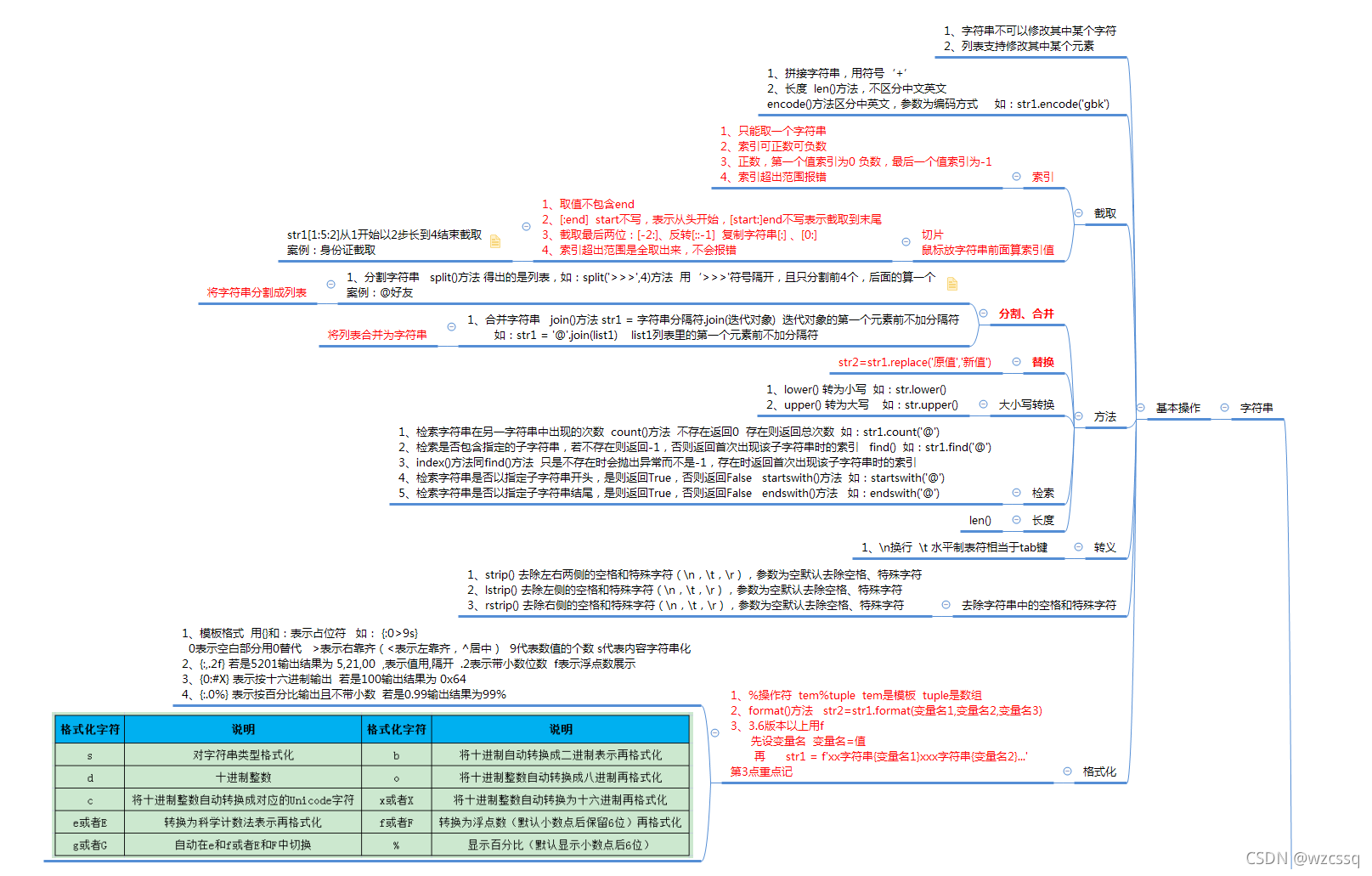
总结(重点记):
一、索引、切片:
1、索引,从0开始,可为负数,超出范围则报错
2、切片,v[start:end],也可负数,但很少用,step步长,也很少用
3、可省略,v[start:]从start到末尾 v[:end]从开头到倒数第二个、v[:]、v[0:]取所有,复制字符串
4、反转 v[::-1],字符串反写
二、字符串方法:
1、split()分割 join() 合并拼接 replace() 替换
三、格式化:
1、f 、format()
四、转义字符:
1、\n换行 \t相当于tab键,水平制表符
详细说明:
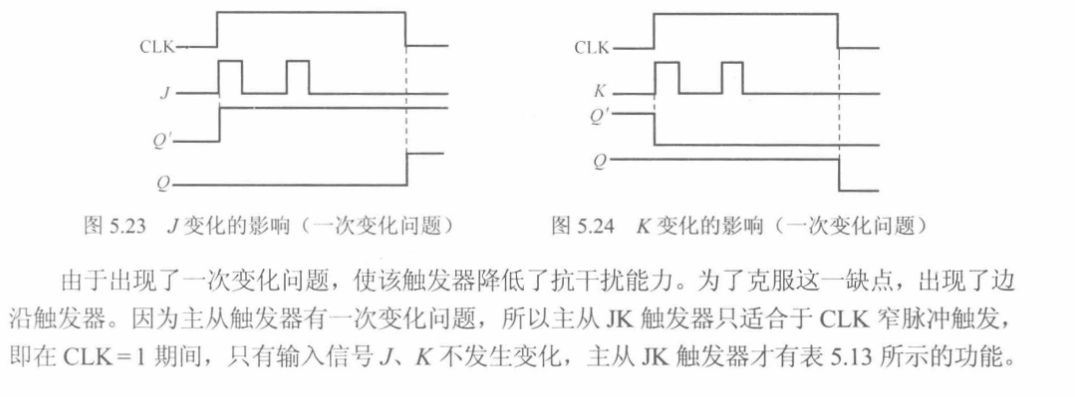
一、拼接、重复
只要是数据左右两边有引号,就是字符串(多行注释内容也是字符串,只是没被变量存储)
字符串之间用 + 相连可拼接,若是 * 则表示乘以几,可重复显示多个
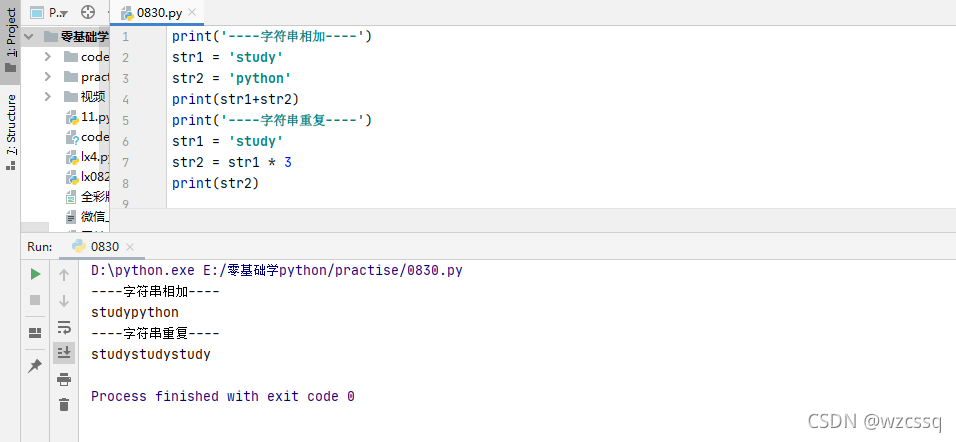
二、索引
字符串每个元素的编号,从0开始,每次只能取一个字符,可为负数;从开头数是正数,0开头,从后面开始数是负数,-1开头
1、格式:v[key] 如:v[1]
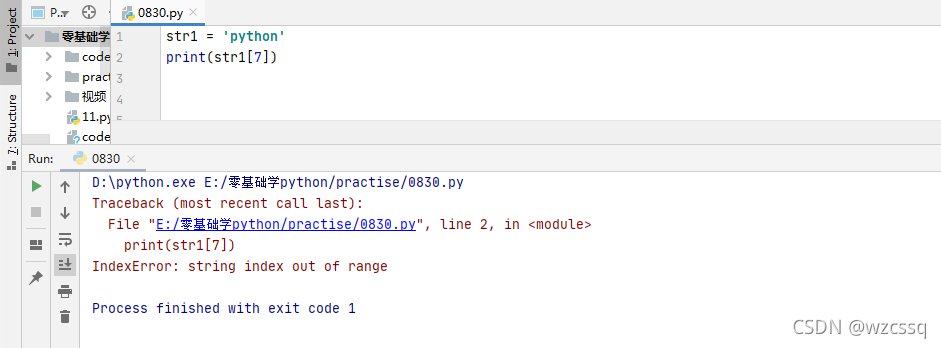
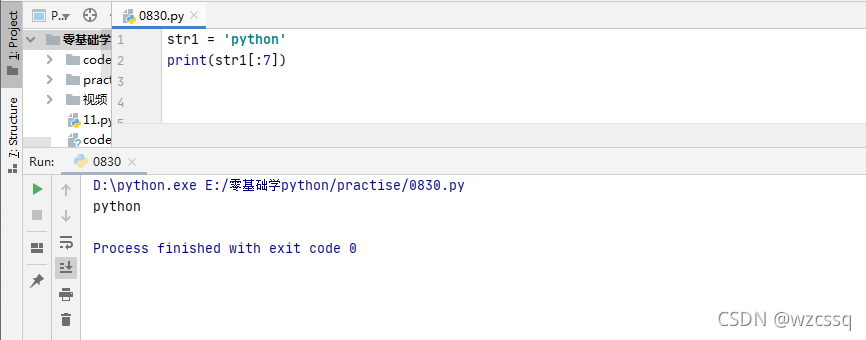
例:str1 = python,索引如下
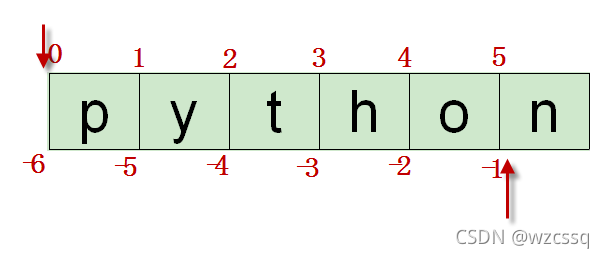
2、若取字符“y”则为str1[1]
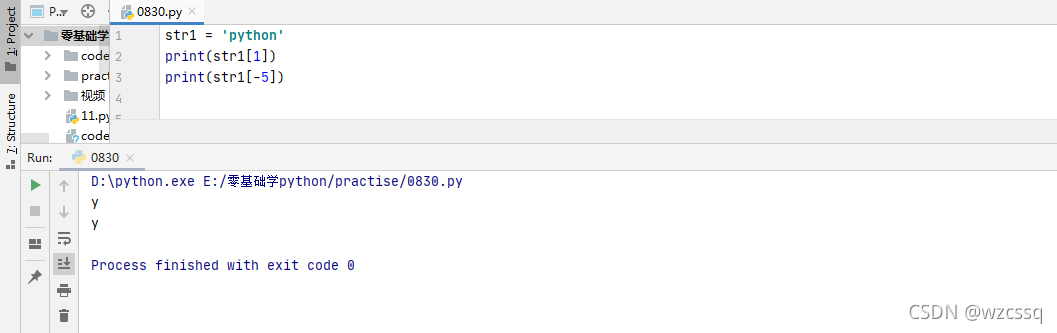
3、若索引超出范围则报错
三、切片
每次可以取一个或多个字符,可为负数
1、格式:v[start:end:step],表示从start开始以step步长到end-1结束取,不取end,顾头不顾尾,start、end、step均可省略,step默认省略时默认为1
注:第一个字符的索引是0
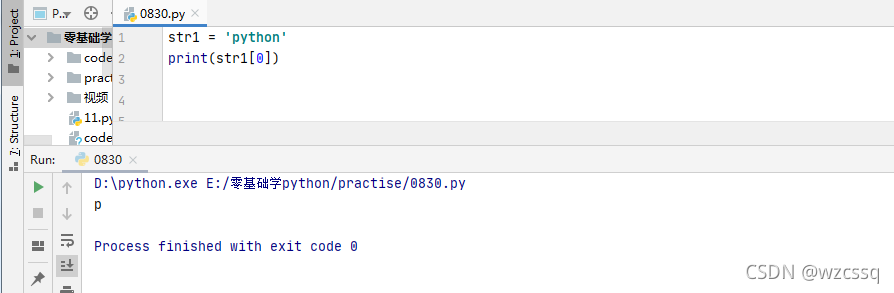
2、v[start:]表示,从start开始到末尾全取
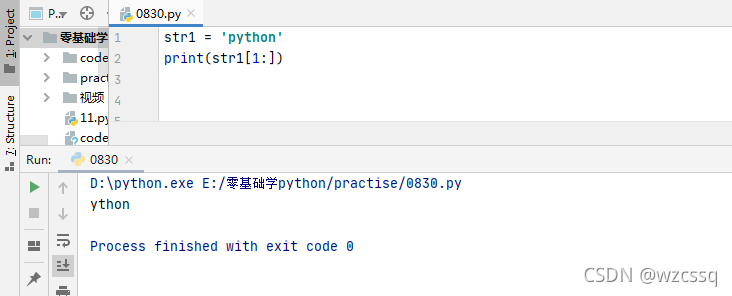
3、v[:end]表示,从开头开始到end-1结束
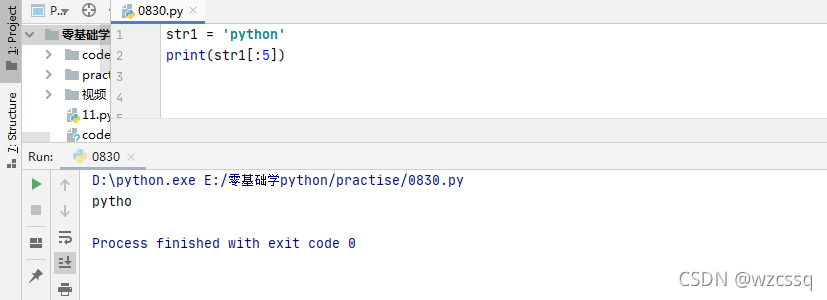
4、v[:]、v[0:]表示全取,复制字符串
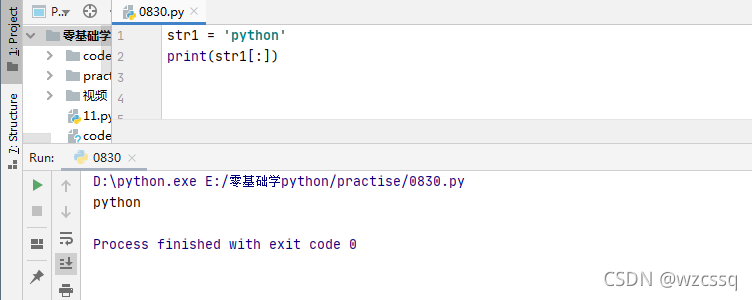
5、v[::-1]表示将字符串反写
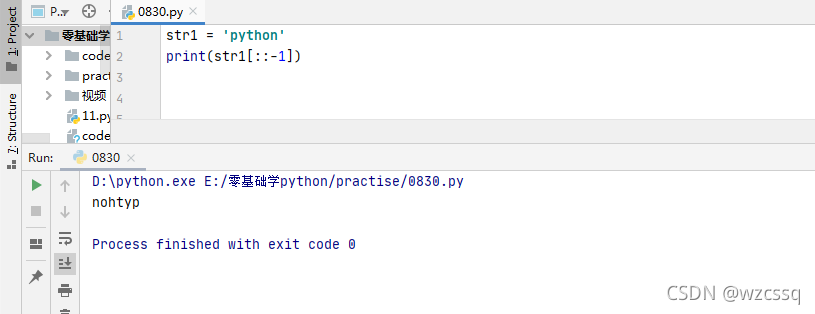
6、v[-2:]表示截取最后两位
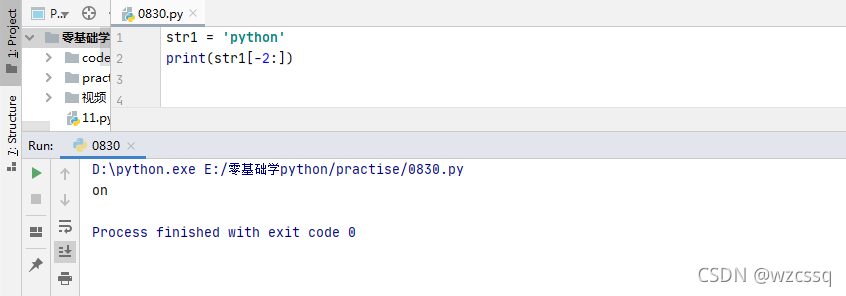
7、负数时,start要小于end,否则取出空,啥也取不出来
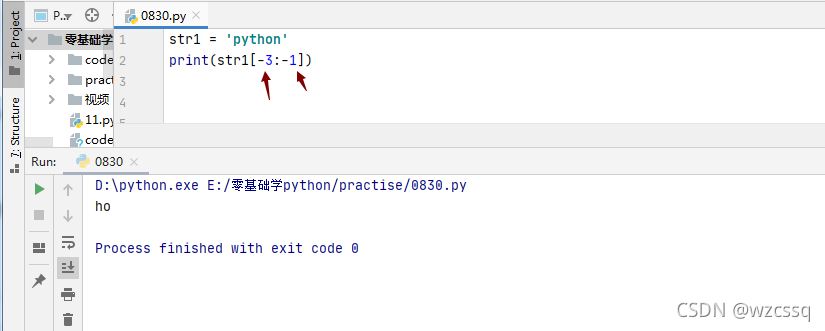
8、若索引超出范围不会报错,会将所有的字符取出
四、方法
字符串方法,即:字符串操作
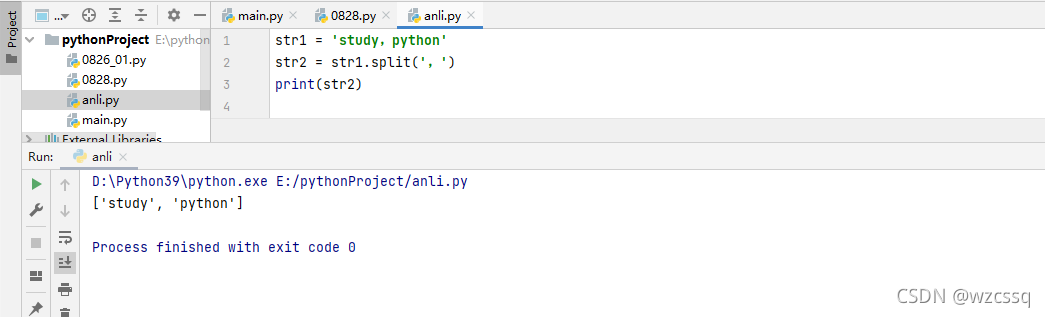
1、split() 分割,按分隔符分割,分成多段,将字符串分割后变为列表,一次只能指定一个字符分割
格式:new_list = old_str.split('分隔符号')
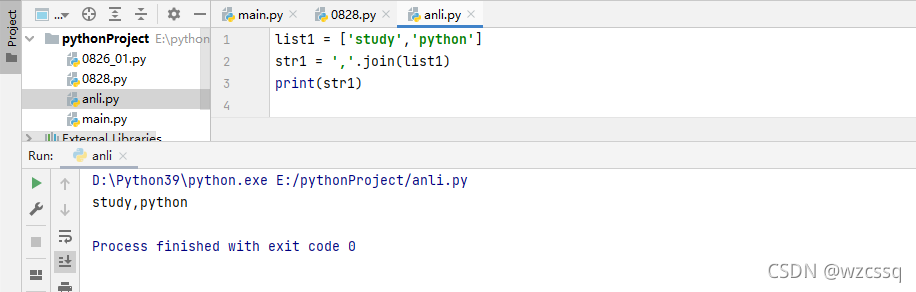
2、join() 合并,将列表按合并符合并,将一个列表拼接为字符串,一次只能指定一个合并符
格式:str1 = '拼接符号'.join(list1)
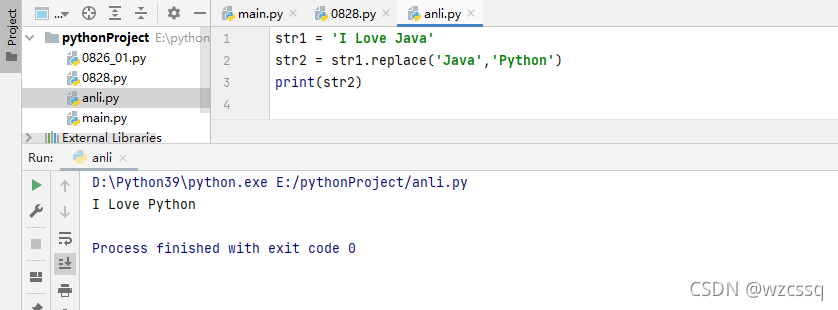
3、replace() 替换,替换某个字符
格式:new_str = old_str.replace('旧值','新值')
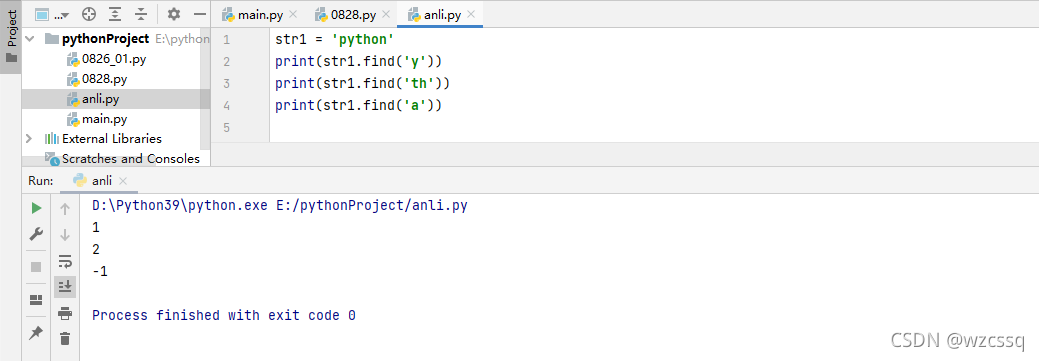
4、find() 从字符串中找出某个子字符串,返回该子字符串在该字符串中的索引值,若是多个字符(在字符串中也必须是连续的才符合)则返回首字符所在的索引值,若找不到则返回-1
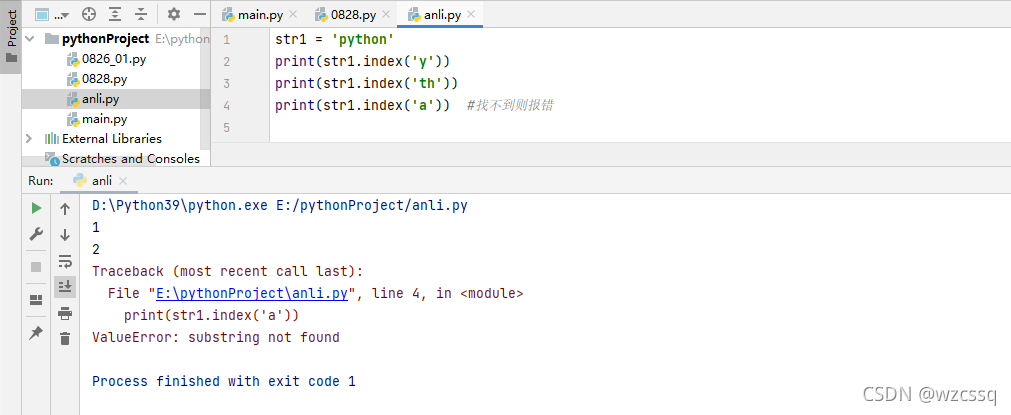
5、index() 找到某字符再字符串中的索引值,与find()的区别是,若index()找不到则报错
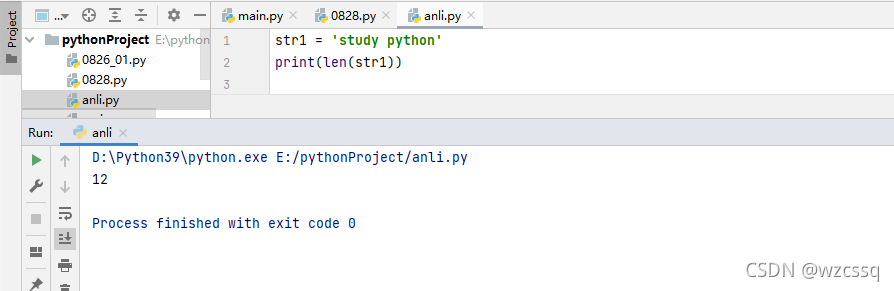
 6、len() 长度,返回字符串长度
6、len() 长度,返回字符串长度
7、upper() 将字符串转化为大写 lower() 将字符串转化为小写
格式:str1.upper() str1.lower()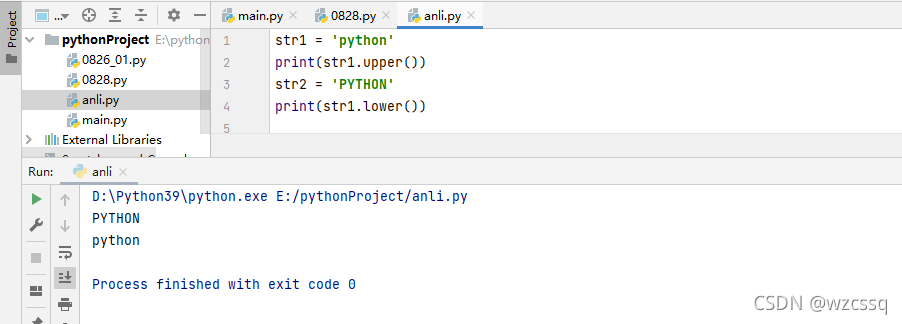
五、格式化
格式化,给一个模板取获取动态的字符串,值可以随时修改
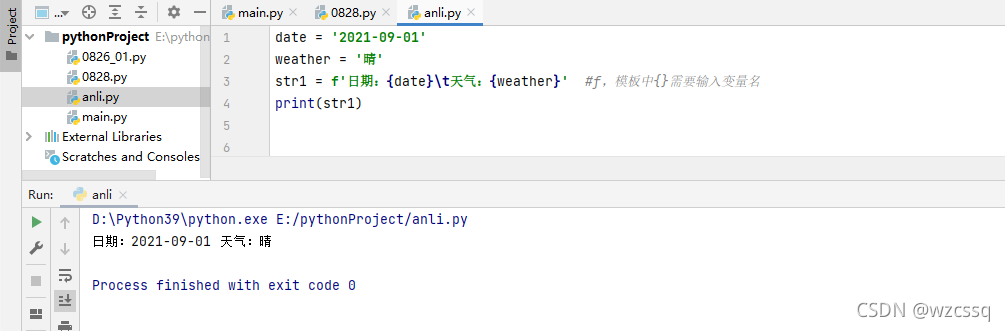
1、f 先用变量存储值,然后设置模板,用占位符{}输入变量名,python3.6版本以后开始使用
格式:str1 = f'字符串xxx{变量名1}字符串xxx{变量名2}...{变量名n}'
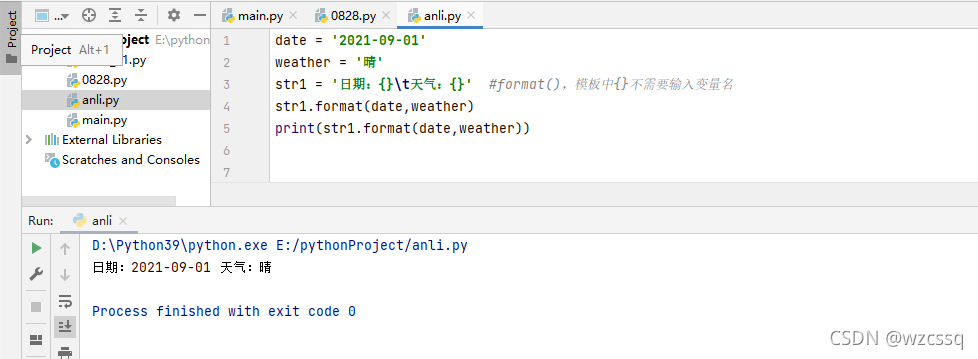
2、format() 模板中的{}占位符不需要输入值,代表的变量要与format()传参的变量位置保持一致
格式:str2 = str1.format(变量名1,变量名2....变量名n)
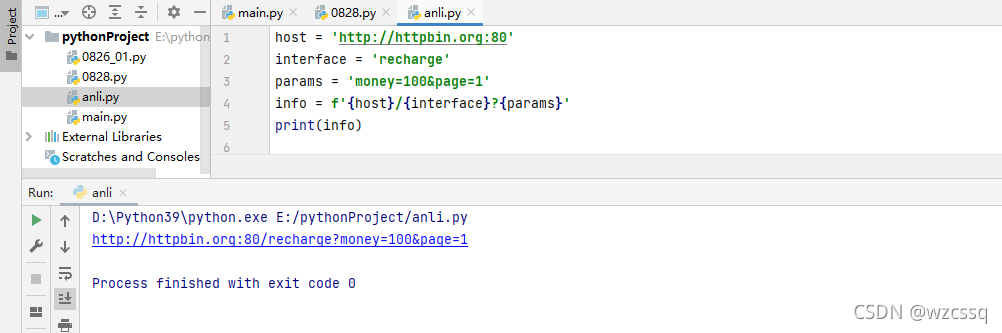
3、自动化测试场景:
url中是大致由协议、域名、端口号、接口、参数组成(暂时将协议、域名、端口号看成一组,整体由3部分组成)可以自由更改url里的值
url = 'http://httpbin.org:80/recharge?money=100&page=1'
host = 'http://httpbin.org:80'
interface = 'recharge'
params = 'money=100&page=1'
info = f'{host}//{interface}?{params}'
print(info)
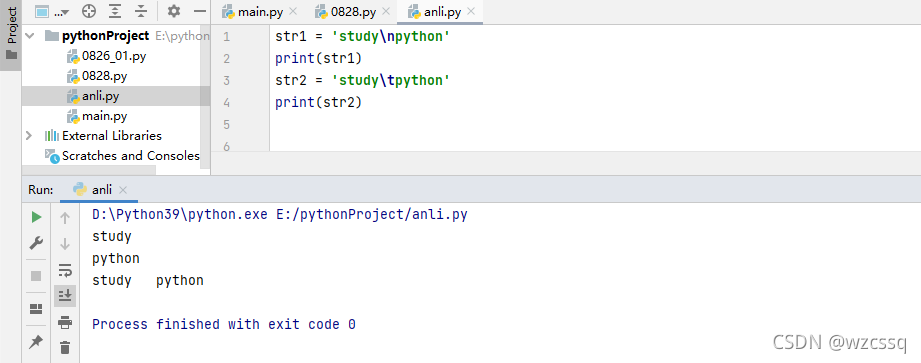
六、转义字符
1、\n换行 \t水平制表符,相当于tab键
整体归纳: