文章目录
- 前言
- 一、什么是动态数据源
- 二、动态数据源实现
- 1.实现原理
- 2.实现过程
前言
有这样一个场景,现在要开发一个数据API功能,用户自己编写数据源脚本,在界面任意选择一个数据源,可选择的数据源列表中数据源类型是多样的,可以是关系数据库,也可以是NoSql,在使用这个功能的时候,后台需要根据用户的选择,会开启一个数据源连接进行各种操作,因为用户的选择是任意的随机的,如果每次都去重新创建数据源,这样会产生很多数据源,涉及到要去管理他们的连接和关闭等等,而且如果是大并发情况下,就有可能出现网络IO、内存等耗尽,显然这是存在性能问题的,所以就需要一种机制,只创建一个数据源,当需要使用新的数据源时,可以在上下文中动态的切换,这就是我今天要介绍的动态数据源。
一、什么是动态数据源
首先有个概念要澄清一下,这里说的动态数据源并不是多数据源,Spring Boot是支持多数据源的,多数据源是指在Spring Boot上下文中可以配置多个DataSource,有一个是首选的,Spring Boot的自动化配置默认使用的就是首选数据源,多数据源使用时通过Spring容器的注入来指定,这就是Spring Boot多数据源。
动态数据源,是指DataSource在使用前是不确定的,或者说是不存在的,这里的DataSource可以是Spring Boot多数据源中的一个,也可以是Spring Boot仅有的一个数据源,但在使用的时候,会动态的是加载连接信息并创建数据源,而且在使用新的数据源时,还会将旧数据源切换为新数据源,并关闭旧数据源,这就是动态数据源。通过介绍其实可以大概看出实现原理,动态数据源只有一个动态数据源对象,它可以根据使用要求动态修改连接信息,创建新的连接,同时还可以自动关闭旧的连接,实现数据源自动切换。
二、动态数据源实现
1.实现原理
- 数据源选择
springboot2.x之后,系统的默认数据源由原来的的org.apache.tomcat.jdbc.pool.DataSource更改为com.zaxxer.hikari.HikariDataSource,HikariDataSource 号称 Java WEB 当前速度最快的数据源,相比于传统的 C3P0 、DBCP、Tomcat jdbc 等连接池更加优秀,这里实际用于创建的数据源对象选择Spring Boot默认数据源。
可能有些读者对Spring Boot底层数据源Hikari并不了解,这里大概介绍一下,查看HikariDataSource源码,发现它是一个数据源,实现了javax.sql.DataSource

同时它也是一个数据库连接池,从源码可以看到包含了HikariPool对象
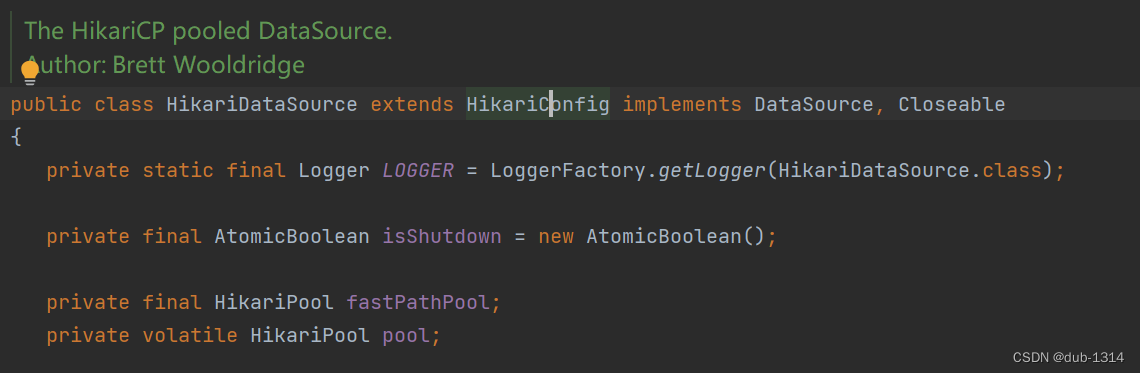
此外还继承了com.zaxxer.hikari.HikariConfig接口,这个接口定义了数据连接池及数据库连接的一些配置项
// Properties changeable at runtime through the HikariConfigMXBean//private volatile String catalog;private volatile long connectionTimeout;private volatile long validationTimeout;private volatile long idleTimeout;private volatile long leakDetectionThreshold;private volatile long maxLifetime;private volatile int maxPoolSize;private volatile int minIdle;private volatile String username;private volatile String password;// Properties NOT changeable at runtime//private long initializationFailTimeout;private String connectionInitSql;private String connectionTestQuery;private String dataSourceClassName;private String dataSourceJndiName;private String driverClassName;private String exceptionOverrideClassName;private String jdbcUrl;private String poolName;private String schema;private String transactionIsolationName;private boolean isAutoCommit;private boolean isReadOnly;private boolean isIsolateInternalQueries;private boolean isRegisterMbeans;private boolean isAllowPoolSuspension;private DataSource dataSource;private Properties dataSourceProperties;private ThreadFactory threadFactory;private ScheduledExecutorService scheduledExecutor;private MetricsTrackerFactory metricsTrackerFactory;private Object metricRegistry;private Object healthCheckRegistry;private Properties healthCheckProperties;部分配置项说明如下:
name 描述 构造器默认值 默认配置validate之后的值 validate重置
autoCommit 自动提交从池中返回的连接 true true -
connectionTimeout 等待来自池的连接的最大毫秒数 SECONDS.toMillis(30) = 30000 30000 如果小于250毫秒,则被重置回30秒
idleTimeout 连接允许在池中闲置的最长时间 MINUTES.toMillis(10) = 600000 600000 如果idleTimeout+1秒>maxLifetime 且 maxLifetime>0,则会被重置为0(代表永远不会退出);如果idleTimeout!=0且小于10秒,则会被重置为10秒
maxLifetime 池中连接最长生命周期 MINUTES.toMillis(30) = 1800000 1800000 如果不等于0且小于30秒则会被重置回30分钟
connectionTestQuery 如果您的驱动程序支持JDBC4,我们强烈建议您不要设置此属性 null null -
minimumIdle 池中维护的最小空闲连接数 -1 10 minIdle<0或者minIdle>maxPoolSize,则被重置为maxPoolSize
maximumPoolSize 池中最大连接数,包括闲置和使用中的连接 -1 10 如果maxPoolSize小于1,则会被重置。当minIdle<=0被重置为DEFAULT_POOL_SIZE则为10;如果minIdle>0则重置为minIdle的值
metricRegistry 该属性允许您指定一个 Codahale / Dropwizard MetricRegistry 的实例,供池使用以记录各种指标 null null -
healthCheckRegistry 该属性允许您指定池使用的Codahale / Dropwizard HealthCheckRegistry的实例来报告当前健康信息 null null -
poolName 连接池的用户定义名称,主要出现在日志记录和JMX管理控制台中以识别池和池配置 null HikariPool-1 -
initializationFailTimeout 如果池无法成功初始化连接,则此属性控制池是否将 fail fast 1 1 -
isolateInternalQueries 是否在其自己的事务中隔离内部池查询,例如连接活动测试 false false -
allowPoolSuspension 控制池是否可以通过JMX暂停和恢复 false false -
readOnly 从池中获取的连接是否默认处于只读模式 false false -
registerMbeans 是否注册JMX管理Bean(MBeans) false false -
catalog 为支持 catalog 概念的数据库设置默认 catalog driver default null -
connectionInitSql 该属性设置一个SQL语句,在将每个新连接创建后,将其添加到池中之前执行该语句。 null null -
driverClassName HikariCP将尝试通过仅基于jdbcUrl的DriverManager解析驱动程序,但对于一些较旧的驱动程序,还必须指定driverClassName null null -
transactionIsolation 控制从池返回的连接的默认事务隔离级别 null null -
validationTimeout 连接将被测试活动的最大时间量 SECONDS.toMillis(5) = 5000 5000 如果小于250毫秒,则会被重置回5秒
leakDetectionThreshold 记录消息之前连接可能离开池的时间量,表示可能的连接泄漏 0 0 如果大于0且不是单元测试,则进一步判断:(leakDetectionThreshold < SECONDS.toMillis(2) or (leakDetectionThreshold > maxLifetime && maxLifetime > 0),会被重置为0 . 即如果要生效则必须>0,而且不能小于2秒,而且当maxLifetime > 0时不能大于maxLifetime
dataSource 这个属性允许你直接设置数据源的实例被池包装,而不是让HikariCP通过反射来构造它 null null -
schema 该属性为支持模式概念的数据库设置默认模式 driver default null -
threadFactory 此属性允许您设置将用于创建池使用的所有线程的java.util.concurrent.ThreadFactory的实例。 null null -
scheduledExecutor 此属性允许您设置将用于各种内部计划任务的java.util.concurrent.ScheduledExecutorService实例 null null -- 动态数据源实现
定义一个新的数据源,也实现javax.sql.DataSource,实际上它是一个代理数据源,代理的对象就是上节介绍的数据源,实际使用中通过这个代理数据源实现新旧数据源的切换和关闭。
import javax.sql.DataSource;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.SQLFeatureNotSupportedException;
import java.util.concurrent.atomic.AtomicReference;
import java.util.logging.Logger;/*** @author Mr.bin* @version 1.0.0* @ClassName DynamicDataSource.java* @Description 动态数据源* @createTime 2022年05月21日 11:57:00*/
public class DynamicDataSource implements DataSource {private final AtomicReference<DataSource> dataSourceReference;public DynamicDataSource(DataSource dataSource) {this.dataSourceReference = new AtomicReference<>(dataSource);}DataSource getDataSource() {return dataSourceReference.get();}public DataSource getAndSetDataSource(DataSource newDataSource) {return dataSourceReference.getAndSet(newDataSource);}@Overridepublic Connection getConnection() throws SQLException {return getDataSource().getConnection();}@Overridepublic Connection getConnection(String username, String password) throws SQLException {return getDataSource().getConnection(username, password);}@Overridepublic <T> T unwrap(Class<T> iface) throws SQLException {return getDataSource().unwrap(iface);}@Overridepublic boolean isWrapperFor(Class<?> iface) throws SQLException {return getDataSource().isWrapperFor(iface);}@Overridepublic PrintWriter getLogWriter() throws SQLException {return getDataSource().getLogWriter();}@Overridepublic void setLogWriter(PrintWriter out) throws SQLException {getDataSource().setLogWriter(out);}@Overridepublic void setLoginTimeout(int seconds) throws SQLException {getDataSource().setLoginTimeout(seconds);}@Overridepublic int getLoginTimeout() throws SQLException {return getDataSource().getLoginTimeout();}@Overridepublic Logger getParentLogger() throws SQLFeatureNotSupportedException {return getDataSource().getParentLogger();}
}2.实现过程
- 引入依赖项
<!-- 引入Spring封装的jdbc,内部默认依赖了 HikariDataSource 数据源--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jdbc</artifactId></dependency><!-- web项目启动模块--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- mysql数据库连接驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope><version>8.0.16</version></dependency>...
作为示例这里只引入了mysql驱动,实际应用中根据需要自行引入相关数据源驱动
- 配置数据源连接信息
此配置可以没有,因为实际动态数据源的连接信息,是在运行时加载的,这些连接信息可以是在数据库,也可以是在配置文件,或者其他方式获取,这里介绍只是为了展示数据源配置包含哪些信息及Hikari的自动化配置方式
spring:datasource:# jdbc 连接基础配置username: rootpassword: root#使用的 mysql 版本为:Server version: 5.6.11 MySQL Community Server (GPL)#mysql 驱动版本:mysql-connector-java-8.0.16.jar#高版本 Mysql 驱动时,配置的 driver-class-name 不再是 com.mysql.jdbc.Driver,url 后面必须设置时区 serverTimezoneurl: jdbc:mysql://127.0.0.1:3306/test?characterEncoding=UTF-8&serverTimezone=UTCdriver-class-name: com.mysql.cj.jdbc.Driver#hikari数据源特性配置hikari:maximum-pool-size: 100 #最大连接数,默认值10.minimum-idle: 20 #最小空闲连接,默认值10.connection-timeout: 60000 #连接超时时间(毫秒),默认值30秒.#空闲连接超时时间,默认值600000(10分钟),只有空闲连接数大于最大连接数且空闲时间超过该值,才会被释放#如果大于等于 max-lifetime 且 max-lifetime>0,则会被重置为0.idle-timeout: 600000max-lifetime: 3000000 #连接最大存活时间,默认值30分钟.设置应该比mysql设置的超时时间短connection-test-query: select 1 #连接测试查询
- 配置动态数据源对象
@Bean(name = "dynamicDataSource")public DynamicDataSource dynamicDataSource(DataSourceProperties dataSourceProperties) {HikariDataSource dataSource = dataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build();return new DynamicDataSource(dataSource);}
- 获取数据源连接信息
获取方式可以有很多种,一般都是保存在数据库,或者是配置文件里面,这里以yml文件为例
@Value("${datasource.data.jdbcUrl}")private String jdbcUrl;@Value("${datasource.data.driverClass}")private String driverClass;@Value("${datasource.data.userName}")private String userName;@Value("${datasource.data.password}")private String password;@Resource(name = "dynamicDataSource")private DynamicDataSource dynamicDataSource;...
如果是从数据库获取,则代码可能是这样:
// 获取存储数据源连接信息的数据库连接
DataSource dataSourceInfo = null;
try {dataSourceInfo = customDataSource();
} catch (SQLException | ClassNotFoundException e) {return throwDataSourceError(e);
}
NamedParameterJdbcTemplate jdbcTemplate = new NamedParameterJdbcTemplate(dataSourceInfo);
String sql = "select jdbcUrl, driverClass, userName, password from datasource_collection_info where datasource_name = :dataSourceName";
MapSqlParameterSource param = new MapSqlParameterSource();
param.addValue(datasource_name, dataSourceName);
// 查询数据源连接信息
DataSourceInfo dbInfo = jdbcTemplate.queryForObject(sql, param, new BeanPropertyRowMapper<>(DataSourceInfo.class));
- 切换数据源
public DynamicDataSource customDataSource() throws SQLException, ClassNotFoundException {DataSourceProperties properties = new DataSourceProperties();properties.setUrl(jdbcUrl);properties.setDriverClassName(driverClass);properties.setUsername(userName);properties.setPassword(password);HikariDataSource hikariDataSource =properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();dataSourceRefresher.refreshDataSource(hikariDataSource);return dynamicDataSource;}...
如果是从数据库获取连接信息,则代码可能是这样:
public DynamicDataSource customDataSource(DataSourceInfo dbInfo) throws SQLException, ClassNotFoundException {// 封装数据源连接信息DataSourceProperties properties = new DataSourceProperties();properties.setUrl(dbInfo.getJdbcUrl());properties.setDriverClassName(dbInfo.getDriverClass());properties.setUsername(dbInfo.getUserName());properties.setPassword(dbInfo.getPassword());HikariDataSource hikariDataSource =properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();dataSourceRefresher.refreshDataSource(hikariDataSource);return dynamicDataSource;}...
切换动作由一行代码实现:
dataSourceRefresher.refreshDataSource(hikariDataSource);
上面代码从配置文件读取了mysql连接信息,然后创建了一个HikariDataSource数据源对象,最后把这个数据源对象刷新到dynamicDataSource,这样在其他地方需要使用这个数据源的话,就可以通过dynamicDataSource代理,刷新实现如下:
import com.zaxxer.hikari.HikariDataSource;
import com.zaxxer.hikari.HikariPoolMXBean;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;/*** @author Mr.bin* @version 1.0.0* @ClassName DataSourceRefresher.java* @Description 动态数据源刷新* @createTime 2022年05月21日 16:40:00*/
@Slf4j
@Component
public class DataSourceRefresher {private static final int MAX_RETRY_TIMES = 10;@Autowiredprivate DynamicDataSource dynamicDataSource;private ScheduledExecutorService scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();public synchronized void refreshDataSource(javax.sql.DataSource newDataSource) {try {log.info("refresh data source....");javax.sql.DataSource oldDataSource = dynamicDataSource.getAndSetDataSource(newDataSource);shutdownDataSourceAsync(oldDataSource);} catch (Throwable ex) {log.error("refresh data source error", ex);}}public void shutdownDataSourceAsync(javax.sql.DataSource dataSource) {scheduledExecutorService.execute(() -> doShutdownDataSource(dataSource));}private void doShutdownDataSource(javax.sql.DataSource dataSource) {if (dataSource instanceof HikariDataSource) {int retryTimes = 0;HikariDataSource hikariDataSource = (HikariDataSource) dataSource;HikariPoolMXBean poolBean = hikariDataSource.getHikariPoolMXBean();while (poolBean.getActiveConnections() > 0 && retryTimes <= MAX_RETRY_TIMES) {try {poolBean.softEvictConnections();sleep1Second();} catch (Exception e) {log.warn("doShutdownDataSource error ", e);} finally {retryTimes++;}}hikariDataSource.close();log.info("shutdown data source success");}}private void sleep1Second() {try {TimeUnit.SECONDS.sleep(1);} catch (InterruptedException e) {Thread.currentThread().interrupt();log.error("sleep1Second has error:" + e.getMessage());}}
}
上面代码实现很简单,主要就两步,第一步切换新数据源,这一步通过一个原子变量实现,第二步关闭旧数据源,需要注意的是HikariDataSource数据源的关闭方式,这里是通过HikariPoolMXBean方式安全关闭的,这是Hikari提供的一种安全的关闭方式,不可直接close关闭。