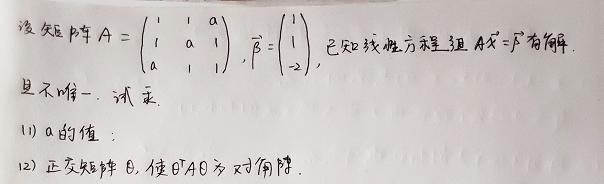什么是delegation token
delegation token其实就是hadoop里一种轻量级认证方法,作为kerberos认证的一种补充。理论上只使用kerberos来认证是足够了,为什么hadoop还要自己开发一套使用delegation token的认证方式呢?这是因为如果在一个很大的分布式系统当中,如果每个节点访问某个服务的时候都使用kerberos来作为认证方式,那么势必对KDC造成很大的压力,KDC就会成为一个系统的瓶颈。
与kerberos的区别
kerberos认证需三方参与,client, kdc, server三方协作完成认证。通常包括三个子过程:
- client向kdc申请TGT(Ticket Granting Ticket),TGT包含client信息及client和KDC之间的 session key两部分信息,并且使用KDC的master key加密
- client使用TGT向KDC申请访问某个服务的Ticket,Ticket包含client信息及client和server之间的session key两部分信息,并且使用server的master key加密。
- client使用Ticket访问某个服务。
Delegation token的认证只需要两方参与,client和server。在server端生成token并发送给client端。client使用该token访问server,server对该token进行认证。
Delegation token可以传递给其它服务使用,这也是它叫delegation token的原因。比如在client端获取到hdfs delegation token后,可以分发到Mapper端和Reducer端。这样Map,Reduce就不用在通过Kerberos认证而直接使用该token访问hdfs。同时,delegation token可以指定更新者(renewer),比如yarn,或者自己。token快要过期的时候需要更新,更新的时候只涉及更新者和server端。其它任何使用该token的人都不会受到影响。
delegation token 期限
delegation token有过期时间,需要定期刷新才能保证token有效。但是刷新次数不是无限的,也就是说每个token都有个最大生存时间,超过该时间,该token就失效。比如token每个24小时需要刷新一次,否则就失效。同时每个token最大生命值为7天,那么七天后该token就不能在被使用。
delegation 包含的内容
Token.java
private byte[] identifier;private byte[] password;private Text kind;private Text service;private TokenRenewer renewer;
其中identifiertoken的标识,password用于server端认证该token。kind参数表示该token的类型,比如HDFS_DELEGATION_TOKEN,service表示该token访问的服务,比如ha-hdfs:,renewer表示刷新者。
以上几个部分是client拿到的token包含的内容。token的失效时间、owner、realuser等信息存放在server端。
delegation 生命周期

上图展示了在yarn应用中,delegation token的生命流程。
1)client端首先通过Kerberos 认证方式访问namenode,获取DT(delegation token)
2)client向yarn提交应用,并且把DT传给RM。同时会指定yarn作为该token的renewer。
3)rm选一个节点启动Am,随后AM向RM申请资源,将worker contaiern都启动。这一步中DT都会分发到相应的container中。
4)所有的工作节点都使用DT去访问hdfs
5)当工作结束后,RM释放该DT。
delegation token过期应该怎么办
delegation token会失效,集群默认配置是renew的间隔为一天,token最大生存时间为7天。对于像mapreduce这种批处理任务可能不会面临token失效的问题,但对于spark streaming, storm等这种长时运行应用来说,不得不面临一个问题:token存在最大生命周期。当token达到其最大生命周期的时候,比如七天,所有的工作节点(比如spark streaming的executor)中使用的token都会失效,此时在使用该token去访问hdfs就会被namenode拒绝,导致应用异常退出。
一种解决思路是将keytab文件分发给Am及每个container,让am和container去访问kdc来认证,但这种方式会造成文章开头所说的问题:对KDC造成很大的访问压力,导致KDC会误认为自己遭受了DDos攻击,从而影响程序性能。
另一种解决思路是先由client把keytab文件放到hdfs上。然后在Am中使用keytab登录,并申请delegation token。Am在启动worker的时候把该token分发给相应的容器。当token快要过期的时候,Am重新登录一次,并重新获取delegation token,并告知所有的worker使用更新后的token访问服务。
spark中怎么解决delegation token过期问题
spark使用的就是第二种解决思路,接下来详细分析下spark1.6是怎么解决token过期问题的。
spark 为了解决DT失效问题,加了两个参数"–keytab"和"–principal",分别指定用于kerberos登录的keytab文件和principal。spark中用于提交yarn任务的类为Client
org.apache.spark.deploy.yarn.Client
def submitApplication(): ApplicationId = {var appId: ApplicationId = nulltry {launcherBackend.connect()// Setup the credentials before doing anything else,// so we have don't have issues at any point.setupCredentials()yarnClient.init(yarnConf)yarnClient.start()logInfo("Requesting a new application from cluster with %d NodeManagers".format(yarnClient.getYarnClusterMetrics.getNumNodeManagers))// Get a new application from our RMval newApp = yarnClient.createApplication()val newAppResponse = newApp.getNewApplicationResponse()appId = newAppResponse.getApplicationId()reportLauncherState(SparkAppHandle.State.SUBMITTED)launcherBackend.setAppId(appId.toString())// Verify whether the cluster has enough resources for our AMverifyClusterResources(newAppResponse)// Set up the appropriate contexts to launch our AMval containerContext = createContainerLaunchContext(newAppResponse)val appContext = createApplicationSubmissionContext(newApp, containerContext)// Finally, submit and monitor the applicationlogInfo(s"Submitting application ${appId.getId} to ResourceManager")yarnClient.submitApplication(appContext)appId} catch {case e: Throwable =>if (appId != null) {cleanupStagingDir(appId)}throw e}
submitApplication是提交yarn任务的入口,该函数的最开始调用了setupCredentials函数用于设置Credential。
def setupCredentials(): Unit = {loginFromKeytab = args.principal != null || sparkConf.contains("spark.yarn.principal")...// Defensive copy of the credentialscredentials = new Credentials(UserGroupInformation.getCurrentUser.getCredentials)}
先判断参数中是否包含“–principal”,如果包含,则成员变量logingFromKeytab置为true。这个成员变量用于后面的一些判断。另外就是获取当前ugi中包含的Credentials对象。
设置完credentials后,调用yarn的接口创建一个Application,并取得appid,然后需要创建containerLaunchContext,这是走的yarn程序的标准流程,进一步分析该函数
private def createContainerLaunchContext(newAppResponse: GetNewApplicationResponse): ContainerLaunchContext = {logInfo("Setting up container launch context for our AM")val appId = newAppResponse.getApplicationIdval appStagingDir = getAppStagingDir(appId)val pySparkArchives =if (sparkConf.getBoolean("spark.yarn.isPython", false)) {findPySparkArchives()} else {Nil}val launchEnv = setupLaunchEnv(appStagingDir, pySparkArchives)val localResources = prepareLocalResources(appStagingDir, pySparkArchives)// Set the environment variables to be passed on to the executors.distCacheMgr.setDistFilesEnv(launchEnv)distCacheMgr.setDistArchivesEnv(launchEnv)val amContainer = Records.newRecord(classOf[ContainerLaunchContext])amContainer.setLocalResources(localResources.asJava)amContainer.setEnvironment(launchEnv.asJava)...setupSecurityToken(amContainer)amContainer}
这个函数很长,省略了一些代码,主要是设置container启动的命令行,环境变量,classpath之类的东西。在setupLaunchEnv函数里设置了后期在Am中用于通知executor的credentials文件
private def setupLaunchEnv(stagingDir: String,pySparkArchives: Seq[String]): HashMap[String, String] = {...if (loginFromKeytab) {val remoteFs = FileSystem.get(hadoopConf)val stagingDirPath = new Path(remoteFs.getHomeDirectory, stagingDir)val credentialsFile = "credentials-" + UUID.randomUUID().toStringsparkConf.set("spark.yarn.credentials.file", new Path(stagingDirPath, credentialsFile).toString)logInfo(s"Credentials file set to: $credentialsFile")val renewalInterval = getTokenRenewalInterval(stagingDirPath)sparkConf.set("spark.yarn.token.renewal.interval", renewalInterval.toString)}...
}
先判断loginFromKeytab是否为true。在前面我们看到只要在命令行中使用了"–principal"参数,loginFromKeytab就为true,这里声明了用于存放token的文件位置,默认为hdfs上位于/user/{user}/.sparkSgating/{appid}目录下的以credentials开头的文件。并把该文件位置放在sparkConf中,key为“spark.yarn.credentials.file”,这在后边会用到。同时这里获取了DT renew的间隔。也同样放在sparkConf中,key为“spark.yarn.token.renewal.interval”。
设置完登录环境后,进入到另一个函数prepareLocalResources,这个函数里边有一个关键的步骤:获取hdfs
delegation token
YarnSparkHadoopUtil.get.obtainTokensForNamenodes(nns, hadoopConf,credentials)
def obtainTokensForNamenodes(paths: Set[Path],conf: Configuration,creds: Credentials,renewer: Option[String] = None): Unit = {if (UserGroupInformation.isSecurityEnabled()) {val delegTokenRenewer = renewer.getOrElse(getTokenRenewer(conf))paths.foreach { dst =>val dstFs = dst.getFileSystem(conf)logInfo("getting token for namenode: " + dst)dstFs.addDelegationTokens(delegTokenRenewer, creds)}}}
这个函数用于向namenode索取hdfs delegation token,并把该token添加到Credentials对象中。前面我们讲过,credentiasl对象的初值为UserGroupInformation.getCurrentUser.getCredentials, 而ugi中默认是不包含hdfs delegation token的。因此通过该函数会吧hdfs delegation token添加到credentials中。
然后回到createContainerLaunchContext, 准备工作都做好后,创建了amContainer,并调用setupSecurityToken函数给amContainer设置刚刚获取到的token。所以当Am起来后不需要通过kerberos认证,可以直接使用hdfs delegation token与namenode交互。
private def setupSecurityToken(amContainer: ContainerLaunchContext): Unit = {val dob = new DataOutputBuffercredentials.writeTokenStorageToStream(dob)amContainer.setTokens(ByteBuffer.wrap(dob.getData))}
至此,有关token的东西都准备好了,调用yarnClient.submitApplication(appContext)向yarn提交任务。yarn在收到请求后会先找一个机器启动AmContainer。yarn启动container的命令其实就是client传给yarn的。大概就是“bin/java xxx org.apache.spark.deploy.yarn.ApplicationMaster xxx”。Am的入口为ApplicationMaster的run函数。
org.apache.spark.deploy.yarn.ApplicationMaster
final def run(): Int = {try {...// If the credentials file config is present, we must periodically renew tokens. So create// a new AMDelegationTokenRenewerif (sparkConf.contains("spark.yarn.credentials.file")) {delegationTokenRenewerOption = Some(new AMDelegationTokenRenewer(sparkConf, yarnConf))// If a principal and keytab have been set, use that to create new credentials for executors// periodicallydelegationTokenRenewerOption.foreach(_.scheduleLoginFromKeytab())}if (isClusterMode) {runDriver(securityMgr)} else {runExecutorLauncher(securityMgr)}} catch {case e: Exception =>// catch everything else if not specifically handledlogError("Uncaught exception: ", e)finish(FinalApplicationStatus.FAILED,ApplicationMaster.EXIT_UNCAUGHT_EXCEPTION,"Uncaught exception: " + e)}exitCode}
这里看到了一个熟悉的配置“spark.yarn.credentials.file”, 还记得我们之前讲过该参数被设置为什么了吗?就是Am用于保存token文件的位置。所以,如果spark submit启动的时候传递了"–principal"参数,就会在sparkConf中生成一个“spark.yarn.credentials.file”配置,如果sparkConf中有“spark.yarn.credentials.file”配置,在AM中,也就是run函数中,会生成一个AMDelegationTokenRenewer对象。从名字也可以看出,这个对象就负责定期的更新token,将token写入到一个hdfs文件,然后executor从该文件中获取新的token从而防止token过期的作用了。
AMDelegationTokenRenewer
private[spark] def scheduleLoginFromKeytab(): Unit = {val principal = sparkConf.get("spark.yarn.principal")val keytab = sparkConf.get("spark.yarn.keytab")/*** Schedule re-login and creation of new tokens. If tokens have already expired, this method* will synchronously create new ones.*/def scheduleRenewal(runnable: Runnable): Unit = {val credentials = UserGroupInformation.getCurrentUser.getCredentialsval renewalInterval = hadoopUtil.getTimeFromNowToRenewal(sparkConf, 0.75, credentials)// Run now!if (renewalInterval <= 0) {logInfo("HDFS tokens have expired, creating new tokens now.")runnable.run()} else {logInfo(s"Scheduling login from keytab in $renewalInterval millis.")delegationTokenRenewer.schedule(runnable, renewalInterval, TimeUnit.MILLISECONDS)}}// This thread periodically runs on the driver to update the delegation tokens on HDFS.val driverTokenRenewerRunnable =new Runnable {override def run(): Unit = {try {writeNewTokensToHDFS(principal, keytab)cleanupOldFiles()} catch {case e: Exception =>// Log the error and try to write new tokens back in an hourlogWarning("Failed to write out new credentials to HDFS, will try again in an " +"hour! If this happens too often tasks will fail.", e)delegationTokenRenewer.schedule(this, 1, TimeUnit.HOURS)return}scheduleRenewal(this)}}// Schedule update of credentials. This handles the case of updating the tokens right now// as well, since the renenwal interval will be 0, and the thread will get scheduled// immediately.scheduleRenewal(driverTokenRenewerRunnable)}
首先判断token是否快要过期了,如果是,则调用writeNewTokensToHDFS函数获取新的token,并写到hdfs上。否则,生成一个调度任务再一段时间后重新判断。
private def writeNewTokensToHDFS(principal: String, keytab: String): Unit = {// Keytab is copied by YARN to the working directory of the AM, so full path is// not needed.// HACK:// HDFS will not issue new delegation tokens, if the Credentials object// passed in already has tokens for that FS even if the tokens are expired (it really only// checks if there are tokens for the service, and not if they are valid). So the only real// way to get new tokens is to make sure a different Credentials object is used each time to// get new tokens and then the new tokens are copied over the the current user's Credentials.// So:// - we login as a different user and get the UGI// - use that UGI to get the tokens (see doAs block below)// - copy the tokens over to the current user's credentials (this will overwrite the tokens// in the current user's Credentials object for this FS).// The login to KDC happens each time new tokens are required, but this is rare enough to not// have to worry about (like once every day or so). This makes this code clearer than having// to login and then relogin every time (the HDFS API may not relogin since we don't use this// UGI directly for HDFS communication.logInfo(s"Attempting to login to KDC using principal: $principal")//1)重新登录kdcval keytabLoggedInUGI = UserGroupInformation.loginUserFromKeytabAndReturnUGI(principal, keytab)logInfo("Successfully logged into KDC.")val tempCreds = keytabLoggedInUGI.getCredentialsval credentialsPath = new Path(credentialsFile)val dst = credentialsPath.getParent//2)使用新的登录身份信息向namenode拿hdfs delegation token,并添加到tempCreds中keytabLoggedInUGI.doAs(new PrivilegedExceptionAction[Void] {// Get a copy of the credentialsoverride def run(): Void = {val nns = YarnSparkHadoopUtil.get.getNameNodesToAccess(sparkConf) + dsthadoopUtil.obtainTokensForNamenodes(nns, freshHadoopConf, tempCreds)null}})// Add the temp credentials back to the original ones.//3)将新获取的token添加到当前登录用户中UserGroupInformation.getCurrentUser.addCredentials(tempCreds)val remoteFs = FileSystem.get(freshHadoopConf)// If lastCredentialsFileSuffix is 0, then the AM is either started or restarted. If the AM// was restarted, then the lastCredentialsFileSuffix might be > 0, so find the newest file// and update the lastCredentialsFileSuffix.if (lastCredentialsFileSuffix == 0) {hadoopUtil.listFilesSorted(remoteFs, credentialsPath.getParent,credentialsPath.getName, SparkHadoopUtil.SPARK_YARN_CREDS_TEMP_EXTENSION).lastOption.foreach { status =>lastCredentialsFileSuffix = hadoopUtil.getSuffixForCredentialsPath(status.getPath)}}val nextSuffix = lastCredentialsFileSuffix + 1val tokenPathStr =credentialsFile + SparkHadoopUtil.SPARK_YARN_CREDS_COUNTER_DELIM + nextSuffixval tokenPath = new Path(tokenPathStr)val tempTokenPath = new Path(tokenPathStr + SparkHadoopUtil.SPARK_YARN_CREDS_TEMP_EXTENSION)logInfo("Writing out delegation tokens to " + tempTokenPath.toString)val credentials = UserGroupInformation.getCurrentUser.getCredentials//4)将credentials信息写到目标文件中credentials.writeTokenStorageFile(tempTokenPath, freshHadoopConf)logInfo(s"Delegation Tokens written out successfully. Renaming file to $tokenPathStr")remoteFs.rename(tempTokenPath, tokenPath)logInfo("Delegation token file rename complete.")lastCredentialsFileSuffix = nextSuffix}
更新token的代码都在这个函数里了。其实就包括以下几个步骤
1)使用keytab和principal重新登录kerberos,并获取登录的ugi信息:keytabLoggedInUGI,注意,这里仅仅是kerberos的一个认证过程,还并不涉及到hdfs delegation token的东西,即keytabLoggedInUGI 中并不包含token信息。loginUserFromKeytabAndReturnUGI函数回返回一个新的用户对象,而不会影响当前登录的用户
2)获取keytabLoggedInUGI 中的credentials对象,然后使用keytabLoggedInUGI 身份去向namenode获取新的hdfs delegation token。并将token添加到一个临时的credentials对象中
3)将临时的credentials对象中的token添加到当前登录的ugi中。此时Am中使用token已经被更新,所以Am不会出现token expired问题,但是还需要把token更新到executor中。
4)生成token的存放目录,token存放目录为/user/{user}/.sparkStaging/${appid}, token文件名格式为“credentials-UUID-suffix”, suffix为后缀,按文件个数递增。token file默认保留五天。
至此,Am端token已经写到hdfs文件了。接下来就是executor端怎么读到最新的token文件,并把token更新到自己的ugi当中。
Executor启动过程这里就不在分析,主要是在AM当中会生成executor的启动信息及上下文,并发给NodeManager,由NodeManager来启动executor的container。在spark中,最终代表executor的类为:CoarseGrainedExecutorBackend
CoarseGrainedExecutorBackend
private def run(driverUrl: String,executorId: String,hostname: String,cores: Int,appId: String,workerUrl: Option[String],userClassPath: Seq[URL]) {...if (driverConf.contains("spark.yarn.credentials.file")) {logInfo("Will periodically update credentials from: " +driverConf.get("spark.yarn.credentials.file"))SparkHadoopUtil.get.startExecutorDelegationTokenRenewer(driverConf)}...}}
这里也是先判断在sparkConf中是否有"spark.yarn.credentials.file"配置,如果有,会生成一个ExecutorDelegationTokenUpdater对象,并调用其updateCredentialsIfRequired更新token
ExecutorDelegationTokenUpdater
try {val credentialsFilePath = new Path(credentialsFile)val remoteFs = FileSystem.get(freshHadoopConf)SparkHadoopUtil.get.listFilesSorted(remoteFs, credentialsFilePath.getParent,credentialsFilePath.getName, SparkHadoopUtil.SPARK_YARN_CREDS_TEMP_EXTENSION).lastOption.foreach { credentialsStatus =>val suffix = SparkHadoopUtil.get.getSuffixForCredentialsPath(credentialsStatus.getPath)if (suffix > lastCredentialsFileSuffix) {logInfo("Reading new delegation tokens from " + credentialsStatus.getPath)val newCredentials = getCredentialsFromHDFSFile(remoteFs, credentialsStatus.getPath)lastCredentialsFileSuffix = suffixUserGroupInformation.getCurrentUser.addCredentials(newCredentials)logInfo("Tokens updated from credentials file.")} else {// Check every hour to see if new credentials arrived.logInfo("Updated delegation tokens were expected, but the driver has not updated the " +"tokens yet, will check again in an hour.")delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.HOURS)return}}val timeFromNowToRenewal =SparkHadoopUtil.get.getTimeFromNowToRenewal(sparkConf, 0.8, UserGroupInformation.getCurrentUser.getCredentials)if (timeFromNowToRenewal <= 0) {// We just checked for new credentials but none were there, wait a minute and retry.// This handles the shutdown case where the staging directory may have been removed(see// SPARK-12316 for more details).delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.MINUTES)} else {logInfo(s"Scheduling token refresh from HDFS in $timeFromNowToRenewal millis.")delegationTokenRenewer.schedule(executorUpdaterRunnable, timeFromNowToRenewal, TimeUnit.MILLISECONDS)}} catch {// Since the file may get deleted while we are reading it, catch the Exception and come// back in an hour to try againcase NonFatal(e) =>logWarning("Error while trying to update credentials, will try again in 1 hour", e)delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.HOURS)}
这个函数就是executor端更新token的整个过程,包括几个步骤
1)获取hdfs上保存credentials目录下的最近更新的文件,并取出其suffix,与当前程序中保存的lastCredentialsFileSuffix 比较,如果比lastCredentialsFileSuffix 大,则表示AM端更新了token,需要重新读取token并更新。
2)如果Am端还没更新,则过一小时重试
3)token更新完后,会再次判断下次待更新的时间,并生成一个调度任务,到期执行更新操作。
在executor端更新其实就是把hdfs上的credentials文件读取出来,使用 UserGroupInformation.getCurrentUser.addCredentials(newCredentials)函数对当前的ugi添加新的token信息就可以了。
至此,spark上解决hdfs delegation token过期问题就分析完了。整个过程类似与下面这张图:
总结下来就是在Am端更新token信息,并把更新后的token写到hdfs,在executor端读取hdfs上更新的token,并更新到自己的ugi当中。按理说这样能解决token过期的问题了,但是用过spark streaming的同学可能会遇到一个奇怪的问题,即使在提交任务的时候带上了"–principal"参数,还是会遇到hdfs delegation token 过期的问题,那又是怎么一会事呢?下面继续分析hdfs的一个bug。
hdfs delegation token bug
如上文分析,Spark在Am端会去更新token,因此理论上来讲应该不会出现token过期问题了,但在我们使用过程中还是会出现token过期的情况,网上查了后说是hfds上的一个bug导致:hdfs-9276
https://issues.apache.org/jira/browse/HDFS-9276
理解这个bug要先知道一个概念,即Token的service字段是client从server端获取token后添加的,client用于区分不同服务的token,在server端根本没有service字段的概念。客户端通过FileSystem.addDelegationTokens函数向namenode申请hdfs delegation token。当从server端申请到token后,会给token设置service字段:
DFSClient.java
public Token getDelegationToken(Text renewer)
throws IOException {
assert dtService != null;
Token token =
namenode.getDelegationToken(renewer);
if (token != null) {token.setService(this.dtService);LOG.info("Created " + DelegationTokenIdentifier.stringifyToken(token));
} else {LOG.info("Cannot get delegation token from " + renewer);
}
return token;
}
这里将service字段设置为dtService。在HA这种情况下,客户端使用nameservice访问hdfs,所以dtService的值为:ha-hdfs:。
这个service我们暂且称之为logicService。但是,client必须使用IP:PORT访问server。当client确定active的namenode后,怎么确定使用哪个token来和server端认证呢?之前讲过token的service字段用于区分不同的server,但是该字段里并不包含具体的ip和端口。为了解决这个问题,其实每次在new 一个DFSClient实例时,会把token拷贝两份,并把里面的service字段替换成具体的ip和端口:
HAUtil.java
public static void cloneDelegationTokenForLogicalUri(UserGroupInformation ugi, URI haUri,Collection<InetSocketAddress> nnAddrs) {// this cloning logic is only used by hdfsText haService = HAUtil.buildTokenServiceForLogicalUri(haUri,HdfsConstants.HDFS_URI_SCHEME);Token<DelegationTokenIdentifier> haToken =tokenSelector.selectToken(haService, ugi.getTokens());if (haToken != null) {for (InetSocketAddress singleNNAddr : nnAddrs) {// this is a minor hack to prevent physical HA tokens from being// exposed to the user via UGI.getCredentials(), otherwise these// cloned tokens may be inadvertently propagated to jobsToken<DelegationTokenIdentifier> specificToken =new Token.PrivateToken<DelegationTokenIdentifier>(haToken);SecurityUtil.setTokenService(specificToken, singleNNAddr);Text alias = new Text(buildTokenServicePrefixForLogicalUri(HdfsConstants.HDFS_URI_SCHEME)+ "//" + specificToken.getService());ugi.addToken(alias, specificToken);LOG.debug("Mapped HA service delegation token for logical URI " +haUri + " to namenode " + singleNNAddr);}} else {LOG.debug("No HA service delegation token found for logical URI " +haUri);}}
这样一来,在client端,每一个token其实就有三个拷贝,分别为一个HA token,和两个对应到具体namenode的namenode token。于是,client想和哪个namenode通信就能选择到相应的token了。
那hdfs-9276这个bug就很明显了,意思是当用户使用UserGroupInformation.getCurrentUser().addCredentials(credentials)方法更新token时,只能更新HA token,并不能更新两个namenode token。所以当client使用namenode 的ip和port选择到某个namenode token时,该token其实还是老的token,并没有被更新,因此使用该token去访问server端,就会被server拒绝,并提示token过期异常。
所以9276的patch把这个问题解决了(代码就不分析,感兴趣的可以自己去看下),当用户addCredentials的时候,会把HA token对应的两个namenode token也更新。细心的读者应该发现,当每次new一个DFSClient实例的时候,内部就会把HA token拷贝两份,生成新的两个namenode token,因此如果每次都new 一个DFSClient是可以绕过9276描述的问题的。
其实spark也是尝试这么做的,回到spark 在excutor端更新token的过程:
ExecutorDelegationTokenUpdater
try {val credentialsFilePath = new Path(credentialsFile)//此处获取了一个新的FileSystem对象,但此时ugi中的HA token还没有被更新val remoteFs = FileSystem.get(freshHadoopConf)SparkHadoopUtil.get.listFilesSorted(remoteFs, credentialsFilePath.getParent,credentialsFilePath.getName, SparkHadoopUtil.SPARK_YARN_CREDS_TEMP_EXTENSION).lastOption.foreach { credentialsStatus =>val suffix = SparkHadoopUtil.get.getSuffixForCredentialsPath(credentialsStatus.getPath)if (suffix > lastCredentialsFileSuffix) {logInfo("Reading new delegation tokens from " + credentialsStatus.getPath)//从hdfs中读取HA tokenval newCredentials = getCredentialsFromHDFSFile(remoteFs, credentialsStatus.getPath)lastCredentialsFileSuffix = suffix//把新的HA token更新到ugi当中UserGroupInformation.getCurrentUser.addCredentials(newCredentials)logInfo("Tokens updated from credentials file.")} else {// Check every hour to see if new credentials arrived.logInfo("Updated delegation tokens were expected, but the driver has not updated the " +"tokens yet, will check again in an hour.")delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.HOURS)return}}val timeFromNowToRenewal =SparkHadoopUtil.get.getTimeFromNowToRenewal(sparkConf, 0.8, UserGroupInformation.getCurrentUser.getCredentials)if (timeFromNowToRenewal <= 0) {// We just checked for new credentials but none were there, wait a minute and retry.// This handles the shutdown case where the staging directory may have been removed(see// SPARK-12316 for more details).delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.MINUTES)} else {//更新完token后,马上调度了下一个更新任务,而这个任务要在更新的token快要过期时才会执行logInfo(s"Scheduling token refresh from HDFS in $timeFromNowToRenewal millis.")delegationTokenRenewer.schedule(executorUpdaterRunnable, timeFromNowToRenewal, TimeUnit.MILLISECONDS)}} catch {// Since the file may get deleted while we are reading it, catch the Exception and come// back in an hour to try againcase NonFatal(e) =>logWarning("Error while trying to update credentials, will try again in 1 hour", e)delegationTokenRenewer.schedule(executorUpdaterRunnable, 1, TimeUnit.HOURS)}
在函数的开始获使用FileSystem.get(freshHadoopConf)获取remoteFs对象,其中freshHadoopConf的"fs.hdfs.impl.disable.cache"设置为true,表示新生产一个FileSystem对象。这里其实很明显就是想让绕过9276 bug。但是很可惜,用的地方不对。在新生产这个对象的时候,ugi中保存的token其实还并没有被更新。随后读取hdfs中新的token,并更新到ugi当中。然后便调度下一个任务了。可以看到在更新token后,没有在new 一个FileSystem,所以ugi中的namenode token就得不到更新,因此还是会出现token过期问题。
hdfs delegation token过期问题分析到此结束。