1.1 简述
最近项目中有动态切换数据源需求,主要是要动态切换数据源进行数据的获取,现将项目中实现思路及代码提供出来,供大家参考。当然切换数据源还有其他的方式比如使用切面的方式,其实大体思路是一样的。
1.2 设计思路与代码示例
数据库连接池druid:
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.21</version>
</dependency>
yml中druid配置:
druid:initial-size: 5 # 初始化大小min-idle: 10 # 最小连接数max-active: 20 # 最大连接数max-wait: 60000 # 获取连接时的最大等待时间
配置文件中配置默认的数据源datasource,默认数据源中需要建立一张各租户的数据源表:

上图表中有redis-database字段为切换redis库时使用的字段,如不需要可自行修改。
创建DataSourceContextHolder用于切换数据源,使用threadlocal保留当前线程数据源信息:
@Slf4j
public class DataSourceContextHolder {private static final ThreadLocal<String> DATA_SOURCE = new ThreadLocal<>();/*** 切换数据源*/public static void setDataSource(String datasourceId) {DATA_SOURCE.set(datasourceId);log.info("已切换到数据源:{}",datasourceId);}public static String getDataSource() {return DATA_SOURCE.get();}/*** 删除数据源*/public static void removeDataSource() {DATA_SOURCE.remove();log.info("已切换到默认主数据源");}
}
继承AbstractRoutingDataSource实现根据不同请求切换数据源:
@Slf4j
@Data
public class DynamicRoutingDataSource extends AbstractRoutingDataSource {private boolean debug = true;/*** 存储注册的数据源*/private volatile Map<Object, Object> custom;@Overrideprotected Object determineCurrentLookupKey() {String datasourceId = DataSourceContextHolder.getDataSource();if(!StringUtils.isEmpty(datasourceId)){Map<Object, Object> map = this.custom;if(map.containsKey(datasourceId)){log.info("当前数据源是:{}",datasourceId);}else{log.info("不存在数据源:{}",datasourceId);return null;}}else{log.info("当前是默认数据源");}return datasourceId;}@Overridepublic void setTargetDataSources(Map<Object, Object> param) {super.setTargetDataSources(param);this.custom = param;}/*** @Description: 检查数据源是否已经创建* @param dataSource*/public void checkCreateDataSource(DatabaseList dataSource){String datasourceId = dataSource.getFactoryCode();Map<Object, Object> map = this.custom;if(map.containsKey(datasourceId)){//这里检查一下之前创建的数据源,现在是否连接正常DruidDataSource druidDataSource = (DruidDataSource) map.get(datasourceId);boolean flag = true;DruidPooledConnection connection = null;try {connection = druidDataSource.getConnection();} catch (SQLException throwAbles) {//抛异常了说明连接失效吗,则删除现有连接log.error(throwAbles.getMessage());flag = false;delDataSources(datasourceId);//}finally {//如果连接正常记得关闭if(null != connection){try {connection.close();} catch (SQLException e) {log.error(e.getMessage());}}}if(!flag){createDataSource(dataSource);}}else {createDataSource(dataSource);}}/*** @Description: 创建数据源* @param dataSource*/private void createDataSource(DatabaseList dataSource) {try {Class.forName("com.mysql.cj.jdbc.Driver");Connection connection = DriverManager.getConnection(dataSource.getUrl(), dataSource.getUser(), dataSource.getPassword());if(connection==null){log.error("数据源配置有错误,DataSource:{}",dataSource);}else{connection.close();}DruidDataSource druidDataSource = new DruidDataSource();druidDataSource.setName(dataSource.getFactoryCode());druidDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");druidDataSource.setUrl(dataSource.getUrl());druidDataSource.setUsername(dataSource.getUser());druidDataSource.setPassword(dataSource.getPassword());druidDataSource.setMaxActive(20);druidDataSource.setMinIdle(5);//获取连接最大等待时间,单位毫秒druidDataSource.setMaxWait(6000);String validationQuery = "select 1 from dual";//申请连接时执行validationQuery检测连接是否有效,防止取到的连接不可用druidDataSource.setTestOnBorrow(true);druidDataSource.setValidationQuery(validationQuery);druidDataSource.init();this.custom.put(dataSource.getFactoryCode(),druidDataSource);// 将map赋值给父类的TargetDataSourcessetTargetDataSources(this.custom);// 将TargetDataSources中的连接信息放入resolvedDataSources管理super.afterPropertiesSet();} catch (Exception e) {log.error("数据源创建失败",e);}}/*** @Description: 删除数据源* @param datasourceId*/private void delDataSources(String datasourceId) {Map<Object, Object> map = this.custom;Set<DruidDataSource> druidDataSourceInstances = DruidDataSourceStatManager.getDruidDataSourceInstances();for (DruidDataSource dataSource : druidDataSourceInstances) {if (datasourceId.equals(dataSource.getName())) {map.remove(datasourceId);//从实例中移除当前dataSourceDruidDataSourceStatManager.removeDataSource(dataSource);// 将map赋值给父类的TargetDataSourcessetTargetDataSources(map);// 将TargetDataSources中的连接信息放入resolvedDataSources管理super.afterPropertiesSet();}}}
}
接下来配置默认数据源,还有数据库连接池的信息,以及将数据源配置到sql工厂当中:
@Configuration
@Slf4j
public class DruidDBConfig {@Value("${spring.datasource.url}")private String dbUrl;@Value("${spring.datasource.username}")private String username;@Value("${spring.datasource.password}")private String password;@Value("${spring.datasource.driver-class-name}")private String driverClassName;@Value("${spring.datasource.druid.initial-size}")private int initialSize;@Value("${spring.datasource.druid.min-idle}")private int minIdle;@Value("${spring.datasource.druid.max-active}")private int maxActive;@Value("${spring.datasource.druid.max-wait}")private int maxWait;@Bean@Primary@Qualifier("mainDataSource")public DataSource dataSource() throws SQLException {DruidDataSource datasource = new DruidDataSource();// 基础连接信息datasource.setUrl(this.dbUrl);datasource.setUsername(username);datasource.setPassword(password);datasource.setDriverClassName(driverClassName);// 连接池连接信息datasource.setInitialSize(initialSize);datasource.setMinIdle(minIdle);datasource.setMaxActive(maxActive);datasource.setMaxWait(maxWait);//是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。datasource.setPoolPreparedStatements(false);datasource.setMaxPoolPreparedStatementPerConnectionSize(20);//申请连接时执行validationQuery检测连接是否有效,这里建议配置为TRUE,防止取到的连接不可用datasource.setTestOnBorrow(true);//建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。datasource.setTestWhileIdle(true);//用来检测连接是否有效的sqldatasource.setValidationQuery("select 1 from dual");//配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒datasource.setTimeBetweenEvictionRunsMillis(60000);//配置一个连接在池中最小生存的时间,单位是毫秒,这里配置为3分钟180000datasource.setMinEvictableIdleTimeMillis(180000);datasource.setKeepAlive(true);return datasource;}@Bean(name = "dynamicDataSource")@Qualifier("dynamicDataSource")public DynamicRoutingDataSource dynamicDataSource() throws SQLException {DynamicRoutingDataSource dynamicDataSource = new DynamicRoutingDataSource();dynamicDataSource.setDebug(false);//配置缺省的数据源dynamicDataSource.setDefaultTargetDataSource(dataSource());Map<Object, Object> targetDataSources = new HashMap<Object, Object>();//额外数据源配置 TargetDataSourcestargetDataSources.put("mainDataSource", dataSource());dynamicDataSource.setTargetDataSources(targetDataSources);return dynamicDataSource;}@Beanpublic SqlSessionFactory sqlSessionFactory() throws Exception {MybatisSqlSessionFactoryBean sqlSessionFactoryBean = new MybatisSqlSessionFactoryBean();sqlSessionFactoryBean.setDataSource(dynamicDataSource());//对新的SqlSessionFactory配置 修改mybatis-plus Page自动分页失效问题 以及 找不到xml问题MybatisConfiguration configuration = new MybatisConfiguration();configuration.addInterceptor(new MybatisPlusConfig().paginationInterceptor());sqlSessionFactoryBean.setConfiguration(configuration);sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:/mapper/*.xml"));return sqlSessionFactoryBean.getObject();}/*** @Description: 将动态数据加载类添加到事务管理器* @param dataSource* @return org.springframework.jdbc.datasource.DataSourceTransactionManager*/@Beanpublic DataSourceTransactionManager transactionManager(DynamicRoutingDataSource dataSource) {return new DataSourceTransactionManager(dataSource);}
}
现在就可以根据数据源表中唯一值切换数据源了,调用changeDB(数据源唯一值):
@ResourceDatabaseListService databaseListService;@Resourceprivate DynamicRoutingDataSource dynamicRoutingDataSource;@Overridepublic boolean changeDB(String datasourceId) {//切到默认数据源DataSourceContextHolder.removeDataSource();//找到所有的配置List<DatabaseList> databaseListList = databaseListService.list();if(!CollectionUtils.isEmpty(databaseListList)){for (DatabaseList d : databaseListList) {if(d.getFactoryCode().equals(datasourceId)){//判断连接是否存在,不存在就创建dynamicRoutingDataSource.checkCreateDataSource(d);//切换数据源DataSourceContextHolder.setDataSource(d.getFactoryCode());return true;}}}return false;}
以上就完成了所有步骤,可以切换数据源了。
在我的项目里,我在登录的拦截器中校验完权限后判断属于哪个数据源来切换。
下面说一下redis库的动态切换:
同样使用threadlocal保留当前线程的redis库,在get或set时设置redis数据库索引:
@Slf4j
@Component
public class RedisUtil {private static RedisTemplate redisTemplate;@Autowiredpublic void setRedisTemplate(RedisTemplate redisTemplate) {RedisUtil.redisTemplate = redisTemplate;}private static ThreadLocal<Integer> database = new ThreadLocal<Integer>();public static Integer getDatabase() {return (Integer) database.get();}public static void setDatabase(Integer db) {database.set(db);}/*** 设置数据库索引**/public static void setDbIndex() {//默认使用1Integer dbIndex = 1;if(database.get()!=null){dbIndex = database.get();}LettuceConnectionFactory redisConnectionFactory = (LettuceConnectionFactory) redisTemplate.getConnectionFactory();if (redisConnectionFactory == null) {return;}redisConnectionFactory.setDatabase(dbIndex);redisTemplate.setConnectionFactory(redisConnectionFactory);// 属性设置后redisConnectionFactory.afterPropertiesSet();// 重置连接redisConnectionFactory.resetConnection();}/*** 普通缓存获取** @param key 键* @return 值*/public static Object get(String key) {setDbIndex();return key == null ? null : redisTemplate.opsForValue().get(key);}/*** 普通缓存放入** @param key 键* @param value 值* @return true成功 false失败*/public static boolean set(String key, Object value) {setDbIndex();try {redisTemplate.opsForValue().set(key, value);return true;} catch (Exception e) {e.printStackTrace();return false;}}
1.3 原理解析
原理参考:https://blog.csdn.net/zhang_java_11/article/details/121626842?spm=1001.2014.3001.5506
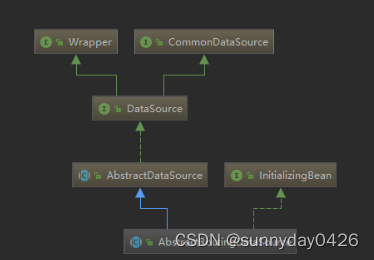
其实我们新建数据库连接的时候也是通过DataSource来获取连接的,这里的AbstractRoutingDataSource也是通过了DataSource中的getConnection方法来获取连接的。
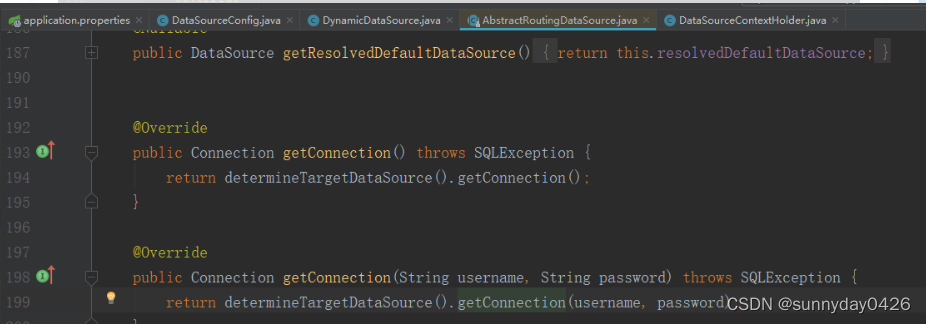
这个类里维护了两个Map来存储数据库连接信息:
@Nullable
private Map<Object, Object> targetDataSources; @Nullable
private Object defaultTargetDataSource;private boolean lenientFallback = true;private DataSourceLookup dataSourceLookup = new JndiDataSourceLookup();@Nullable
private Map<Object, DataSource> resolvedDataSources;@Nullable
private DataSource resolvedDefaultDataSource;下面对上面的几个属性进行说明:
- 其中第一个
targetDataSources是一个Map对象,在我们上面第五步创建DynamicDataSource实例的时候将多个数据源的DataSource类,放入到这个Map中去,这里的Key是枚举类,values就是DataSource类。
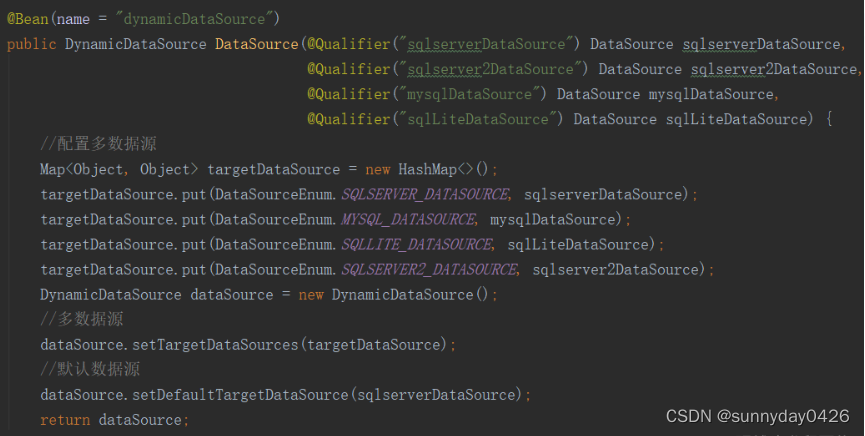
- 第二个
defaultTargetDataSource是默认的数据源,就是DynamicDataSource中唯一重写的方法来给这个对象赋值的。
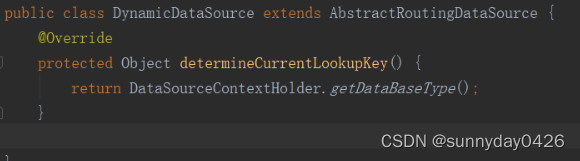
- 第三个
lenientFallback是一个标识,是当指定数据源不存在的时候是否采用默认数据源,默认是true,设置为false之后如果找不到指定数据源将会返回null.
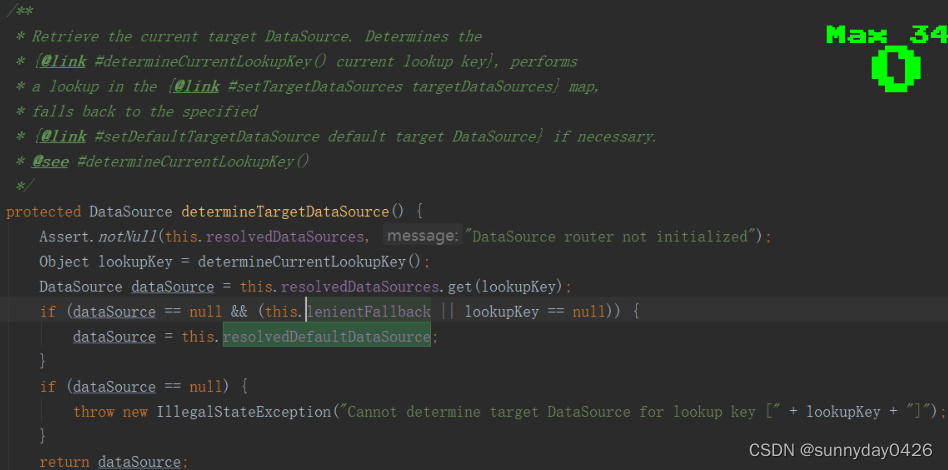
- 第四个
dataSourceLookup是用来解析指定的数据源对象为DataSource实例的。默认是JndiDataSourceLookup实例,继承自DataSourceLookup接口。 - 第五个
resolvedDataSources也是一个Map对象,这里是存放指定数据源解析后的DataSource对象。
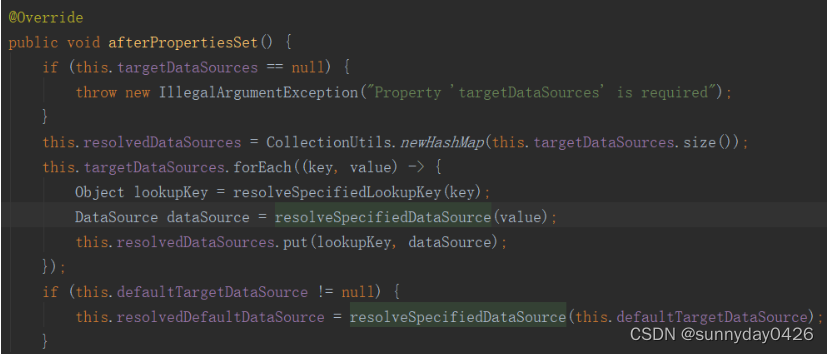
第六个resolvedDefaultDataSource是默认的解析后的DataSource数据源对象上面的getConnection方法就是从这个变量中拿到DataSource实例并获取连接的。
1.4 总结
多数据源切换的需求在我们日常开发中可能会经常碰到,主要是通过几个主要的类进行实现的,实现过程并不复杂,在此记录一下,希望能够帮助到有需要的童鞋。