1024共创程序世界
1024定为程序员节的缘由: 1024是2的十次方,是二进制计数的基本计量单位之一, 也是运行程序的基础,而且1024是程序员常用的数字。
程序员是从事程序开发、程序维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、中级程序员、软件设计师、系统分析员、系统架构师、测试工程师六大类。世界上第一-位程序员是洛夫莱斯。
这就是程序员的工作,程序员经常周末加班与工作日熬夜的情况,部分互联网机构倡议设立了1024程序员节,在这一天建议程序员拒绝加班。大众对程序员的认识普遍是身穿格子衫、背着双肩包、理工男、超级直男、发际线晚期患者等带有极大固定偏见的标签。
让我们一起庆祝这个1024节日,为所有的程序员都能够开开心心。
下面我们就介绍一种在日常写代码时的一些小工具帮助程序员更好的开发软件。
Lombok
1.介绍
lombok是一个插件,用途是使用注解给你类里面的字段,自动的加上属性,构造器,ToString方法,Equals方法等等,比较方便的一点是,你在更改字段的时候,lombok会立即发生改变以保持和你代码的一致性。
2.常用的 lombok 注解介绍
-
@Getter 加在类上,可以自动生成参数的getter方法。
-
@Setter 加在类上,可以自动生成参数的setter方法
-
@ToString 加在类上,调用toString()方法,可以输出实体类中所有属性的值
-
@RequiredArgsConstructor会生成一个包含常量,和标识了NotNull的变量的构造方法。生成的构造方法是私有的private。这个我用的很少。
-
@EqualsAndHashCode
-
(1).它会生成equals和hashCode方法
-
(2).默认使用非静态的属性
-
(3).可以通过exclude参数排除不需要生成的属性
-
(4).可以通过of参数来指定需要生成的属性
-
(5).它默认不调用父类的方法,只使用本类定义的属性进行操作,可以使用callSuper=true来解决,会在@Data中进行讲解。
-
-
@Data这个是非常常用的注解,这个注解其实是五个注解的合体:(提供类的get、set、EqualsAndHashCode、toString方法)
-
@NoArgsConstructor生成一个无参数的构造方法。
-
@AllArgsConstructor生成一个包含所有变量的构造方法。
3.idea安装lombok插件
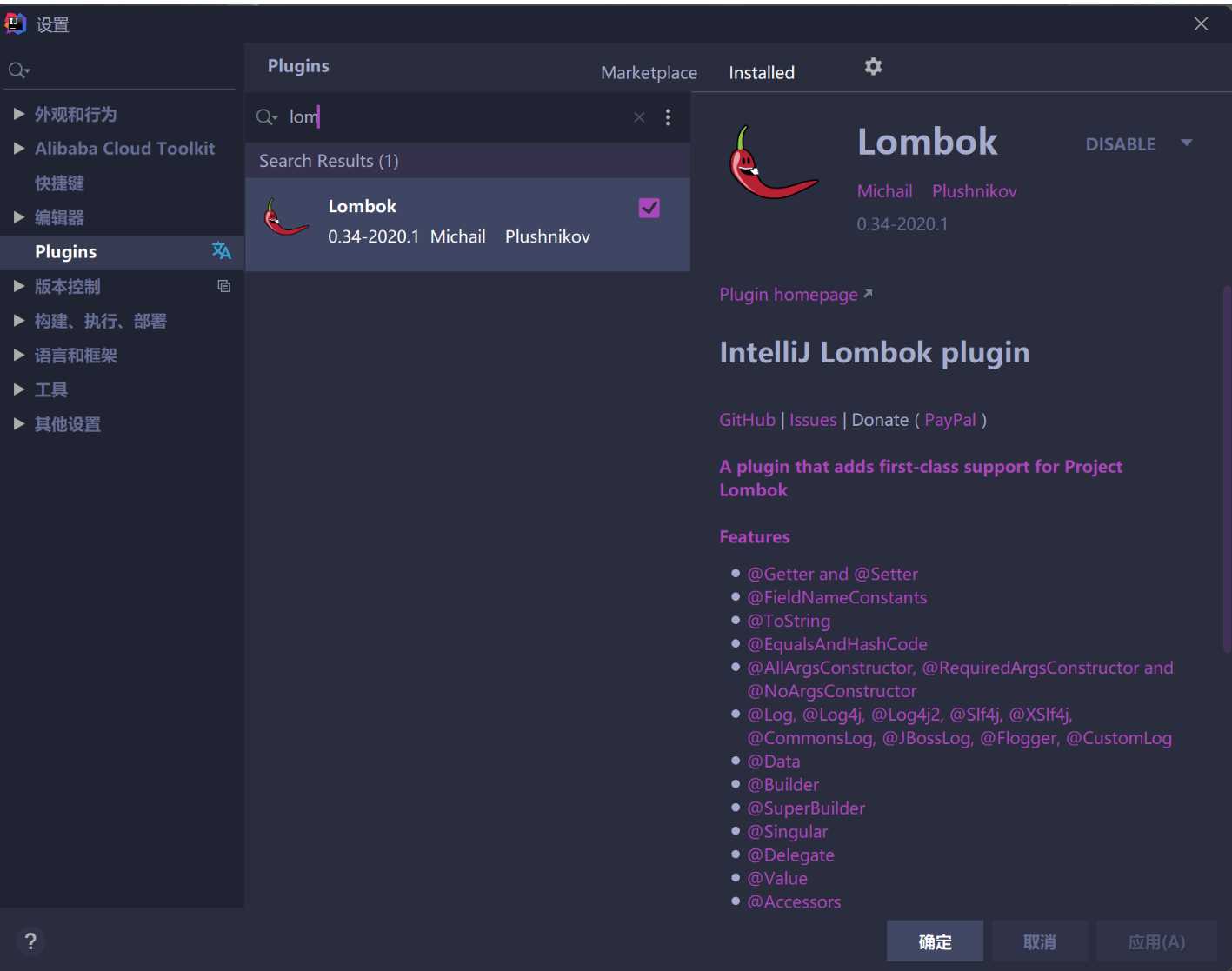
注意:安装完后一定要重启idea
4.使用
(1)在maven的pom.xml文件中引入lombok的依赖
<!--引入lombok依赖-->
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>
(2)在Employee类上添加lombok注解
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString
public class Employee {private Long empId;private String name;private String empGender;private Integer age;private String email;
}
/*
//@Getter
//@Setter
//@ToString
//@EqualsAndHashCode@Data //常用注解:
@AllArgsConstructor //全参数构造器@NoArgsConstructor //无参数构造器@TableName("employee") //能够和底层的数据库表明进行对应:*/