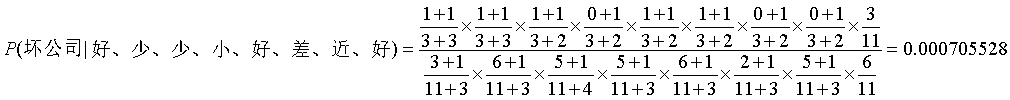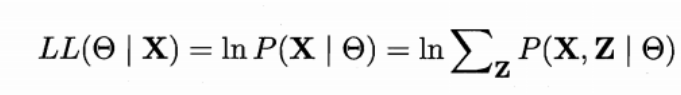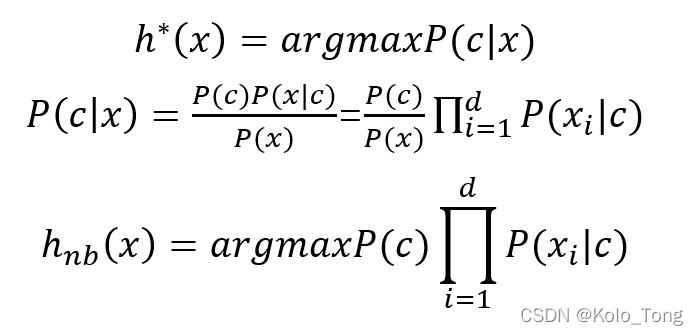目标
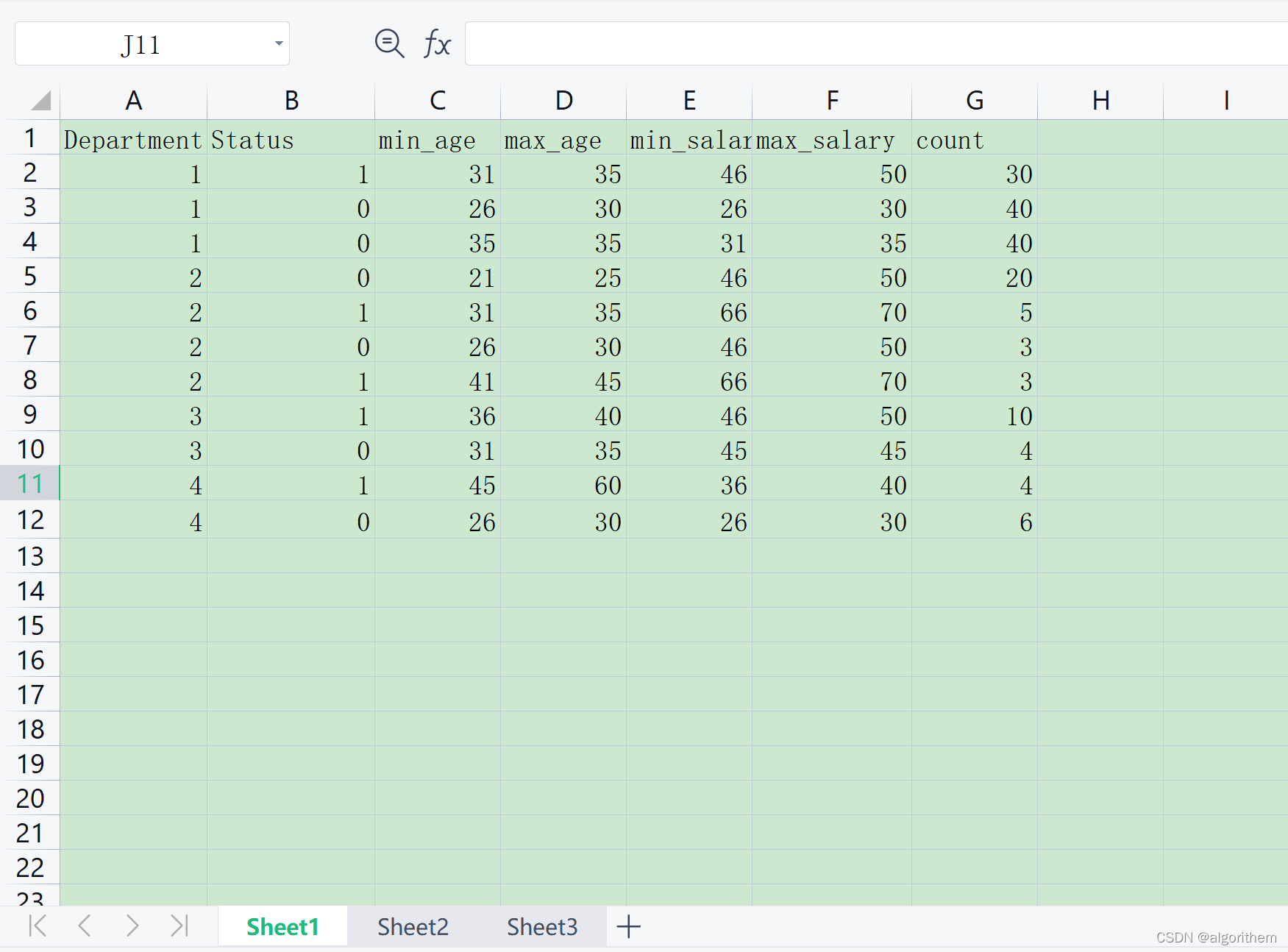
下表由雇员数据库的训练数据组成。数据已泛化。例如,age“3135”表示年龄在31~35之间。对于给定的行,count表示department、status、age和salary在该行具有给定值的元组数。
| Department | Status | Age | Salary | Count |
|---|---|---|---|---|
| Sales | Senior | 31-35 | 46K-50K | 30 |
| Sales | junior | 26-30 | 26K-30K | 40 |
| Sales | junior | 31-35 | 31K-35K | 40 |
| sysytems | junior | 21-25 | 46K-50K | 20 |
| sysytems | Senior | 31-35 | 66K-70K | 5 |
| sysytems | junior | 26-30 | 46K-50K | 3 |
| sysytems | Senior | 41-45 | 66K-70K | 3 |
| marketing | Senior | 36-40 | 46K-50K | 10 |
| marketing | junior | 31-35 | 41K-45K | 4 |
| secretary | Senior | 45-60 | 36K-40K | 4 |
| secretary | junior | 26-30 | 26K-30K | 6 |
贝叶斯定理:
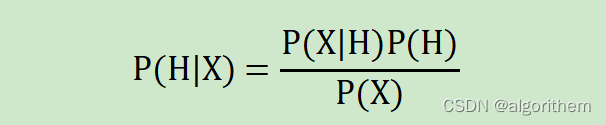
拉普拉斯校准法(拉普拉斯估计法):可以假定训练数据库D很大,以至于对每个计数加1造成的估计概率的变化可以忽略不计,但可以方便地避免概率值为为零。这种概率估计技术成为拉普拉斯校准或拉普拉斯估计法。如果对q个计数都加上1,则必须在用于计算概率地对应分母上加上q。
未使用拉普拉斯校准的朴素贝叶斯(matlab)
主程序:experiment_02.m
使用的自定义函数:Get_judge.m %调用的分类器
涉及到的数据文件:data.xlsx
三个文件夹放到同一级别目录下:

data.xlsx里面涉及的内容:
主函数experiment_02.m
clc;clear
%%朴素贝叶斯做分类
data=xlsread("data.xlsx","Sheet1","A2:G12");
career=data(:,1);%职业 1:sales 2:systems 3:marketing 4:secretary
label=data(:,2);%分类 0为junior 1为senior
%要预测的分类
sample=[2,26,30,46,50];
%%需要得到:职业2分类是1的概率;age在26-30分类是1的概率;收入在46-50之间分类是1的概率
[p1,p2]=get_judge(data,sample);
%%判断是哪个分类p1为senior
if p1>p2sample_label=1
elsesample_label=0
end
Get_judge.m %调用的分类器
function [p1,p2]= get_judge(data,sample)
%%需要判断有没有出现0值的情况,使用拉普拉斯校准
%junior和senior的概率
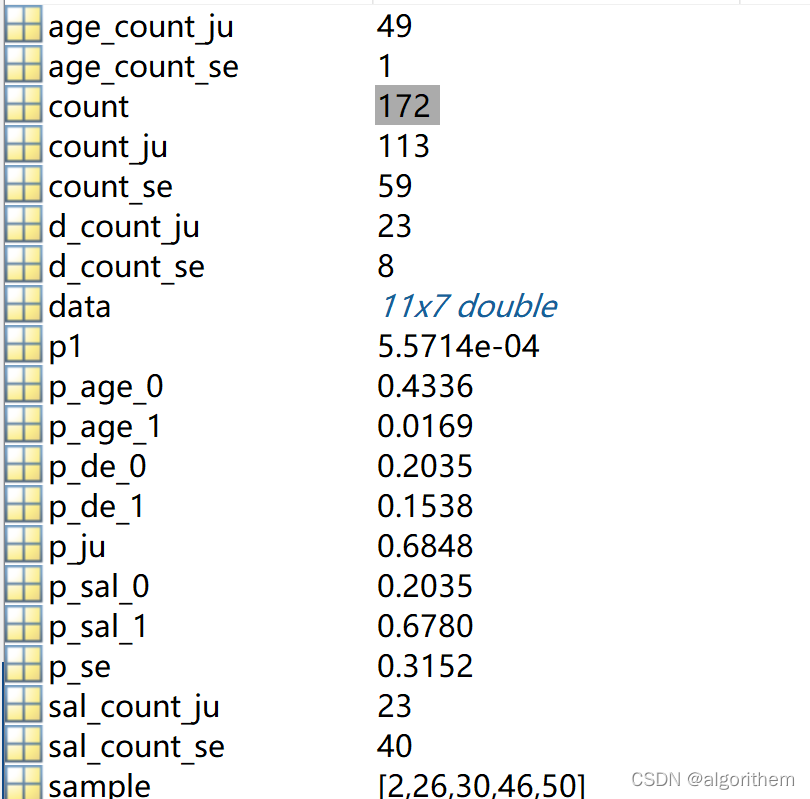
count=sum(data(:,7));
count_se=sum((data(:,2)==1).*data(:,7))
count_ju=sum((data(:,2)==0).*data(:,7))
p_se=count_se/count
p_ju=count_ju/count
%首先判断senior,junior里面是职业2的概率
% d_count=sum(data(find(data(:,1)==sample(1)),7));%职业是该样本的总人数
% d_count=sum( (data(:,1)==sample(1)).*data(:,7));
d_count_se=sum( (data(:,1) ==sample(1) & data(:,2)==1).*data(:,7));
d_count_ju=sum( (data(:,1) ==sample(1) & data(:,2)==0).*data(:,7));
p_de_1=d_count_se/count_se;
p_de_0=d_count_ju/count_ju;
%接着判断senior,junior是age:26-30之间是的概率
% age_count=sum( (data(:,3)==sample(2)).*data(:,7));
age_count_se=sum( (data(:,3)==sample(2) & data(:,2)==1).*data(:,7));
age_count_ju=sum( (data(:,3)==sample(2) & data(:,2)==0).*data(:,7));
p_age_1=age_count_se/count_se;
p_age_0=age_count_ju/count_ju;%判断senior,junior中是salary:46-50的概率
% sal_count=sum( (data(:,5)==sample(4)).*data(:,7));
sal_count_se=sum((data(:,5)==sample(4) & data(:,2)==1).*data(:,7));
sal_count_ju=sum((data(:,5)==sample(4) & data(:,2)==0).*data(:,7));
p_sal_1=sal_count_se/count_se;
p_sal_0=sal_count_ju/count_ju;
%%开始计算p1
%p_senior的概率p1=p_de_1*p_age_1*p_sal_1*p_se%%同理计算p2
p2=p_de_0*p_age_0*p_sal_0*p_ju
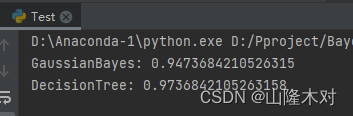
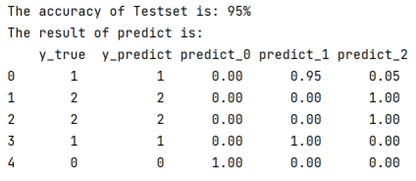
结果

分类结果为junior(sample_label=0)
添加了拉普拉斯校准后的分类器
程序入口:experiment_02.m(需要调用新的分类函数,下面给出改过的函数)
相关文件:get_judge2.m,data.xlsx(同上)
experiment_02.m
clc;clear
%%朴素贝叶斯做分类
data=xlsread("data.xlsx","Sheet1","A2:G12");
career=data(:,1);%职业 1:sales 2:systems 3:marketing 4:secretary
label=data(:,2);%分类 0为junior 1为senior
%要预测的分类
sample=[2,26,30,46,50];
%%需要得到:职业2分类是1的概率;age在26-30分类是1的概率;收入在46-50之间分类是1的概率
[p1,p2]=get_judge2(data,sample);
%%判断是哪个分类p1为senior
if p1>p2sample_label=1
elsesample_label=0
endget_judge2.m
function [p1,p2]= get_judge2(data,sample)
%%需要判断有没有出现0值的情况,使用拉普拉斯校准
%junior和senior的概率
count=sum(data(:,7));
count_se=sum((data(:,2)==1).*data(:,7))
count_ju=sum((data(:,2)==0).*data(:,7))
p_se=count_se/count
p_ju=count_ju/count
%首先判断senior,junior里面是职业2的概率
% d_count=sum(data(find(data(:,1)==sample(1)),7));%职业是该样本的总人数
% d_count=sum( (data(:,1)==sample(1)).*data(:,7));
d_count_se=sum( (data(:,1) ==sample(1) & data(:,2)==1).*data(:,7));
if d_count_se==0d_count_se=1count_se=count_se+length(unique(data(:,1)));count=count+length(unique(data(:,1)));
end
d_count_ju=sum( (data(:,1) ==sample(1) & data(:,2)==0).*data(:,7));
if d_count_ju==0d_count_ju=1count_ju=count_ju+length(unique(data(:,1)));count=count+length(unique(data(:,1)));
end
p_de_1=d_count_se/count_se;
p_de_0=d_count_ju/count_ju;
%接着判断senior,junior是age:26-30之间是的概率
% age_count=sum( (data(:,3)==sample(2)).*data(:,7));
age_count_se=sum( (data(:,3)==sample(2) & data(:,2)==1).*data(:,7));
if age_count_se==0age_count_se=1count_se=count_se+length(unique(data(:,3)));count=count+length(unique(data(:,3)));
end
age_count_ju=sum( (data(:,3)==sample(2) & data(:,2)==0).*data(:,7));
if age_count_ju==0age_count_ju=1count_ju=count_ju+length(unique(data(:,3)));count=count+length(unique(data(:,3)));
end
p_age_1=age_count_se/count_se;
p_age_0=age_count_ju/count_ju;%判断senior,junior中是salary:46-50的概率
% sal_count=sum( (data(:,5)==sample(4)).*data(:,7));
sal_count_se=sum((data(:,5)==sample(4) & data(:,2)==1).*data(:,7));
if sal_count_se==0sal_count_se=1count_se=count_se+length(unique(data(:,5)))
end
sal_count_ju=sum((data(:,5)==sample(4) & data(:,2)==0).*data(:,7));
if sal_count_ju==0sal_count_ju=1count_ju=count_ju+length(unique(data(:,5)))
end
p_sal_1=sal_count_se/count_se;
p_sal_0=sal_count_ju/count_ju;
%%开始计算p1
%p_senior的概率p1=p_de_1*p_age_1*p_sal_1*p_se%%同理计算p2
p2=p_de_0*p_age_0*p_sal_0*p_ju
data.xlsx
结果
添加了拉普拉斯校准后的分类器:
上述哪里如果有问题的话,还请指教。