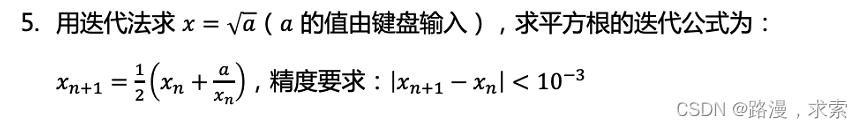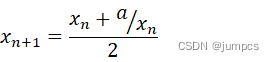目录
1. 拓扑排序
2. 拓扑排序存在的前提
3. 拓扑排序的唯一性问题
4. 拓扑排序算法原理
4.1 广度优先遍历
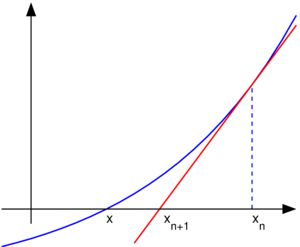
4.2 深度优先遍历
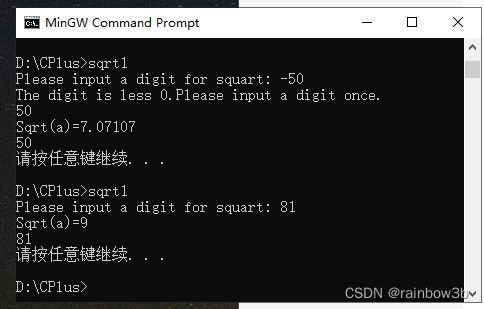
5. 代码实现
5.1 Graph类的实现
5.2 广度优先搜索
5.3 深度优先搜索简易版(无loop检测)
5.4 深度优先搜索完整版
5.5 测试
参考
1. 拓扑排序
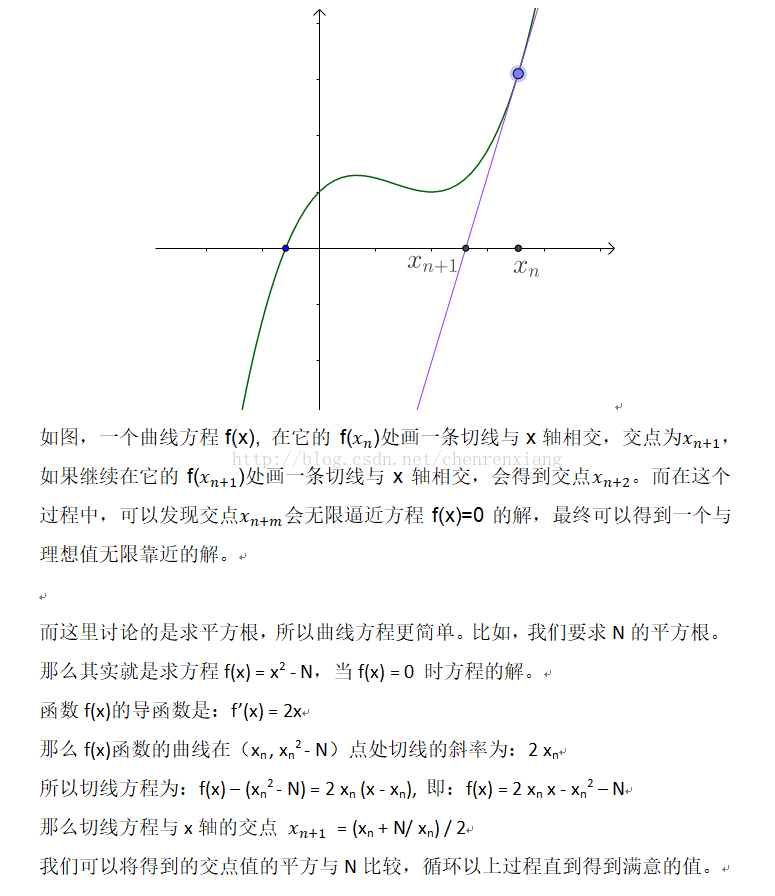
对一个有向无环图(Directed Acyclic Graph简称DAG)G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边<u,v>∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序(Topological Order)的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
拓扑排序主要用来解决有向图中的依赖解析(dependency resolution)问题。
举例来说,如果我们将一系列需要运行的任务构成一个有向图,图中的有向边则代表某一任务必须在另一个任务之前完成这一限制。那么运用拓扑排序,我们就能得到满足执行顺序限制条件的一系列任务所需执行的先后顺序。当然也有可能图中并不存在这样一个拓扑顺序,这种情况下我们无法根据给定要求完成这一系列任务,这种情况称为循环依赖(circular dependency)。
例1:如下图所示为一个有向图。
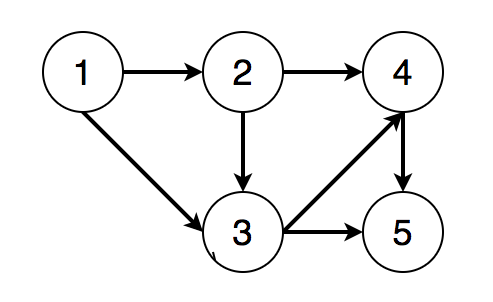
根据图中的边的方向,我们可以看出,若要满足得到其拓扑排序,则结点被遍历的顺序必须满足如下要求:
- 结点1必须在结点2、3之前
- 结点2必须在结点3、4之前
- 结点3必须在结点4、5之前
- 结点4必须在结点5之前
则一个满足条件的拓扑排序为[1, 2, 3, 4, 5]。
2. 拓扑排序存在的前提
当且仅当一个有向图为有向无环图(directed acyclic graph,或称DAG)时,才能得到对应于该图的拓扑排序。每一个有向无环图都至少存在一种拓扑排序。该论断可以利用反证法证明如下:
假设我们有一由到
这n个结点构成的有向图,且图中
这些结点构成一个环。这即是说对于所有
1≤i<n-1,图中存在一条有向边从指向
。同时还存在一条从
指向
的边。假设该图存在一个拓扑排序。
那么基于这样一个有向图,显然我们可以得知对于所有1≤i<n-1,必须在
之前被遍历,也就是
必须在
之前被遍历。同时由于还存在一条从
指向
的边,
必须在
之前被遍历。这里出现了与我们的假设所冲突的结果。因此我们可以知道,该图存在拓扑排序的假设不成立。也就是说,对于非有向无环图而言,其拓扑排序不存在。
3. 拓扑排序的唯一性问题
一般地来说,拓扑排序不一定是唯一的。
例2:将例1中的图删去图中4、5结点之前的有向边,上图变为如下所示:
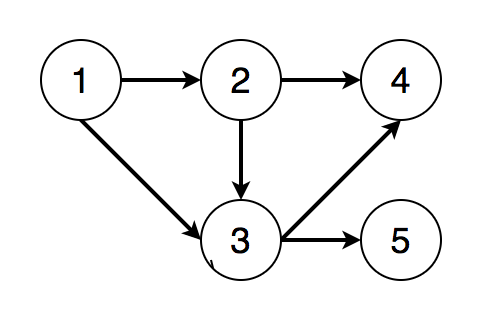
可以得到两个不同的拓扑排序结果:[1, 2, 3, 4, 5]和[1, 2, 3, 5, 4]。
4. 拓扑排序算法原理
为了说明如何得到一个有向无环图的拓扑排序,我们首先需要了解有向图结点的入度(indegree)和出度(outdegree)的概念。
假设有向图中不存在起点和终点为同一结点的有向边。
入度:设有向图中有一结点v,其入度即为当前所有从其他结点出发,终点为v的的边的数目。也就是所有指向v的有向边的数目。
出度:设有向图中有一结点v,其出度即为当前所有起点为v,指向其他结点的边的数目。也就是所有由v发出的边的数目。
在了解了入度和出度的概念之后,再根据拓扑排序的定义,我们自然就能够得出结论:要想完成拓扑排序,我们每次都应当从入度为0的结点开始遍历。因为只有入度为0的结点才能够成为拓扑排序的起点。否则根据拓扑排序的定义,只要一个结点v的入度不为0,则至少有一条边起始于其他结点而指向v,那么这条边的起点在拓扑排序的顺序中应当位于v之前,则v不能成为当前遍历的起点。
拓扑排序可以用深度优先遍历或广度优先遍历算法来实现。
4.1 广度优先遍历
与普通的广度优先遍历唯一的区别在于需要维护每一个节点对应的入度,并在遍历的每一层时选取入度为0的节点开始遍历(而普通的广度优先遍历则无此限制,可以从每一层任意一个节点开始遍历)。这个算法描述如下:
- 统计图的每一个节点的入度存储与数组inDegree。
- 选取入度为0的节点加入队列
- 从队列中取出一个节点,
- (a) 将该节点加入输出
- (b) 将该节点的所有邻接点的入度树减1,减1后入度数变为0的节点加入队列
- 重复步骤3,直到遍历完所有的结点。
- 如果无法遍历完所有的结点,则意味着当前的图不是有向无环图。不存在拓扑排序。
由于只有入度为0的节点才会被放入队列,当存在环时,环上的节点将不会放入队列,因此不会出现在最终的拓扑排序中。比如说,在示例2的图中添加一条从节点5到节点2的边,图中出现一个环:2-->3-->5-->2。
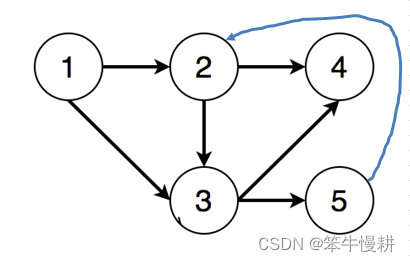
搜索过程将如下所示:
- (1)由于只有1的入度为0,将1放入队列
- (2)从队列中取出1并放入输出拓扑排序列表
- (3)将节点1的两个邻接节点2和3的入度减1,但是由于存在环路,所以它们的入度没有变为0,因此不会放入队列。
- (4)由于队列为空,所以搜索结束
这样最终排序输出中只有节点1。
事实上,在基于广度优先搜索的拓扑排序中,可以根据最终拓扑排序输出列表的长度是否等于图的节点数,来判断输入图是否存在拓扑排序。详细参见以下实现代码。
时间复杂度: ,其中
n为图中的结点数目,e为图中的边的数目
空间复杂度:
4.2 深度优先遍历
使用深度优先搜索实现拓扑排序的基本思想是:对于一个特定节点,如果该节点的所有相邻节点都已经搜索完成,则该节点也会变成已经搜索完成的节点,在拓扑排序中,该节点位于其所有相邻节点的前面。一个节点的相邻节点指的是从该节点出发通过一条有向边可以到达的节点。
由于拓扑排序的顺序和搜索完成的顺序相反,因此需要使用一个栈存储所有已经搜索完成的节点。深度优先搜索的过程中需要维护每个节点的状态,每个节点的状态可能有三种情况:
- 0:未访问;
- 1:访问中;
- 2:已访问;
初始时,所有节点的状态都是「未访问」。
每一轮搜索时,任意选取一个「未访问」的节点 u,从节点 u 开始深度优先搜索。将节点 u 的状态更新为「访问中」,对于每个与节点 u 相邻的节点 v,判断节点 v 的状态,执行如下操作:
如果节点 v 的状态是「未访问」,则继续搜索节点 v;
如果节点 v 的状态是「访问中」,则找到有向图中的环,因此不存在拓扑排序;
如果节点 v 的状态是「已访问」,则节点 v 已经搜索完成并加入输出排序列表,节点 u 尚未完成搜索,因此节点 u 的拓扑顺序一定在节点 v 的前面,不需要执行任何操作。
当节点 u 的所有相邻节点的状态都是「已访问」时,将节点 u 的状态更新为「已访问」,并将节点 u 加入输出排序列表。
当所有节点都访问结束之后,如果没有找到有向图中的环,则存在拓扑排序,所有节点从栈顶到栈底的顺序即为拓扑排序。
5. 代码实现
实现方面,如果图的节点数比较少的话,可以直接用一个数组来表示队列或者栈(以下示例代码中就是这么实现的)。但是如果图的规模很大,特别是对于非显式的图的搜索,节点数未知但是输入问题规模很大,则需要用真正的队列或者栈的结构来实现,比如说python中的deque。
5.1 Graph类的实现
首先,实现图数据结构,用于后面构建图并用于算法测试。
from collections import defaultdictclass Graph:def __init__(self, isDirected=False):# 以邻接表的方式表示一张图self.graph = defaultdict(list)self.isDirected = isDirecteddef addEdge(self, start, end):
# =============================================================================
# 添加一条边
# =============================================================================# 将end添加到start节点的邻接表self.graph[start].append(end)if self.isDirected is False:# 如果是无向图,则双向追加。这个与拓扑排序无关,是作为一般的图构建方法放在这里的。self.graph[end].append(start)else:self.graph[end] = self.graph[end]5.2 广度优先搜索
基于广度优先搜索的拓扑排序算法的实现(作为以上Graph类的方法,当然作为独立函数实现也可以)。基于广度优先搜索的拓扑排序是按照正常顺序确定各节点的拓扑排序的。
def topoSortBfs(self):# 查询统计各节点的入度inDeg = {node:0 for node in self.graph}for node in self.graph:for adj in self.graph[node]:inDeg[adj] += 1# 用一个list来简单地模拟队列# 首先将所有入度为0的节点加入队列q = [node for node, d in inDeg.items() if d == 0]for u in q:# 顺序遍历u,模拟逐个从队列头部中取出各节点并移除的操作for v in self.graph[u]:# 遍历u的各邻节点,由于u被移除,所以v的入度相应减一。# 如果减一后v的入度也变为0了就将v也加入队列(添加到表的尾部)inDeg[v] -= 1if inDeg[v] == 0:q.append(v)if len(q) < len(self.graph): return Nonereturn q5.3 深度优先搜索简易版(无loop检测)
当确定输入图是一定存在拓扑排序的话,可以以更简单的方式实现,各节点的状态只需要分“未访问”和“已访问”两种状态。
def topoSortvisit0(self, s, visited, sortlist):visited[s] = Truefor i in self.graph[s]:if not visited[i]:self.topoSortvisit0(i, visited, sortlist)sortlist.insert(0, s)def topoSortDfs0(self):visited = {i: False for i in self.graph}sortlist = []for u in self.graph:if not visited[u]:self.topoSortvisit0(u, visited, sortlist)return sortlist当输入图有可能不存在拓扑排序时,这个函数返回的结果不正确。
5.4 深度优先搜索完整版
当不能确定输入的图是否存在拓扑排序时,搜索排序算法需要能够做出正确的判断。这就需要在算法中加入loop是否存在的检测。实现代码如下:
def topoSortvisit1(self, s, visited, sortlist):visited[s] = 1 #将节点s的状态置为“访问中”succ = Truefor i in self.graph[s]:# 遍历节点s的邻接节点if 0 == visited[i]:succ = succ and self.topoSortvisit1(i, visited, sortlist)elif 1 == visited[i]:# 找到一个环路,不存在拓扑排序return Falseif succ:# 针对当前节点的所有邻接点的搜索都成功结束,意味着所有邻接点都已经加入拓扑排序列表# 将当前节点置为“已访问”并将它加入拓扑排序列表。visited[s] = 2 #将节点s的状态置为“已访问”sortlist.insert(0, s) # 注意是插入到表头return Trueelse:return Falsedef topoSortDfs1(self):# 所有节点状态初始化为“未访问”visited = {i: 0 for i in self.graph}sortlist = []for u in self.graph:# 最外层是对每个节点进行遍历,不会出现重复。# 中途检测到从任何一个节点出发拓扑排序失败(检测到环)的话,都算失败。if 0 == visited[u]:if not self.topoSortvisit1(u, visited, sortlist):return Nonereturn sortlist5.5 测试
if __name__ == '__main__':g = Graph(isDirected=True)g.addEdge(1, 2)g.addEdge(1, 3)g.addEdge(2, 4)g.addEdge(2, 5)g.addEdge(3, 4)g.addEdge(3, 6)g.addEdge(4, 6)# Testcase1print("\nTestcase1 ... ")print("topological Sort:", g.topoSortDfs0())print("topological Sort:", g.topoSortDfs1())print("topological Sort:", g.topoSortBfs())# Testcase2print("\nTestcase2 ... ")g.addEdge(3, 2)print("topological Sort:", g.topoSortDfs0())print("topological Sort:", g.topoSortDfs1())print("topological Sort:", g.topoSortBfs())# Testcase3print("\nTestcase3 ... ")g.addEdge(4, 2)print("topological Sort:", g.topoSortDfs0())print("topological Sort:", g.topoSortDfs1())print("topological Sort:", g.topoSortBfs())以上三个testcase的输入的图分别如下所示:
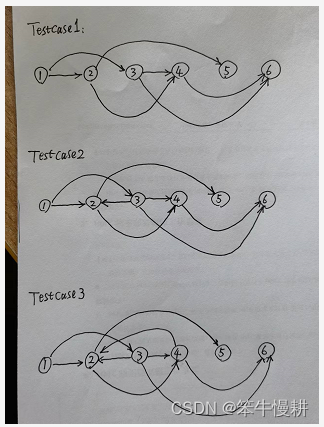
运行结果如下:
Testcase1 ...
topological Sort: [1, 3, 2, 5, 4, 6]
topological Sort: [1, 3, 2, 5, 4, 6]
topological Sort: [1, 2, 3, 5, 4, 6]Testcase2 ...
topological Sort: [1, 3, 2, 5, 4, 6]
topological Sort: [1, 3, 2, 5, 4, 6]
topological Sort: [1, 3, 2, 4, 5, 6]Testcase3 ...
topological Sort: [1, 3, 2, 5, 4, 6]
topological Sort: None
topological Sort: None
Testcase1和Testcase2的图是可拓扑排序的,三种实现方法都给出了正确结果,但是可以看出,广度优先搜索方案和深度优先搜索方案给出的结果是不一样的,但是,都是合法的。 比如说,在第1个图中,节点3和节点2之间没有确定的顺序要求,两种算法给出的结果就不一样。
Testcase3(在第2个图的基础上追加了一条边,形成了环路)是不可拓扑排序的。但是深度优先搜素简易版因为没有环路判别对策,因此仍然给出一个错误的拓扑排序。而深度优先搜素完整版以及广度优先搜索方法则做出了正确的判断。
在leetcode中有一些拓扑排序的题目,比如:
210. 课程表 II - 力扣(LeetCode)
剑指 Offer II 114. 外星文字典(difficult)
等
参考
1. 百度百科——全球领先的中文百科全书
2. Topological Sorting in Python with Algorithm - CodeSpeedy
3. https://www.jianshu.com/p/3347f54a3187
4. https://leetcode.cn/problems/Jf1JuT/solution/wai-xing-wen-zi-dian-by-leetcode-solutio-to66/