😊 @ 作者: 一恍过去
💖 @ 主页: https://blog.csdn.net/zhuocailing3390
🎊 @ 社区: Java技术栈交流
🎉 @ 主题: SpringBoot实现多数据源配置
⏱️ @ 创作时间: 2022年06月13日
目录
- 前言
- 1、创建数据库(表)
- 2、yaml配置
- 3、数据源配置
- 4、mappering
- 5、mapper
- 6、controllrt
- 7、目录结构
- 8、注意事项
- 9、测试

前言
多数据源是一种常见的技术需求,它允许应用程序连接和操作多个不同的数据库或数据源。
使用该方式配置数据源就是,将连接不同数据的Mapper有Mapping文件放到不同的目录下,在配置DataSource进行手动指定,使用时通过不同目录的Mapper访问不同的数据库连接,达到多数据源配置的目的;
1、创建数据库(表)
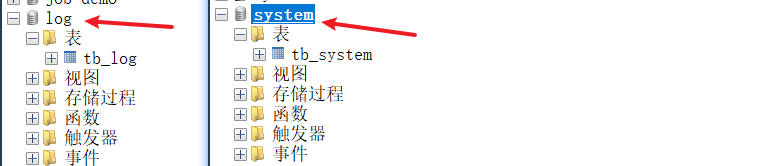
分别在mysql中创建两个库:system、log,并且创建对应的表(根据项目实际情况的定),如下:
2、yaml配置
spring:application:name: quartzdatasource:# 数据源一system:driverClassName: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://127.0.0.1:3307/system?useUnicode=true&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghaiusername: rootpassword: lhzlx# 数据源二log:driverClassName: com.mysql.cj.jdbc.Driverjdbc-url: jdbc:mysql://127.0.0.1:3307/log?useUnicode=true&useSSL=false&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghaiusername: rootpassword: lhzlx# hikari连接池type: com.zaxxer.hikari.HikariDataSourcehikari:#最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值maximum-pool-size: 10#最小空闲连接,默认值 10,小于0或大于maximum-pool-size,都会重置为maximum-pool-sizeminimum-idle: 2#连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒connection-timeout: 60000#空闲连接超时时间,默认值600000ms(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;#不等于0且小于10秒,会被重置为10秒。#只有空闲连接数大于最大连接数且空闲时间超过该值,才会被释放(自动释放过期链接)idle-timeout: 600000#连接最大存活时间.不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短max-lifetime: 640000#连接测试查询connection-test-query: SELECT 1#mapper 别名扫描
mybatis:type-aliases-package: com.lhz.demo.model.entity#数据库类型configuration.database-id: mysql#自动驼峰转换configuration.map-underscore-to-camel-case: true
注意: 在使用hikari作为连接池时,如果配置多数据源需要将url修改为jdbc-url,使用druid作为连接池则不需要修改;否则会出现jdbcUrl is required with driverClassName错误;
3、数据源配置
配置LogDataSourceConfig与SystemDataSourceConfig
@MapperScan(basePackages = "com.lhz.demo.mapper.system", sqlSessionFactoryRef = "systemSqlSessionFactory")
@Configuration
public class SystemDataSourceConfig {// @Primary :默认数据源@Primary@Bean("systemDataSource")// yaml文件中配置的数据源前缀@ConfigurationProperties(prefix = "spring.datasource.system")public DataSource getSystemDataSource(){return DataSourceBuilder.create().build();}@Primary@Bean("systemSqlSessionFactory")public SqlSessionFactory systemSqlSessionFactory(@Qualifier("systemDataSource") DataSource dataSource) throws Exception {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();bean.setDataSource(dataSource);// 配置mapping所在目录bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mappers/system/*.xml"));return bean.getObject();}@Primary@Bean("systemSqlSessionTemplate")public SqlSessionTemplate systemSqlSessionTemplate(@Qualifier("systemSqlSessionFactory") SqlSessionFactory sqlSessionFactory){return new SqlSessionTemplate(sqlSessionFactory);}
}
@Configuration
@MapperScan(basePackages = "com.lhz.demo.mapper.log", sqlSessionFactoryRef = "logSqlSessionFactory")
public class LogDataSourceConfig {@Bean("logDataSource")// yaml文件中配置的数据源前缀@ConfigurationProperties(prefix = "spring.datasource.log")public DataSource getLogDataSource(){return DataSourceBuilder.create().build();}@Bean("logSqlSessionFactory")public SqlSessionFactory logSqlSessionFactory(@Qualifier("logDataSource") DataSource dataSource) throws Exception {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();bean.setDataSource(dataSource);// 配置mapping所在目录bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath*:mappers/log/*.xml"));return bean.getObject();}@Bean("logSqlSessionTemplate")public SqlSessionTemplate logSqlSessionTemplate(@Qualifier("logSqlSessionFactory") SqlSessionFactory sqlSessionFactory){return new SqlSessionTemplate(sqlSessionFactory);}
}
4、mappering
在resources/mappers/log目录下创建LogMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lhz.demo.mapper.log.LogMapper"><select id="selectAll" resultType="com.lhz.demo.model.entity.TbLog">select * from tb_log</select>
</mapper>
在resources/mappers/system目录下创建SystemMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lhz.demo.mapper.system.SysMapper"><select id="selectAll" resultType="com.lhz.demo.model.entity.TbSystem">select * from tb_system</select>
</mapper>

5、mapper
在com.lhz.demo.mapper.log目录下创建LogMapper
@Mapper
public interface LogMapper {List<TbLog> selectAll();
}
在com.lhz.demo.mapper.system目录下创建SystemMapper
@Mapper
public interface SysMapper {List<TbSystem> selectAll();
}
6、controllrt
@RestController
@RequestMapping("/test")
@Slf4j
public class TestController {@Resourceprivate SysMapper sysMapper;@Resourceprivate LogMapper logMapper;/*** 查询system库* @return*/@GetMapping("/sys")public Object sys() {return sysMapper.selectAll();}/*** 查询log库* @return*/@GetMapping("/log")public Object log() {return logMapper.selectAll();}
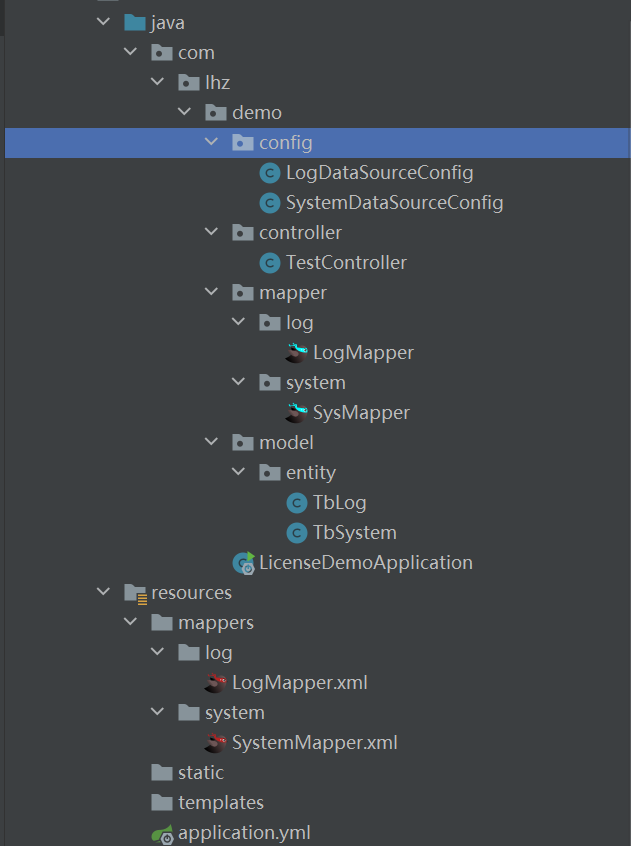
}7、目录结构
8、注意事项
在使用hikari作为连接池时,如果配置多数据源需要将url修改为jdbc-url,使用druid作为连接池则不需要修改;否则会出现jdbcUrl is required with driverClassName错误;
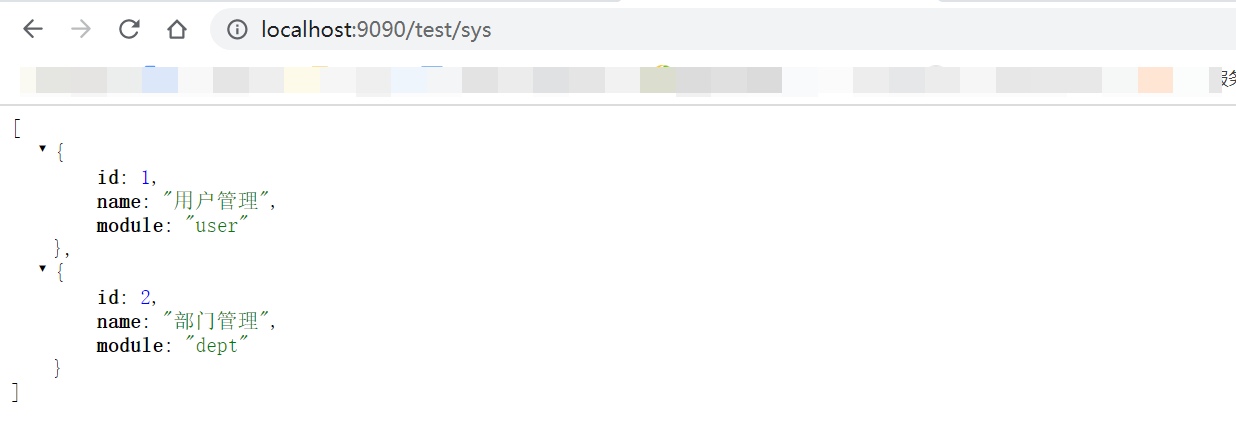
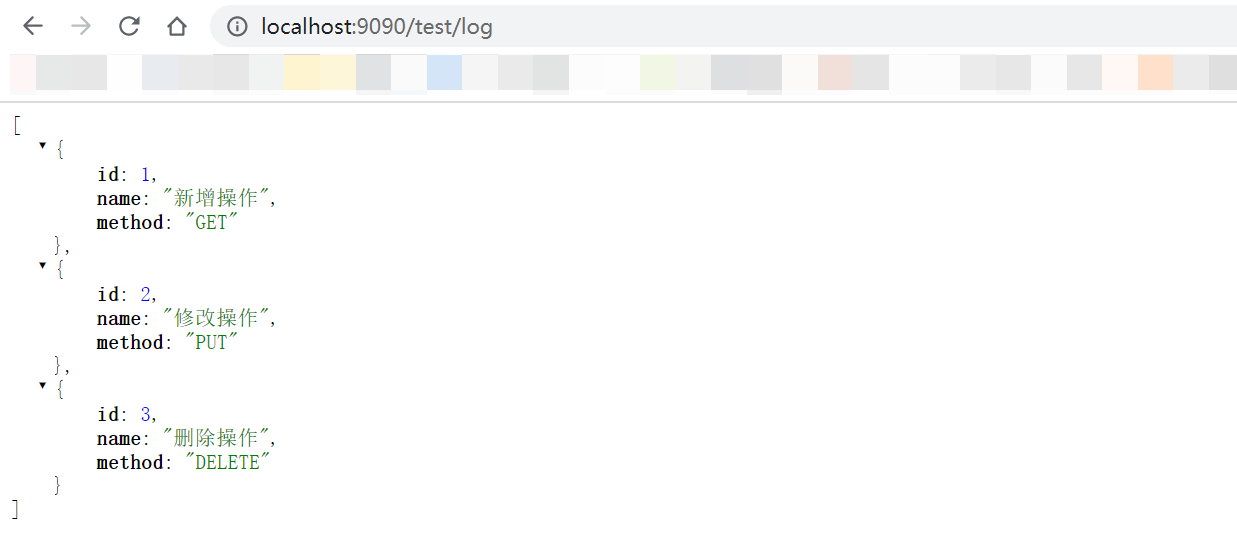
9、测试
启动项目分别访问http://localhost:9090/test/sys与http://localhost:9090/test/log均有数据输出,则表示配置成功;