1. 贝叶斯原理
Naive Bayes 官方网址:
https://scikit-learn.org/stable/modules/naive_bayes.html
GitHub地址:https://github.com/gao7025/naive_bayes.git
贝叶斯分类是以贝叶斯定理为基础的一种分类算法,其主要思想为:先验概率+新的数据=后验概率
已知某条件概率,如何得到事件交换后的概率;即在已知P(B|A)的情况下求得P(A|B)。条件概率P(B|A)表示事件A已经发生的前提下,事件B发生的概率。其基本求解公式为:P(B|A)=P(AB)/P(A)。
贝叶斯定理:
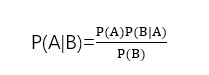
例如:
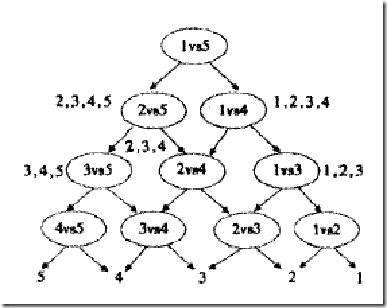
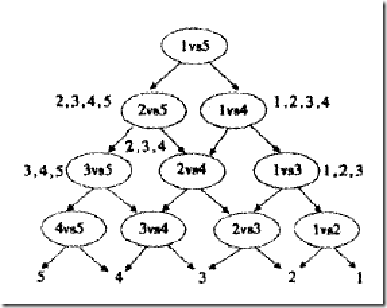
从家里去公司上班有三种交通方式打车、坐地铁和乘公交,对应概率为P(A1)=0.5、P(A2)=0.3、P(A3)=0.2,在已知每种方式下上班迟到的概率分别为:打车迟到:P(B|A1)=0.2,坐地铁迟到:P(B|A2)=0.4,乘公交迟到P(B|A3)=0.7,求解,若上班迟到了,是打车方式的概率是多少,即求解P(A1|B)。
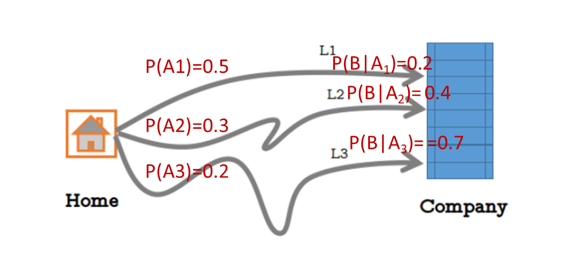
其中:
- P(A1)、P(A2)、P(A3)为先验概率
- 加入新的条件,即上班迟到了P(B)
- P(A1|B)为后验概率
全概率公式:
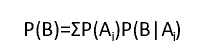
随机事件A1,A2,…An构成完备事件(互斥,且至少有一个发生),随机事件B伴随着该完备事件的发生而发生
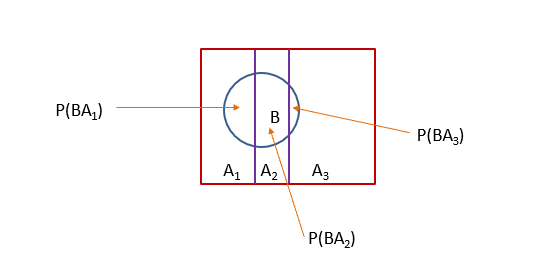
故:
迟到的概率

迟到且采用打车方式上班的概率
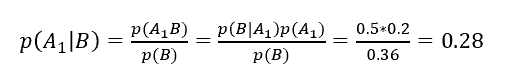
2. 贝叶斯分类器
朴素贝叶斯方法是基于贝叶斯定理的一组有监督学习算法,即“简单”地假设每对特征之间相互独立。 给定一个类别 y 和一个从 x_1 到 x_n 的相关的特征向量, 贝叶斯定理阐述了以下关系:
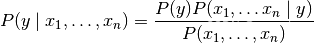
使用简单(naive)的假设-每对特征之间都相互独立:
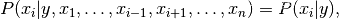
对于所有的 :i 都成立,这个关系式可以简化为
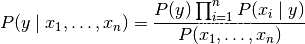
由于在给定的输入中 P(x_1, \dots, x_n) 是一个常量,我们使用下面的分类规则:

我们可以使用最大后验概率(Maximum A Posteriori, MAP) 来估计 P(y) 和 P(xi | y) ; 前者是训练集中类别 y 的相对频率。
各种各样的的朴素贝叶斯分类器的差异大部分来自于处理 P(xi | y)分布时的所做的假设不同。
尽管其假设过于简单,在很多实际情况下,朴素贝叶斯工作得很好,特别是文档分类和垃圾邮件过滤。这些工作都要求 一个小的训练集来估计必需参数。
相比于其他更复杂的方法,朴素贝叶斯学习器和分类器非常快。 分类条件分布的解耦意味着可以独立单独地把每个特征视为一维分布来估计。这样反过来有助于缓解维度灾难带来的问题。
另一方面,尽管朴素贝叶斯被认为是一种相当不错的分类器,但却不是好的估计器(estimator),所以不能太过于重视从 predict_proba 输出的概率。
朴素贝叶斯分类器是一种有监督学习,常见有五种算法,这五种算法适合应用在不同的数据场景下,我们应该根据特征变量的不同选择不同的算法,下面是一些常规的区别和介绍。
2.1. 高斯朴素贝叶斯
GaussianNB 实现了运用于分类的高斯朴素贝叶斯算法,特征的可能性(即概率)假设为高斯分布,适用于连续变量。
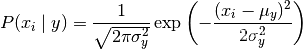
2.2. 多项分布朴素贝叶斯
MultinomialNB 实现了服从多项分布数据的朴素贝叶斯算法,适用于离散变量。在计算先验概率和条件概率时,使用平滑过的最大似然估计法来估计,为在学习样本中没有出现的特征而设计,以防在将来的计算中出现0概率输出。
2.3. 补充朴素贝叶斯
ComplementNB 实现了补充朴素贝叶斯(CNB)算法。CNB是标准多项式朴素贝叶斯(MNB)算法的一种改进,适用于不平衡数据集。具体来说,CNB使用来自每个类的补数的统计数据来计算模型的权重。CNB的发明者的研究表明,CNB的参数估计比MNB的参数估计更稳定。此外,CNB在文本分类任务上通常比MNB表现得更好(通常有相当大的优势)。
2.4. 伯努利朴素贝叶斯
BernoulliNB 实现了用于多重伯努利分布数据,要求样本以二元值特征向量表示,如果样本含有其他类型的数据, 一个 BernoulliNB 实例会将其二值化(取决于 binarize 参数)。
伯努利朴素贝叶斯的决策规则基于:
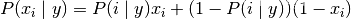
与多项分布朴素贝叶斯的规则不同 伯努利朴素贝叶斯明确地惩罚类 y 中没有出现作为预测因子的特征 i ,而多项分布分布朴素贝叶斯只是简单地忽略没出现的特征。
2.5. 基于外存的朴素贝叶斯模型拟合
朴素贝叶斯模型可以解决整个训练集不能导入内存的大规模分类问题。 为了解决这个问题, MultinomialNB, BernoulliNB, 和 GaussianNB 实现了 partial_fit 方法,可以动态的增加数据,使用方法与其他分类器的一样,使用示例见 Out-of-core classification of text documents 。所有的朴素贝叶斯分类器都支持样本权重。
与 fit 方法不同,首次调用 partial_fit 方法需要传递一个所有期望的类标签的列表。
3.代码示例
本例使用高斯朴素贝叶斯分类器对iris数据集进行花分类,具体代码如下:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
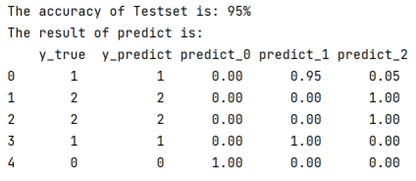
from sklearn import datasetsclass bayes_model():def __int__(self):passdef load_data(self):data = datasets.load_iris()iris_target = data.targetiris_features = pd.DataFrame(data=data.data, columns=data.feature_names)train_x, test_x, train_y, test_y = train_test_split(iris_features, iris_target, test_size=0.3, random_state=123)return train_x, test_x, train_y, test_ydef train_model(self, train_x, train_y):clf = GaussianNB()clf.fit(train_x, train_y)return clfdef proba_data(self, clf, test_x, test_y):y_predict = clf.predict(test_x)y_proba = clf.predict_proba(test_x)accuracy = metrics.accuracy_score(test_y, y_predict) * 100tot1 = pd.DataFrame([test_y, y_predict]).Ttot2 = pd.DataFrame(y_proba).applymap(lambda x: '%.2f' % x)tot = pd.merge(tot1, tot2, left_index=True, right_index=True)tot.columns=['y_true', 'y_predict', 'predict_0', 'predict_1', 'predict_2']print('The accuracy of Testset is: %d%%' % (accuracy))print('The result of predict is: \n', tot.head())return accuracy, totdef exc_p(self):train_x, test_x, train_y, test_y = self.load_data()clf = self.train_model(train_x, train_y)res = self.proba_data(clf, test_x, test_y)return resif __name__ == '__main__':bayes_model().exc_p()
部分结果截图: