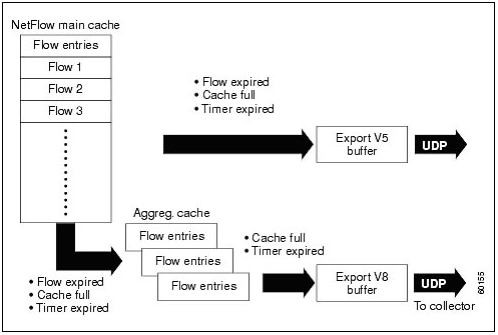
Flow表项数量可能会因为没有得到及时释放而过多占用有限的Cache空间。为此,NetFlow提供了一种非常复杂、
高效的算法以快速定位一个数据包在该Cache中的位置或判断是否应新建表项,并且通过管理员给定
的阀值进行各类表项的超时导出,从而及时释放老的表项以容纳新建Flow信息。
长连接会话 强制超时(Active Timer,缺省 30 minutes);
缓存空间耗尽所触发的强制超时;
TCP FIN/RST触发的超时。
Record:提供对每个Flow的详细数据记录。
下文以NetFlow V9为例,输出报文Header与Record整体结构如下所示:

表格3-3 NetFlow V9各字段含义
| 字段名称 | 所处位置 | 字段长度 | 含义 |
| Version | Header | 2 Bytes | 版本号,0x0009 |
| Count | 2 Bytes | 报文中所有记录的数量(包括template and data两种类型) | |
| System Uptime | 4 Bytes | 自网元设备加电以来的毫秒数 | |
| Unix Seconds | 4 Bytes | 网元设备当前机器时间(与所在时区相关)与格林威治时间(亦即”0 UTC”)1970年1月1日 0点0分0秒之间的秒数差额 | |
| Package Sequence | 4 Bytes | 网元设备所导出的Flow报文的序列号,顺序递增,可用以检测Flow报文丢失。 | |
| Source ID | 4 Bytes | 由0x0000+路由引擎标识+线路板卡标识构成,可与Flow报文源IP地址结合起来唯一的标识Flow信息导出节点。 | |
| FlowSet ID | Template FlowSet | 2 Bytes | 用以区分Template Record和Data Record。Template Record的FlowSet ID 位于0~255之间,而 Data Record 的FlowSet ID 总在255以上。 |
| Length | 2 Bytes | 本FlowSet的总体长度。 | |
| Template ID | Template Record | 2 Bytes | 开始一个新的Template Record,声明一个新的Data Record格式的编号ID,数值总大于255,在该网元设备本地有效。 |
| Field Count | 2 Bytes | 本Template Record所包含的字段数量。 | |
| Field 1 Type | 2 Bytes | 开始一个新字段的定义,说明该字段的类型,类型编号与厂商相关,Cisco在NetFlow V9中总共定义了89种类型。 | |
| Field 1 Length | 2 Bytes | 上述所定义的字段的长度。 | |
| …… | …… | …… | |
| Field N Type | 2 Bytes | 开始第N个新字段的定义,说明该字段的类型。 | |
| Field N Length | 2 Bytes | 上述所定义的字段的长度。 | |
| FlowSet ID | Data FlowSet | 2 Bytes | 引用一个Template Record ID以开始一个新的Data FlowSet。该字段数值总在255以上。 |
| Length | 2 Bytes | 本Data FlowSet的总体长度。 | |
| Record 1 - Field 1 value | Data Record | 2 Bytes | 第1个Data Record的第1个字段的数值。 |
| …… | …… | …… | |
| Record 1 - Field N value | 2 Bytes | 第1个Data Record的第N个字段的数值。 | |
| Record N - Field 1 value | 2 Bytes | 第N个Data Record的第1个字段的数值。 | |
| …… | …… | …… | |
| Record N - Field N value | 2 Bytes | 第N个Data Record的第N个字段的数值。 | |
| …… | …… | …… | |
| Padding | 报文尾部 | 填充位,将该Data FlowSet补齐至N*32 bits长度。这些填充位将计算入该Data FlowSet的Length数值。 |
通过Template功能NetFlow V9获得了前所未有的扩展灵活性。
Template描述了NetFlow输出记录的各字段定义,无需改变现有
规范即可支持将来可能出现的增强功能,从而无需重新编译、
修改流量采集分析系统即可快速支持新增功能特征。
Flow具备详尽的会话描述能力。在NetFlow V9中,缺省提供了多达89种字段类型,并允许通过Template和
Aggregation机制进行任意组合、汇聚,能够详细描述流量分布的各类特征.
NetFlow与SNMP的不同
无论是MIB还是后来的RMON,SNMP所针对的信息一般都围绕网元设备展开,如Interface吞吐率、
接收到的坏帧数量、CPU/RAM利用率等。而NetFlow正如同它的名字一样,其所关注的重点在于网络链
路上所传输流量的特征信息,并且这些信息能够更直接的反映出当前网络上访问行为分
布以及合同客户此时所得到的真实的服务质量水平。
NetFlow与SNMP的主要差异可以从以下几点得到说明:
NetFlow关注流量特征,SNMP关注设备状态;
NetFlow直接围绕Session会话连接进行数据提取,而SNMP则以物理接口为基本单位进行数据统计;
从Agent角度来看,NetFlow采用数据主动推送技术,SNMP则主要采取被动轮询机制;
NetFlow数据信息更为丰富、描述能力更强;
NetFlow支持抽样操作,具备良好的扩展弹性,能够更好适应高端网络实际需求;
SNMP功能通常随着设备销售而免费提供,而在很多现有设备中,NetFlow作为增值功能则需要额外
购买许可License或特定软件包。
因此,在网络流量测量及分析系统中,如异常流量分析系统,NetFlow已经成为一个重要的数据提取方式,
为高端网络骨干链路的实时流量采集
分析提供高效、准确的数据摘要提取服务,是网络流量分析阵营不可或缺的基础技术。
| Flow名称 | 代表厂商 | 主要版本 | 备注 |
| NetFlow | Cisco | V1、V5、V7、V8、V9 | 应用最广 |
| CFlowd | Juniper | V5、V8 | 厂商跟进力度不高 |
| sFlow | Foundry、HP、Alcatel、NEC、Extreme等 | V4、V5 | 实时性较强,具备突出的第二~七层信息描述能力 |
| NetStream | 华为 | V5、V8、V9 | 与NetFlow较为类似 |
| IPFIX | IETF标准规范 | RFC 3917 | 以NetFlow V9为蓝本 |