文章转自:http://www.kancloud.cn/digest/prandmethod/102850
本文的目的是学习和掌握BP神经网络的原理及其学习算法。在MATLAB平台上编程构造一个3-3-1型的singmoid人工神经网络,并使用随机反向传播算法和成批反向传播算法来训练这个网络,这里设置不同的初始权值,研究算法的学习曲线和训练误差。有了以上的理论基础,最后将构造并训练一个3-3-4型的神经网络来分类4个等概率的三维数据集合。
一、技术论述
1.神经网络简述
神经网络是一种可以适应复杂模型的非常灵活的启发式的统计模式识别技术。而反向传播算法是多层神经网络有监督训练中最简单也最一般的方法之一,它是线性LMS算法的自然延伸。
网络基本的学习方法是从一个未训练网络开始,向输入层提供一个训练模式,再通过网络传递信号,并决定输出层的输出值。此处的这些输出都与目标值进行比较;任一差值对应一误差。该误差或准则函数是权值的某种标量函数,它在网络输出与期望输出匹配时达到最小。权值向着减小误差值的方向调整。一个BP神经网络的基本结构如下图所示,图中Wji,Wkj是需要学习的权值矩阵:

2.三层BP神经网络
一个三层神经网络是由一个输入层、一个隐含层和一个输出层组成,他们由可修正的权值互连。在这基础上构建的3-3-1神经网络,是由三个输入层、三个隐含层和一个输出层组成。隐含层单元对它的各个输入进行加权求和运算而形成标量的“净激活”。也就是说,净激活是输入信号与隐含层权值的内积。通常可把净激活写成:

其中x为增广输入特征向量(附加一个特征值x0=1),w为权向量(附加一个值W0)。由上面的图可知,这里的下标i是输入层单元的索引值,j是隐含层单元的索引。Wji表示输入层单元i到隐含层单元j的权值。为了跟神经生物学作类比,这种权或连接被称为“突触”,连接的值叫“突触权”。每一个隐含层单元激发出一个输出分量,这个分量是净激活net的非线性函数f(net),即:

这里需要重点认识激活函数的作用。激活函数的选择是构建神经网络过程中的重要环节,下面简要介绍常用的激活函数:
(a)线性函数 ( Liner Function )

(b) 阈值函数 ( Threshold Function )

以上激活函数都属于线性函数,下面是两个常用的非线性激活函数:
(c)S形函数 ( Sigmoid Function )

(d) 双极S形函数

S形函数与双极S形函数的图像如下:

由于S形函数与双极S形函数都是可导的,因此适合用在BP神经网络中。(BP算法要求激活函数可导)
介绍完激活函数,类似的,每个输出单元在隐含层单元信号的基础上,使用类似的方法就可以算出它的净激活如下:

同理,这里的下标k是输出层单元的索引值,nH表示隐含层单元的数目,这里把偏置单元等价于一个输入恒为y0=1的隐含层单元。将输出单元记为zk,这样输出单元对net的非线性函数写为:

综合以上公式,显然输出zk可以看成是输入特征向量x的函数。当有c个输出单元时,可以这样来考虑此网络:计算c个判别函数 ,并通过使判别函数最大来将输入信号分类。在只有两种类别的情况下,一般只采用单个输出单元,而用输出值z的符号来标识一个输入模式。
,并通过使判别函数最大来将输入信号分类。在只有两种类别的情况下,一般只采用单个输出单元,而用输出值z的符号来标识一个输入模式。
3.网络学习
反向传播算法(BP算法)由两部分组成:信息的正向传递与误差的反向传播。在正向传播过程中,输入信息从输入经隐含层逐层计算传向输出层,第一层神经元的状态只影响下一层神经元的状态。如果输出层没有得到期望的输出,则计算输出层的误差变化值,然后转向反向传播,通过网络将误差信号沿原来的连接通路反传回来修改各层神经元的权值直至达到期望目标。
神经网络的学习方法正是依赖以上两个步骤,对于单个模式的学习规则,考虑一个模式的训练误差,先定义为输出端的期望输出值tk(由教师信号给出)和实际输出值zk的差的平方和:

定义目标函数:

其中t和z是长度为c的目标向量和网络输出向量;w表示神经网络里的所有权值。
反向传播算法学习规则是基于梯度下降算法的。权值首先被初始化为随机值,然后向误差减小的方向调整:

其中η是学习率,表示权值的相对变化尺度。反向传播算法在第m次迭代时的权向量更新公式可写为:

其中m是特定模式的索引。由于误差并不是明显决定于Wjk,这里需要使用链式微分法则:

其中单元k的敏感度定义为:

又有:

综上所述,隐含层到输出层的权值更新为:

输入层到隐含层的权值学习规则更微妙。再运用链式法则计算:

其中:

可以用上式来定义隐单元的敏感度:

因此,输入层到隐含层的权值的学习规则就是:

4.训练协议
反向传播的随机协议和成批协议如下步骤所示:

在成批训练中,所有的训练模式都先提供一次,然后将对应的权值更新相加,只有这时网络里的实际权值才开始更新。这个过程将一直迭代知道某停止准则满足。

二、自编函数实现BP网络
以下简单编写了一个3-3-1三层BP神经网络的构建与两种训练方法(写得比较杂乱),以下是基本步骤:
1.构造 3-3-1 型的sigmoid 网络,用以下表格中的w1和w2类的数据进行训练,并对新模式进行分类。利用随机反向传播(算法1),学习率η=0.1,以及sigmoid函数,其中a=1.716,b =2/3,作为其隐单元和输出单元的激活函数。

2.构造三层神经网络,参数包括:输入层、中间层、输出层神经元向量,以及输入层到中间层的权值矩阵,中间层到输出层的权值矩阵,中间层神经元的偏置向量,输出层神经元的偏置向量等。其实质是定义上述变量的一维和二维数组。
3.编写函数[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb),实现BP网络的前馈输出。为了便于后续的学习算法的实现,该函数的输出变量包含:第j个隐单元对各输入的净激活net_j;第k个输出单元对各输入的净激活net_k;网络中隐藏层的输出y和输出单元的输出向量z。
4.编写函数,实现BP网络的权值修正。其中,神经元函数,及其导数可参考:
神经元函数:

神经元函数导数:

5.编写函数[NewWxy, NewWyz, NewWyb, NewWzb, J] = train(x, t, Wxy, Wyz, Wyb, Wzb),实现算法1和2所述的BP网络的训练算法,输出各权向量的变化量和当前目标函数值J。
% 函数:计算人工神经网络的各级输出
% 输入参数:
% x:输入层神经元向量(3维)
% Wxy:随机生成的从输入层到隐含层的权值矩阵
% Wyz:随机生成的从隐含层到输出层的权值矩阵
% Wyb:权值偏置向量
% Wzb:权值偏置向量
% 内部变量与公式:
% f(net)=a*tanh(b*net):Sigmoid激活函数
% a:Sigmoid激活函数的参数
% b:Sigmoid激活函数的参数
% 输出参数:
% net_j:第j个隐单元对各输入的净激活
% net_k:第k个输出单元对各输入的净激活
% y:隐含层的输出向量
% z:输出单元的输出向量
function [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb)% Sigmoid激活函数的参数
a = 1.716;
b = 2/3;
net_j = Wxy * x' + Wyb;
y = 3.432 ./ (1 + exp(-1.333 * net_j)) - 1.716;% a * tanh(b * net_j); % 隐含层的输出
net_k = Wyz' * y + Wzb;
z = 3.432 ./ (1 + exp(-1.333 * net_k)) - 1.716;%a * tanh(b * net_k); % 输出层结果% 人工神经网络训练函数
% 输入参数:
% x:输入层神经元向量(3维)
% t:教师向量
% Wxy:随机生成的从输入层到隐含层的权值矩阵
% Wyz:随机生成的从隐含层到输出层的权值矩阵
% Wyb:权值偏置向量
% Wzb:权值偏置向量
% 内部变量与公式:
% Error_xy:隐藏层反传回输入层的误差
% Error_yz:输出层反传回隐藏层的误差
% 输出参数:
% NewWxy:更新后的从输入层到隐含层的权值矩阵
% NewWyz:更新后的从隐含层到输出层的权值矩阵
% NewWyb:更新后的权值偏置向量
% NewWzb:更新后的权值偏置向量
function [NewWxy, NewWyz, NewWyb, NewWzb, J] = train(x, t, Wxy, Wyz, Wyb, Wzb)
% 基本参数设定
Eta = 0.01; % 学习因子% Sigmoid激活函数的参数
a = 1.716;
b = 2/3;
% 计算训练样本经过神经网络后的输出
[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% 计算当前目标函数值
J = power(norm((t - z),2), 2) / 2;
% 计算输出层反传回隐藏层的敏感度
Error_yz = (t - z) .* (a * b - b / a * z .* z); % zz
% 计算隐藏层反传回输入层的敏感度
Error_xy = Wyz * Error_yz .* (a * b - b / a * y .* y);
% 计算输出层到隐藏层的权值更新量
delta_Wyz = Eta * y * Error_yz';
% 计算隐藏层到输入层的权值更新量
delta_Wxy = Eta * Error_xy * x;% 更新权值
NewWxy = Wxy + delta_Wxy;
NewWyz = Wyz + delta_Wyz;
NewWyb = Wyb + Eta * Error_xy;
NewWzb = Wzb + Eta * Error_yz;function [delta_Wxy, delta_Wyz, Error_xy, Error_yz, J] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb)
% 基本参数设定
Eta = 0.01; % 学习因子% Sigmoid激活函数的参数
a = 1.716;
b = 2/3;
% 计算训练样本经过神经网络后的输出
[net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% 计算当前目标函数值
J = 1 / 2 * power(norm(t - z), 2);
% 计算输出层反传回隐藏层的误差
Error_yz = (t - z) .* (a * b - b / a * z .* z);
% 计算隐藏层反传回输入层的误差
Error_xy = Wyz * Error_yz .* (a * b - b / a * y .* y);
% 计算输出层到隐藏层的权值更新量
delta_Wyz = Eta * Error_yz * y';
% 计算隐藏层到输入层的权值更新量
delta_Wxy = Eta * Error_xy * x;% clear all;
% close all;
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% % BP神经网络实验
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%clear;close all;
% 训练样本(3类)
w1 = [ 1.58 2.32 -5.8 ;...0.67 1.58 -4.78;...1.04 1.01 -3.63;...-1.49 2.18 -0.39;...-0.41 1.21 -4.73;...1.39 3.16 2.87;...1.20 1.40 -1.89;...-0.92 1.44 -3.22;...0.45 1.33 -4.38;...-0.76 0.84 -1.96];w2 = [ 0.21 0.03 -2.21;...0.37 0.28 -1.8 ;...0.18 1.22 0.16;...-0.24 0.93 -1.01;...-1.18 0.39 -0.39;...0.74 0.96 -1.16;...-0.38 1.94 -0.48;...0.02 0.72 -0.17;...0.44 1.31 -0.14;...0.46 1.49 0.68];w3 = [-1.54 1.17 0.64;...5.41 3.45 -1.33;...1.55 0.99 2.69;...1.86 3.19 1.51;...1.68 1.79 -0.87;...3.51 -0.22 -1.39;...1.40 -0.44 0.92;...0.44 0.83 1.97;...0.25 0.68 -0.99;...-0.66 -0.45 0.08];% 初始化权值(随机初始化)
Wxy = rand(3,3) * 2 - 1;
Wyz = rand(3,1) * 2 - 1;
Wyb = rand(3,1) * 2 - 1;
Wzb = rand() * 2 - 1;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量% 以下是随机反向传播算法
delta_J = 0.001;
time = 1;
J(time) = 2 * delta_J; % 只是让迭代开始,没什么作用
detJ = 2 * delta_J;
while time < 10000%detJ > delta_J
num = ceil(rand(1) * 20); % 选择产生一个1到20之间的随机数
x = w(num, :); % 任取w中一个模式
t = T(num);
time = time + 1; % 计算迭代次数
[NewWxy, NewWyz, NewWyb, NewWzb, J(time)] = train(x, t, Wxy, Wyz, Wyb, Wzb);
% 更新权值
Wxy = NewWxy;
Wyz = NewWyz;
Wyb = NewWyb;
Wzb = NewWzb;
detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
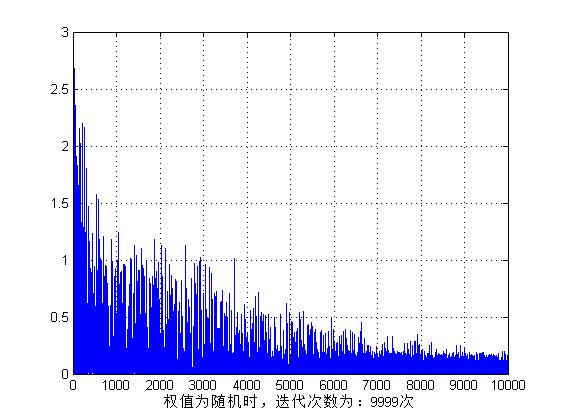
Jt = J(2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次figure,plot(Jt);grid on;% subplot(1,2,1)
xlabel(['权值为随机时,迭代次数为:',num2str(time - 1),'次']);for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
a(i) = z;
end% 初始化权值(0.5和-0.5)
Wxy = 0.5 * ones(3,3);
Wyz = -0.5 * ones(3,1);
Wyb = 0.5 * ones(3,1);
Wzb = -0.5;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量
%
% 以下是随机反向传播算法
delta_J = 0.001;
time = 1;
% [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% J(time) = 1 / 2 * power(norm(t - z), 2);
detJ = 2 * delta_J;
while time < 10000%detJ > delta_J
num = ceil(rand(1) * 20); % 选择产生一个1到20之间的随机数
x = w(num, :); % 任取w中一个模式
t = T(num);
time = time + 1; % 计算迭代次数
[NewWxy, NewWyz, NewWyb, NewWzb, J(time)] = train(x, t, Wxy, Wyz, Wyb, Wzb);
% 更新权值
Wxy = NewWxy;
Wyz = NewWyz;
Wyb = NewWyb;
Wzb = NewWzb;
% detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
Jt = J(2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次figure,plot(Jt);grid on;% subplot(1,2,2),
xlabel(['权值为固定时,迭代次数为:',num2str(time - 1),'次']);for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
b(i) = z;
end% 以下是成批反向传播算法
Eta = 0.01; % 学习因子
% 初始化权值(随机初始化)
Wxy = rands(3,3);
Wyz = rand(3,1);
Wyb = rand(3,1);
Wzb = rand();SumDelta_Wxy = zeros(3,3);SumDelta_Wyz = zeros(3,1);SumError_xy = zeros(3,1);SumError_yz = 0;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量delta_J = 0.001;
time = 1;
J(time) = 2 * delta_J;
detJ = 2 * delta_J;
% [net_j,net_k,y,z] = BackPropagation(x, Wxy, Wyz, Wyb, Wzb);
% J(time) = delta_J * 2; % 1 / 2 * power(norm(t - z), 2);
while time < 1000 %detJ > delta_J
time = time + 1; % 计算迭代次数
J(time) = 0;
for num = 1:20x = w(num, :); % 任取w1中一个模式t = T(num);[delta_Wxy, delta_Wyz, Error_xy, Error_yz, Jt] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb);SumDelta_Wxy = SumDelta_Wxy + delta_Wxy;SumDelta_Wyz = SumDelta_Wyz + delta_Wyz';SumError_xy = SumError_xy + Error_xy;SumError_yz = SumError_yz + Error_yz;J(time) = J(time) + Jt;
end
% 更新权值
Wxy = Wxy + SumDelta_Wxy;
Wyz = Wyz + SumDelta_Wyz;
Wyb = Wyb + Eta * SumError_xy;
Wzb = Wzb + Eta * SumError_yz;
detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
Jt = J(1, 2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次figure,plot(Jt);grid on;
xlabel(['权值为随机时,迭代次数为:',num2str(time - 1),'次']);for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
c(i) = z;
end
c% 以下是成批反向传播算法
Eta = 0.001; % 学习因子
% 初始化权值(0.5和-0.5)
Wxy = 0.5 * ones(3,3);
Wyz = -0.5 * ones(3,1);
Wyb = 0.5 * ones(3,1);
Wzb = -0.5;SumDelta_Wxy = zeros(3,3);SumDelta_Wyz = zeros(3,1);SumError_xy = zeros(3,1);SumError_yz = 0;
w = [w1; w2];
T = [1 1 1 1 1 1 1 1 1 1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1]; % 教师向量delta_J = 0.001;
time = 1;
while time < 1000 % detJ > delta_J
time = time + 1; % 计算迭代次数
J(time) = 0;
for num = 1:20x = w(num, :); % 任取w1中一个模式t = T(num);[delta_Wxy, delta_Wyz, Error_xy, Error_yz, Jt] = BatchTrain(x, t, Wxy, Wyz, Wyb, Wzb);SumDelta_Wxy = SumDelta_Wxy + delta_Wxy;SumDelta_Wyz = SumDelta_Wyz + delta_Wyz';SumError_xy = SumError_xy + Error_xy;SumError_yz = SumError_yz + Error_yz;J(time) = J(time) + Jt;
end
% 更新权值
Wxy = Wxy + SumDelta_Wxy;
Wyz = Wyz + SumDelta_Wyz;
Wyb = Wyb + Eta * SumError_xy;
Wzb = Wzb + Eta * SumError_yz;
detJ = abs(J(time) - J(time - 1)); % 前后两次目标函数的差值
end
Jt = J(1, 2:time); % J(1)和J(2)存储了相同的值,从J(2)算起,迭代了(time - 1)次figure,plot(Jt);grid on;
xlabel(['权值为固定时,迭代次数为:',num2str(time - 1),'次']);for i = 1:20
[net_j,net_k,y,z] = BackPropagation(w(i,:), Wxy, Wyz, Wyb, Wzb);
d(i) = z;
end
d一个目标函数经多次训练后的变化曲线:

三、调用MATLAB实现BP网络
其实MATLAB中可直接调用函数来构造神经网络,但自己编写程序实现有助于了解整个神经网络的各个细节。 使用Matlab建立前馈神经网络时可以使用到下面3个函数:
newff :前馈网络创建函数
train:训练一个神经网络
sim:使用网络进行仿真关于这3个函数的用法如下:
1.newff函数
(1)newff函数的调用方法
newff函数参数列表有很多的可选参数,具体可以参考Matlab的帮助文档,这里介绍newff函数的一种简单的形式。
net = newff(A,... % 一个n*2的矩阵,第i行元素为输入信号xi的最小值和最大值B,... % 一个k维行向量,其元素为网络中各层节点数{C},... % 一个k维字符串行向量,每一分量为对应层神经元的激活函数'trainFun'); % 选用的训练算法(2)常用的激活函数
常用的激活函数有:
a) 线性函数 (Linear transfer function):f(x) = x。该函数所对应的字符串为’purelin’。
b) 对数S形转移函数( Logarithmic sigmoid transfer function )。该函数所对应的字符串为’logsig’。
c) 双曲正切S形函数 (Hyperbolic tangent sigmoid transfer function ),也就是上面所提到的Sigmoid函数。该函数所对应的字符串为’tansig’。
注:Matlab的安装目录下的toolbox\nnet\nnet\nntransfer子目录中有所有激活函数的定义说明。
(3)常见的训练函数
traingd:梯度下降BP训练函数(Gradient descent backpropagation)
traingdx:梯度下降自适应学习率训练函数
(4)一些重要的网络配置参数设置
net.trainparam.goal:神经网络训练的目标误差
net.trainparam.show: 显示中间结果的周期
net.trainparam.epochs:最大迭代次数
net.trainParam.lr: 学习率2.神经网络训练函数train
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 神经网络训练函数train
% 各参数的含义如下:
% X:网络实际输入
% Y:网络应有输出
% tr:训练跟踪信息
% Y1:网络实际输出
% E:误差矩阵
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
[ net, tr, Y1, E ] = train(net, X, Y )3.sim函数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 各参数的含义如下:
% net:网络
% X:输入给网络的K*N矩阵,其中K为网络输入个数,N为数据样本数
% Y:输出矩阵Q*N,其中Q为神经网络输出单元的个数
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Y = sim(net, X)基于MATLAB自带函数的BP神经网络设计实例
一个实例参考:http://blog.csdn.net/gongxq0124/article/details/7681000
参考链接:http://www.cnblogs.com/heaad/archive/2011/03/07/1976443.html