像通常的计算一样,强大的能力意味着至少有一点复杂性。这篇由两部分组成的文章通过准确解释物化视图的工作原理来填补空白,以便即使是初学者也可以有效地使用它们。我们将提供几个详细的示例,您可以根据自己的用途进行调整。在此过程中,我们探索了用于创建视图的语法的确切含义,并让您深入了解 ClickHouse 在下面所做的事情。示例是完全独立的,因此您可以将它们复制/粘贴到clickhouse客户端并自己运行它们。
一、基础
1.1 求和
ClickHouse 物化视图会自动在表之间转换数据。它们就像在运行查询后插入并将结果存放在第二个表中的触发器。让我们看一个基本的例子。假设我们有一个表格来记录用户下载,如下所示。
CREATE TABLE download (when DateTime,userid UInt32,bytes Float32
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (userid, when)
我们想跟踪每个用户的每日下载量。让我们看看如何通过查询来做到这一点。首先,我们需要为单个用户向表中添加一些数据。
INSERT INTO downloadSELECTnow() + number * 60 as when,25,rand() % 100000000FROM system.numbersLIMIT 5000
接下来,让我们运行一个查询来显示该用户的每日下载量。随着新用户的添加,这也将正常工作。
SELECTtoStartOfDay(when) AS day,userid,count() as downloads,sum(bytes) AS bytes
FROM download
GROUP BY userid, day
ORDER BY userid, day
┌─────────────────day─┬─userid─┬─downloads─┬───────bytes─┐
│ 2019-09-04 00:00:00 │ 25 │ 656 │ 33269129531 │
│ 2019-09-05 00:00:00 │ 25 │ 1440 │ 70947968936 │
│ 2019-09-06 00:00:00 │ 25 │ 1440 │ 71590088068 │
│ 2019-09-07 00:00:00 │ 25 │ 1440 │ 72100523395 │
│ 2019-09-08 00:00:00 │ 25 │ 24 │ 1141389078 │
└─────────────────────┴───────┴──────────┴─────────────┘
我们可以通过每次运行查询以交互方式为应用程序计算这些每日总数,但对于大型表,提前计算它们会更快且资源效率更高。因此,最好将结果放在一个单独的表格中,该表格连续跟踪每个用户每天的下载总和。我们可以通过下面的物化视图做到这一点。
CREATE MATERIALIZED VIEW download_daily_mv
ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(day) ORDER BY (userid, day)
POPULATE
AS SELECTtoStartOfDay(when) AS day,userid,count() as downloads,sum(bytes) AS bytes
FROM download
GROUP BY userid, day
这里有三件重要的事情需要注意。首先,物化视图定义允许使用类似于 CREATE TABLE 的语法,因为该命令实际上将创建一个隐藏的目标表来保存视图数据。我们使用旨在简化求和和计数的 ClickHouse 引擎:SummingMergeTree,它是计算聚合的物化视图的推荐引擎。
其次,视图定义包括关键字 POPULATE。这告诉 ClickHouse 将视图立刻计算 dowload 表中的现有数据,就好像它刚刚插入一样。稍后我们将更多地讨论自动填充。
最后,视图定义包括一个 SELECT 语句,该语句定义了在加载视图时如何转换数据。此查询在表中的新数据上运行,以计算每个用户 ID 每天的下载次数和总字节数。它本质上与我们以交互方式运行的查询相同,但在这种情况下,结果将被放入隐藏的目标表中。我们可以跳过排序,因为视图定义已经确保了排序顺序。
现在让我们直接从物化视图中查询
SELECT * FROM download_daily_mv
ORDER BY day, userid
LIMIT 5
┌─────────────────day─┬─userid─┬─downloads─┬───────bytes─┐
│ 2019-09-04 00:00:00 │ 25 │ 656 │ 33269129531 │
│ 2019-09-05 00:00:00 │ 25 │ 1440 │ 70947968936 │
│ 2019-09-06 00:00:00 │ 25 │ 1440 │ 71590088068 │
│ 2019-09-07 00:00:00 │ 25 │ 1440 │ 72100523395 │
│ 2019-09-08 00:00:00 │ 25 │ 24 │ 1141389078 │
└─────────────────────┴───────┴──────────┴─────────────┘
与之前的查询完全相同。原因是上面介绍的 POPULATE 关键字。它确保源表中的现有数据自动加载到视图中。但是有一个重要的警告:如果在视图填充时插入新数据,ClickHouse 将错过它们。我们将在本系列的第二部分展示如何手动插入数据并避免丢失数据的问题。
现在尝试使用其他用户向表中添加更多数据。
INSERT INTO downloadSELECTnow() + number * 60 as when,22,rand() % 100000000FROM system.numbersLIMIT 5000
如果您从物化视图中进行选择,您会看到它现在包含用户 ID 22 和 25 的总数。请注意,一旦 INSERT 完成 新数据立即可用,视图就会被填充。这是 ClickHouse 物化视图的一个重要特性,使它们对实时分析非常有用。
这是查询和新结果。
SELECT * FROM download_daily_mv ORDER BY userid, day
┌─────────────────day─┬─userid─┬─downloads─┬───────bytes─┐
│ 2019-09-04 00:00:00 │ 22 │ 654 │ 31655571524 │
│ 2019-09-05 00:00:00 │ 22 │ 1440 │ 71514547751 │
│ 2019-09-06 00:00:00 │ 22 │ 1440 │ 71839871989 │
│ 2019-09-07 00:00:00 │ 22 │ 1440 │ 70915563752 │
│ 2019-09-08 00:00:00 │ 22 │ 26 │ 1227350921 │
│ 2019-09-04 00:00:00 │ 25 │ 656 │ 33269129531 │
│ 2019-09-05 00:00:00 │ 25 │ 1440 │ 70947968936 │
│ 2019-09-06 00:00:00 │ 25 │ 1440 │ 71590088068 │
│ 2019-09-07 00:00:00 │ 25 │ 1440 │ 72100523395 │
│ 2019-09-08 00:00:00 │ 25 │ 24 │ 1141389078 │
└─────────────────────┴───────┴──────────┴─────────────┘
作为练习,您可以针对源 dowload 表运行原始查询,以确认它与视图中的总数匹配。
作为最后一个示例,让我们使用每日视图按月选择总计。在这种情况下,我们将每日视图视为普通表格并按月分组如下。我们添加了 WITH TOTALS 子句,该子句打印了一个方便的聚合总和。
SELECTtoStartOfMonth(day) AS month,userid,sum(downloads),sum(bytes)
FROM download_daily_mv
GROUP BY userid, month WITH TOTALS
ORDER BY userid, month
┌──────month─┬─userid─┬─sum(downloads)─┬───sum(bytes)─┐
│ 2019-09-01 │ 22 │ 5000 │ 247152905937 │
│ 2019-09-01 │ 25 │ 5000 │ 249049099008 │
└────────────┴───────┴───────────────┴─────────────┘
Totals:
┌──────month─┬─userid─┬─sum(downloads)─┬───sum(bytes)─┐
│ 0000-00-00 │ 0 │ 10000 │ 496202004945 │
└────────────┴───────┴───────────────┴─────────────┘
从前面的例子我们可以清楚地看到物化视图是如何正确地从源数据中总结数据的。正如最后一个例子所示,我们甚至可以总结总结。那么幕后究竟发生了什么?下图说明了数据的逻辑流。
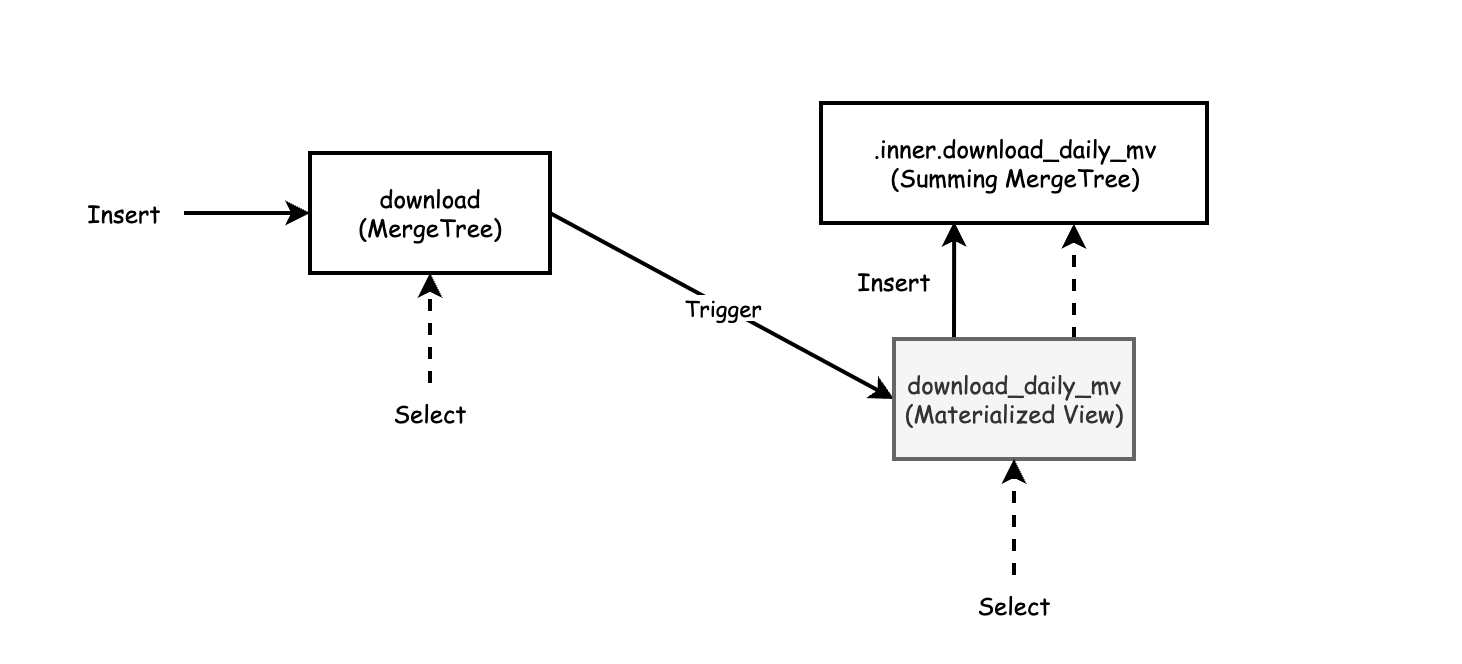
如图所示,源表上的 INSERT 值被转换并应用于目标表。要填充视图,您只需将值插入源表。您可以从目标表以及物化视图中进行查询。从物化视图的查询会被传递到视图自动创建的内部表。从图中还需要注意另一件重要的事情,物化视图创建一个具有特殊名称的私有表来保存数据。如果您通过 DROP TABLE download_daily_mv 删除实体化视图,则私有表将消失。如果您需要更改视图,则需要将其删除并使用新数据重新创建。(后面会针对这个特性给出解决方案)
1.2 总结
我们刚刚查看的示例使用 SummingMergeTree 创建一个视图来添加每日用户下载量。我们在物化视图中的 SELECT 上使用标准 SQL 语法。这是 SummingMergeTree 引擎的一项特殊功能,仅适用于求和和计数。对于其他类型的聚合,我们需要使用不同的方法。
此外,我们的示例使用 POPULATE 关键字将现有表数据发布到视图创建的私有目标表中。如果在填充视图时有新的 INSERT 到达,ClickHouse 将错过它们。当您是唯一使用数据集的人时,这个限制很容易解决,但对于不断加载数据的生产系统来说是个问题。此外,当视图被删除时,私有表也会消失。这使得很难更改视图以适应源表中的模式更改。
在下一节中,我们将展示如何创建物化视图来计算其他类型的聚合,例如平均值或最大值/最小值。我们还将展示如何显式定义目标表并使用我们自己的 SQL 语句手动将数据加载到其中。我们还将简要介绍模式迁移。同时,我们希望您喜欢这个简短的介绍,并发现这些示例很有用。
二、进阶
在第 1 部分中,我们介绍了一种构建 ClickHouse 物化视图的方法,该视图使用 SummingMergeTree 引擎计算总和/计数。 SummingMergeTree 可以对这两种类型的聚合使用普通的 SQL 语法。我们还让物化视图定义自动为数据创建基础表。这两种技术都很快,但对生产系统有限制。在当前帖子中,我们将展示如何在现有表上创建具有一系列聚合类型的物化视图;此方法适用当您需要计算的不仅仅是简单的总和时;对于表有大量到达数据或必须处理架构更改的情况,它也很方便。
2.1 使用状态函数和 TO 表创建更灵活的视图
在以下示例中,我们将测量来自设备的读数。让我们从表定义开始。
CREATE TABLE counter (when DateTime DEFAULT now(),device UInt32,value Float32
) ENGINE=MergeTree
PARTITION BY toYYYYMM(when)
ORDER BY (device, when)
接下来,我们添加足够的数据以使查询时间变得足够慢:10 台设备的 10 亿行数据。
INSERT INTO counterSELECTtoDateTime('2015-01-01 00:00:00') + toInt64(number/10) AS when,(number % 10) + 1 AS device,(device * 3) + (number/10000) + (rand() % 53) * 0.1 AS valueFROM system.numbers LIMIT 1000000
现在让我们看一个我们希望定期运行的示例查询。它汇总了整个采样期间所有设备的所有数据。在这种情况下,这意味着表中价值 3.25 年的数据,所有这些数据都在 2019 年之前。
SELECTdevice,count(*) AS count,max(value) AS max,min(value) AS min,avg(value) AS avg
FROM counter
GROUP BY device
ORDER BY device ASC
. . .
10 rows in set. Elapsed: 2.709 sec. Processed 1.00 billion rows, 8.00 GB (369.09 million rows/s., 2.95 GB/s.)
前面的查询很慢,因为它必须读取表中的所有数据才能得到答案。我们想要设计一个读取更少数据的物化视图。事实证明,如果我们定义一个每天汇总数据的视图,ClickHouse 将正确汇总整个时间间隔内的每日总数。
与我们之前的简单示例不同,我们将自己定义目标表。这样做的好处是表现在是可见的,这使得加载数据以及进行模式迁移变得更加容易。这是目标表定义。
CREATE TABLE counter_daily (day DateTime,device UInt32,count UInt64,max_value_state AggregateFunction(max, Float32),min_value_state AggregateFunction(min, Float32),avg_value_state AggregateFunction(avg, Float32)
)
ENGINE = SummingMergeTree()
PARTITION BY tuple()
ORDER BY (device, day)
表定义引入了一种新的数据类型,称为聚合函数,它保存部分聚合的数据。除总和或计数以外的聚合都需要该类型。接下来我们创建对应的物化视图。它从 counter(源表)中选择,并使用 CREATE 语句中的特殊 TO 语法将数据发送到 counter_daily(目标表)。
CREATE MATERIALIZED VIEW counter_daily_mv
TO counter_daily
AS SELECTtoStartOfDay(when) as day,device,count(*) as count,maxState(value) AS max_value_state,minState(value) AS min_value_state,avgState(value) AS avg_value_state
FROM counter
WHERE when >= toDate('2019-01-01 00:00:00')
GROUP BY device, day
ORDER BY device, day
TO 关键字让我们指向目标表,但有一个缺点。 ClickHouse 不允许将 POPULATE 关键字与 TO 一起使用。因此,从物化视图开始没有数据。我们将手动加载数据。但我们还将使用一个很好的技巧,使我们能够避免在同时进行活动数据加载的情况下出现问题。
请注意,视图定义有一个 WHERE 子句。这表示应忽略 2019 年之前的任何数据。我们现在有一种方法可以以不丢失数据的方式处理数据加载。该视图将处理 2019 年到达的新数据。同时,我们可以使用 INSERT 加载 2018 年及之前的旧数据。
让我们通过将新数据加载到 counter 表中来演示它是如何工作的。新数据将于 2019 年开始,并应自动加载到视图中。
INSERT INTO counterSELECTtoDateTime('2019-01-01 00:00:00') + toInt64(number/10) AS when,(number % 10) + 1 AS device,(device * 3) + (number / 10000) + (rand() % 53) * 0.1 AS valueFROM system.numbers LIMIT 10000000
现在让我们使用以下 INSERT 手动加载旧数据。它会加载 2018 年及之前的所有数据。
INSERT INTO counter_daily
SELECTtoStartOfDay(when) as day,device,count(*) AS count,maxState(value) AS max_value_state,minState(value) AS min_value_state,avgState(value) AS avg_value_state
FROM counter
WHERE when < toDateTime('2019-01-01 00:00:00')
GROUP BY device, day
ORDER BY device, day
我们终于准备好从视图中选择数据。与目标表和物化视图一样,ClickHouse 使用专门的语法从视图中进行选择。
SELECTdevice,sum(count) AS count,maxMerge(max_value_state) AS max,minMerge(min_value_state) AS min,avgMerge(avg_value_state) AS avg
FROM counter_daily
GROUP BY device
ORDER BY device ASC
┌─device─┬────count─┬───────max─┬─────min─┬──────────────avg─┐
│ 1 │ 101000000 │ 100008.17 │ 3.008 │ 49515.50042561026 │
│ 2 │ 101000000 │ 100011.164 │ 6.0031 │ 49518.500627177054 │
│ 3 │ 101000000 │ 100014.17 │ 9.0062 │ 49521.50087863756 │
│ 4 │ 101000000 │ 100017.04 │ 12.0333 │ 49524.5006612177 │
│ 5 │ 101000000 │ 100020.19 │ 15.0284 │ 49527.50092650661 │
│ 6 │ 101000000 │ 100023.15 │ 18.0025 │ 49530.50098047898 │
│ 7 │ 101000000 │ 100026.195 │ 21.0326 │ 49533.50099656529 │
│ 8 │ 101000000 │ 100029.18 │ 24.0297 │ 49536.50119239665 │
│ 9 │ 101000000 │ 100031.984 │ 27.0258 │ 49539.50119958179 │
│ 10 │ 101000000 │ 100035.17 │ 30.0229 │ 49542.501308345716 │
└───────┴──────────┴───────────┴────────┴───────────────────┘
10 rows in set. Elapsed: 0.003 sec. Processed 11.70 thousand rows, 945.49 KB (3.76 million rows/s., 304.25 MB/s.)
此查询正确汇总了所有数据,包括新行。您可以通过在 counter 表上重新运行原始 SELECT 来检查。不同之处在于物化视图返回数据的速度快了大约 900 倍。值得学习一些新语法来获得它!
在这一点上,我们可以回过头来解释幕后发生的事情。
2.2 聚合函数
聚合函数(AggregateFunction)就像收集器,允许 ClickHouse 从分布在许多部分的数据中构建聚合。下图显示了它如何计算平均值。我们从源表中的一个可选值开始。物化视图使用 avgState 函数将数据转换为部分聚合,该函数是一种内部结构。最后,在选择数据时,应用 avgMerge 将部分聚合总计为结果数。
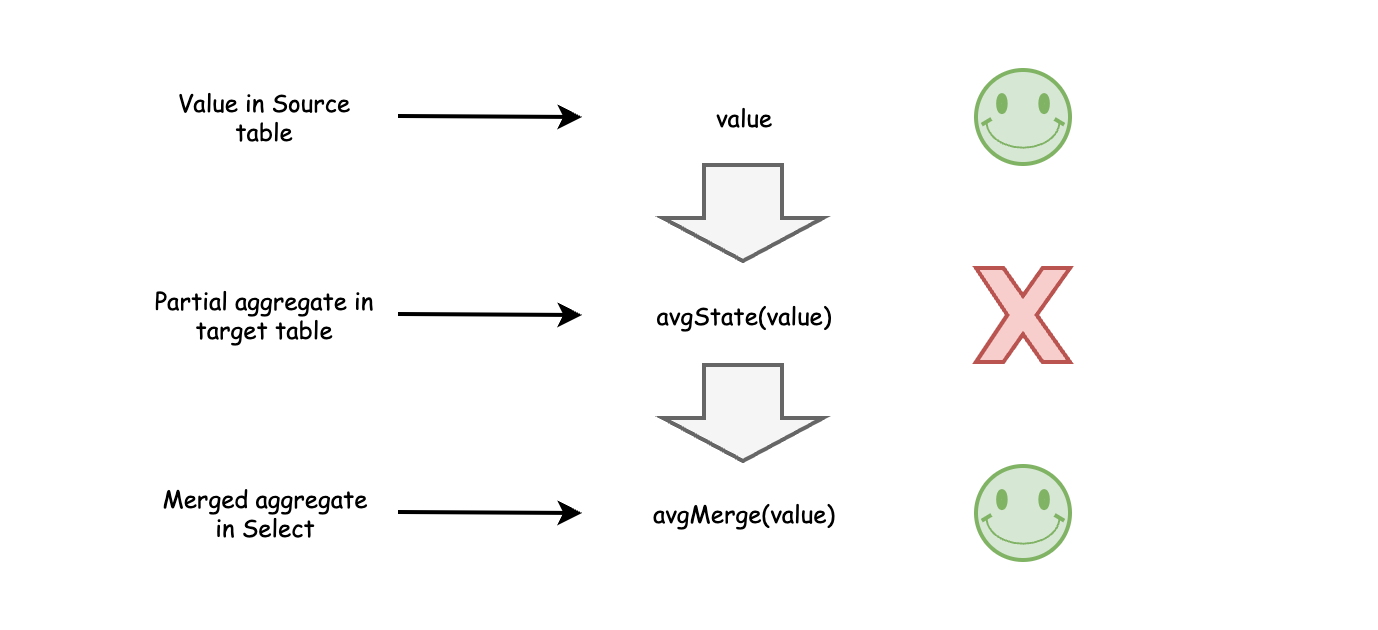
部分聚合使物化视图能够处理分布在多个节点上的许多部分的数据。即使您按变量更改分组,合并函数也会正确组装聚合。仅仅将简单的平均值组合起来是行不通的,因为当每个部分平均值加到总数中时,它们将缺乏缩放每个部分平均值所需的权重。这种行为有一个重要的后果。
还记得上面提到 ClickHouse 可以使用带有汇总每日数据的物化视图来回答我们的示例查询吗?这是聚合函数如何工作的结果。这意味着我们的每日视图也可以回答有关周、月、年或整个间隔的问题。
ClickHouse 有点不寻常,它直接暴露了 SQL 语法中的部分聚合,但它们解决问题的方式非常强大。当您设计物化视图时,请尝试使用每日总结之类的技巧来解决单个视图的多个问题。一个视图可以回答很多问题。
2.3 支持物化视图的表引擎
ClickHouse 有多个可用于物化视图的引擎。AggregatingMergeTree 引擎仅适用于聚合函数。如果要进行计数或求和,则需要使用目标表中的聚合函数数据类型来定义它们。您还需要在视图和选择语句中使用状态和合并功能。例如,要处理计数,您需要在上面的工作示例中使用 count State(count) 和 count Merge(count)。
我们建议使用 SummingMergeTree 引擎在物化视图中进行聚合。它可以很好地处理聚合函数。然而,它隐藏了它们的总和和计数,这对于简单的情况很方便。在这种情况下,它不会阻止您使用状态和合并功能;只是您不必这样做。同时它完成了聚合合并树所做的一切。
2.4 管理 schema
数据库 schema 在生产系统中往往会发生变化,尤其是那些正在积极开发的系统。当使用具有显式目标表的物化视图时,您可以相对轻松地管理此类更改。
让我们举一个简单的例子。假设 counter 表的名称更改为 counter_replicated。应用此更改后,物化视图将不起作用。更糟糕的是会阻塞 INSERT 到 counter 器表。您可以按如下方式处理更改。
-- Delete view prior to schema change.
DROP TABLE counter_daily_mv
-- Rename source table.
RENAME TABLE counter TO counter_replicated
-- Recreate view with correct source table name.
CREATE MATERIALIZED VIEW counter_daily_mv
TO counter_daily
AS SELECTtoStartOfDay(when) as day,device,count(*) as count,maxState(value) AS max_value_state,minState(value) AS min_value_state,avgState(value) AS avg_value_state
FROM counter_replicated
GROUP BY device, day
ORDER BY device, day
根据架构迁移中的实际步骤,您可能必须解决在更改物化视图定义时到达的丢失数据。您可以使用过滤条件和手动加载来处理它,如我们在主要示例中所示。
2.5 Materialized View Plumbing and Data Sizes
最后,我们再来看看数据表和物化视图之间的关系。目标表是普通表。您可以从目标表或物化视图中选择数据。没有区别。此外,如果您删除物化视图,该表仍然存在。正如我们刚刚展示的,您可以通过简单地删除并重新创建视图来更改视图。如果您需要更改目标表本身,请像对任何其他表一样运行 ALTER TABLE 命令。
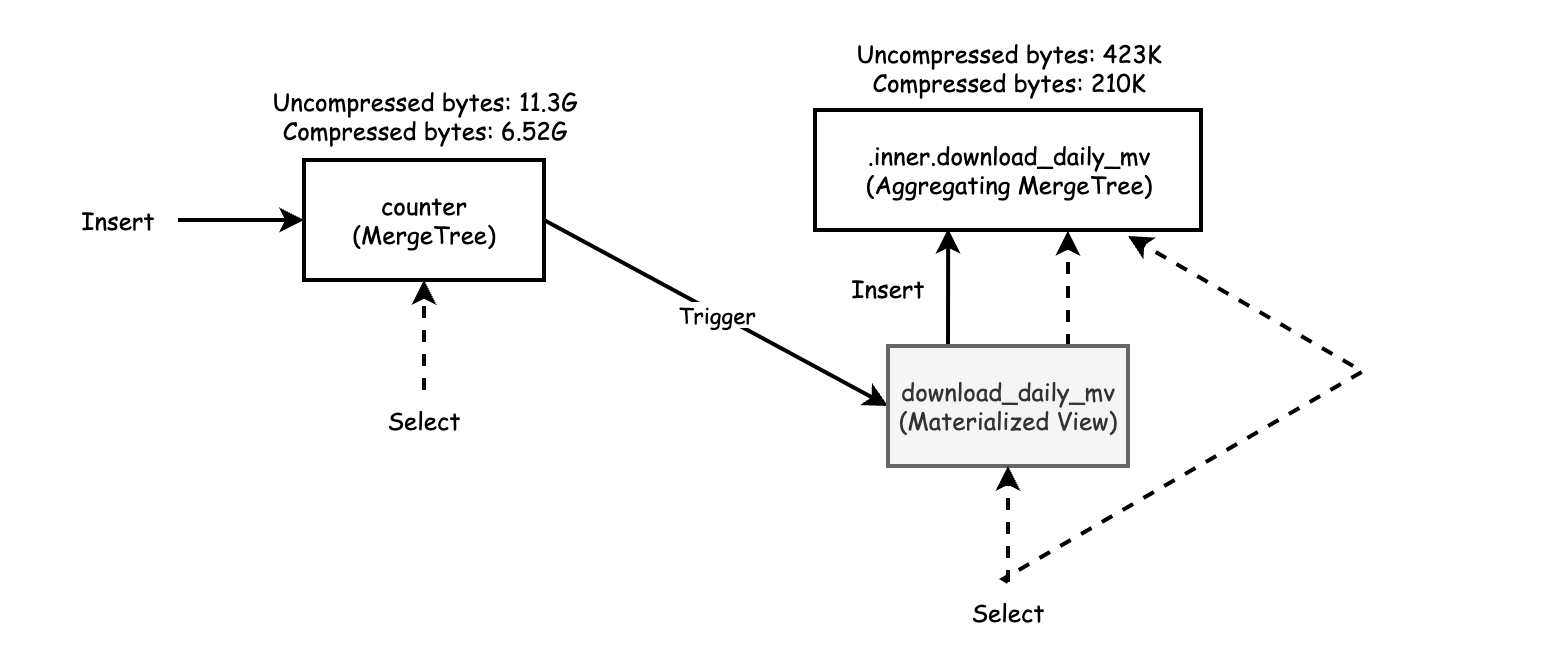
该图还显示了源表和目标表的数据大小。物化视图通常比它们聚合数据的表小得多。这肯定是这里的情况。以下查询显示了此示例的大小差异。
SELECTtable,formatReadableSize(sum(data_compressed_bytes)) AS tc,formatReadableSize(sum(data_uncompressed_bytes)) AS tu,sum(data_compressed_bytes) / sum(data_uncompressed_bytes) AS ratio
FROM system.columns
WHERE database = currentDatabase()
GROUP BY table
ORDER BY table ASC
┌─table────────────┬─tc─────────┬─tu─────────┬──────────────ratio─┐
│ counter │ 6.52 GiB │ 11.29 GiB │ 0.5778520850660066 │
│ counter_daily │ 210.35 KiB │ 422.75 KiB │ 0.4975675675675676 │
│ counter_daily_mv │ 0.00 B │ 0.00 B │ nan │
└─────────────────┴────────────┴────────────┴────────────────────┘
如计算所示,物化视图目标表比派生物化视图的源数据小大约 30,000 倍。这种差异极大地加快了查询速度。正如我们之前展示的,当使用来自物化视图的数据时,我们的测试查询运行速度提高了大约 900 倍。
2.6 总结
ClickHouse物化视图非常灵活,这得益于强大的聚合功能以及源表、物化视图和目标表之间的简单关系。物化视图允许显式目标表这一事实是一个有用的特性,它使模式迁移更简单。您还可以通过将过滤条件添加到视图 SELECT 定义并手动加载丢失的数据来减轻潜在的丢失视图更新。