结果与DBSCAN算法是一样的。
---------------------------------------------------------------------END-----------------------------------------------------------------
/*
*功能:从OPTICS输出的有序列表中,抽取聚类
*@ClusterOrderedObjs OPTICS输出的有序列表
*@?'?'??
*@MinPts与OPTICS算法中的值相等
*/
// Precondition: ?' ??generating dist??for ClusterOrderedObjs
ExtractDBSCAN-Clustering (ClusterOrderedObjs,?', MinPts)
ClusterId := NOISE;
FOR i FROM 1 TO ClusterOrderedObjs.size DO
Object := ClusterOrderedObjs.get(i);
IF Object.reachability_distance???' THEN
// UNDEFINED >?
IF Object.core_distance???' THEN
ClusterId := nextId(ClusterId);
Object.clusterId := ClusterId;
ELSE
Object.clusterId := NOISE;//本对象不输入任何聚类,是噪声
ELSE // Object.reachability_distance???'
Object.clusterId := ClusterId;
END; // ExtractDBSCAN-Clustering
---------------------------------------------------------------------END-----------------------------------------------------------------
4 图形化和输入参数
4.1 图形化
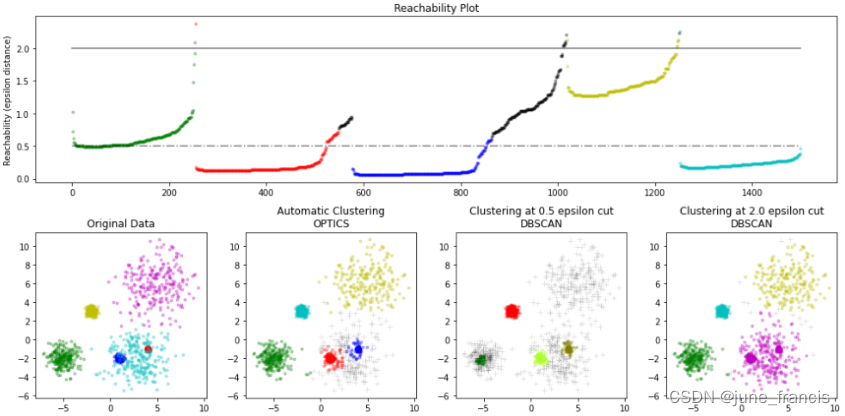
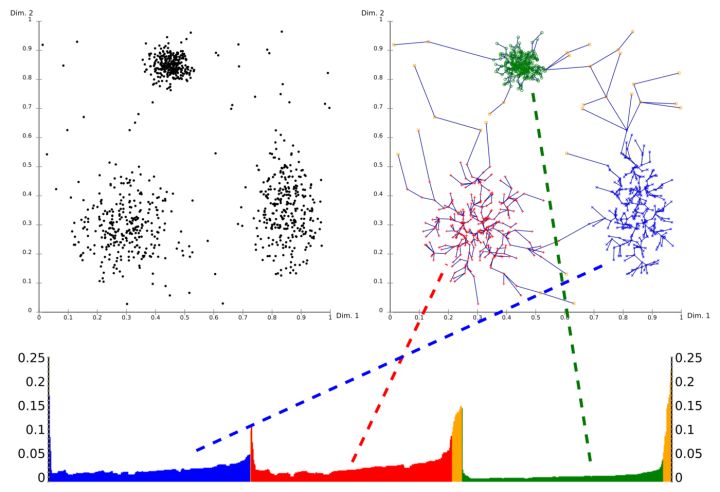
可达距离曲线非常直观的呈现了对象的分布,见图9。 图9和图10中的3个曲线基于同一数据集,但是输入参数不同,我们可以直观的看到3个图的形状基本相同。由此可见,可达距离曲线对输入参数和MinPts不敏感。


4.2输入参数
【的选取】
越小,可达距离为undefined的对象越多,即忽略了低密度的聚类。下面是确定的方法之一。虽然OPTICS算法不敏感,我们还是需要输入参数,该如何确定?
我们可以假设集合D中对象是均匀分布,d表示集合D的维度数量, 表示D的容积,若d为2,表示面积,若d为3,表示体积;N表示D中对象的数量。
表示D的容积,若d为2,表示面积,若d为3,表示体积;N表示D中对象的数量。

其中:
【MinPts的选取】
MinPts越小,图形越呈锯齿状;反之,图形越光滑。MinPts的经验值是10到20。
5 获取nature聚类
5.1 聚类与可达距离曲线
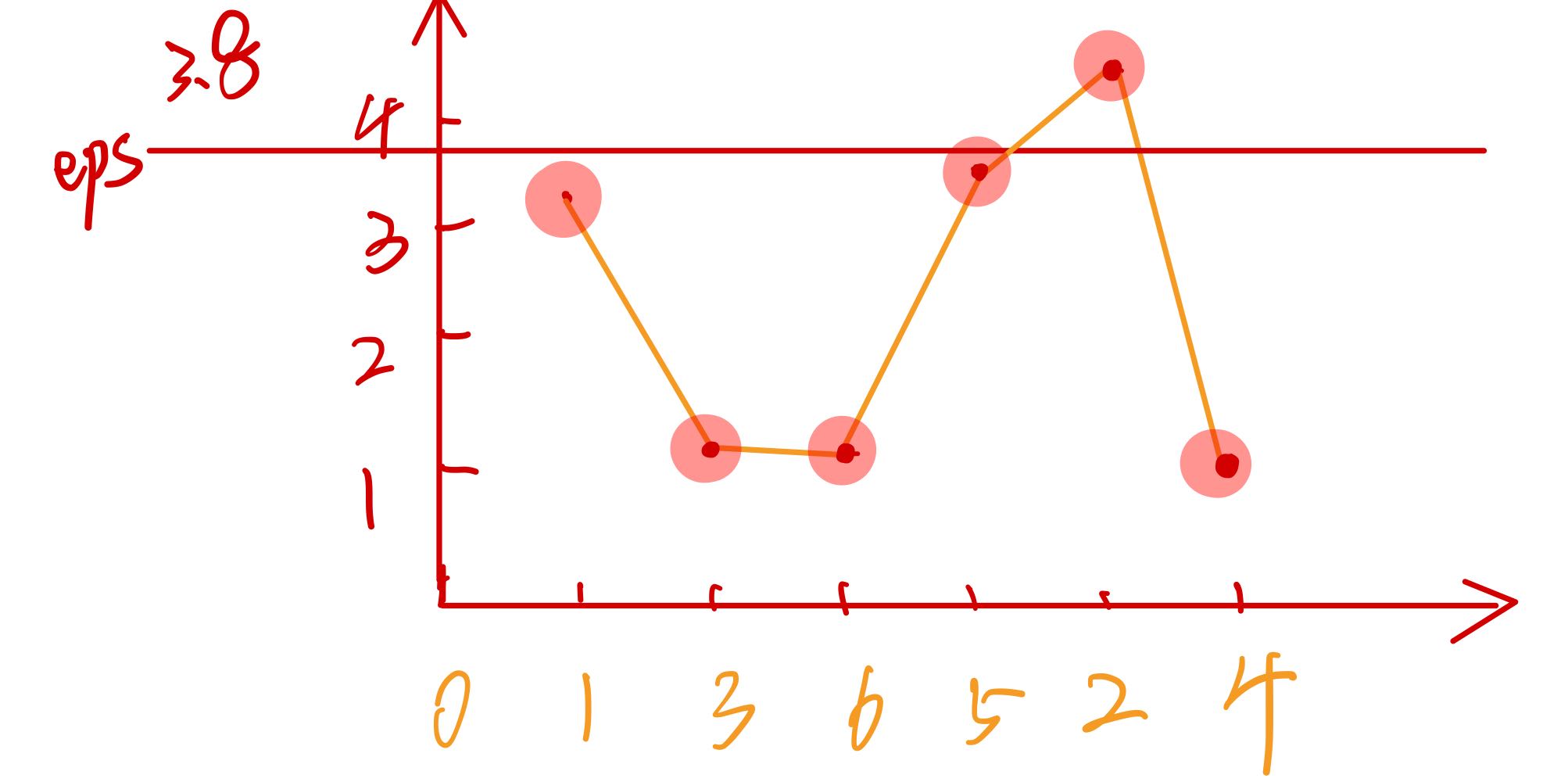
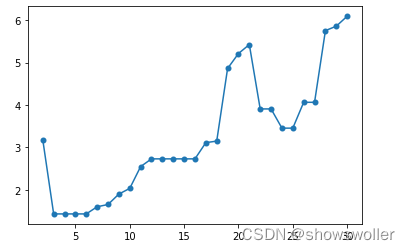
图16是OPTICS算法输出的有序对象的可达距离曲线。聚类是曲线凹下去的区域。我们可以认为#3对象到#16对象属于一个聚类。需要注意的#3对象,它是前面连续区域最后一个高可达距离的对象,高可达距离意味着#3和对象#1,#2的距离远,它和#4对象的距离是比较近的。
在真实的对象集合中,聚类的边界不总是有着较大倾斜度的对象。如图17,第一个聚类的开始和结尾的倾斜度非常大,第二聚类的结尾部分的倾斜度较小。


5.2 定义
假设OPTICS算法输出了有序对象集合[1…n],这里用序号代表对象。r(p)表示有序类表中的第p个对象的可达距离,r(p+1)表示有序类表中的第p+1个对象的可达距离。 是倾斜因子,取值范围(0,1)。
是倾斜因子,取值范围(0,1)。
【定义9】倾斜点
向上倾斜点

向下倾斜点
 注:论文中是错的。
注:论文中是错的。
【定义10】倾斜区域
向上倾斜区域( )
)
 如果满足如下条件则称为向上倾斜区域。注:可能只包含一个对象
如果满足如下条件则称为向上倾斜区域。注:可能只包含一个对象
●s 是向上倾斜点
●e是向上倾斜点
●
●I中不存在这种情形:连续非向上倾斜点的数量大于MinPts
●最大化:
向下倾斜区域( )
)
定义类似向上倾斜区域。
【定义11】聚类
C = ?s??e?????1??n?,若C满足如下条件,则C是一个聚类。

●
●
●
●
●
5.3 获取nature聚类算法
我们可以通过定义11轻松的获取算法。通过分解定义11中的第4个条件,可以提高算法的性能。
6下一步研究
1 大数据量下的性能提高
2 支持增量式计算