最近在整理目标检测损失函数,特将Fast R-CNN损失函数记录如下:

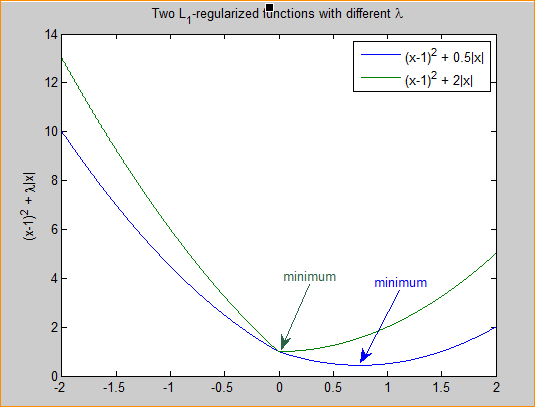
smooth L1 损失函数图像如下所示:
L1损失的缺点就是有折点,不光滑,导致不稳定。
L2 loss的导数(梯度)中包含预测值与目标值的差值,当预测值和目标值相差很大,L2就会梯度爆炸。说明L2对异常点更敏感。L1 对噪声更加鲁棒。
当差值太大时, loss在|x|>1的部分采用了 l1 loss,避免梯度爆炸。原先L2梯度里的x−t被替换成了±1, 这样就避免了梯度爆炸, 也就是它更加健壮。
总的来说:相比于L2损失函数,其对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
附录
(1)鲁棒性
最小绝对值偏差之所以是鲁棒的,是因为它能处理数据中的异常值。这或许在那些异常值可能被安全地和有效地忽略的研究中很有用。如果需要考虑任一或全部的异常值,那么最小绝对值偏差是更好的选择。
从直观上说,因为L2范数将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数来得大,因此模型会对这个样本更加敏感,这就需要调整模型来最小化误差。如果这个样本是一个异常值,模型就需要调整以适应单个的异常值,这会牺牲许多其它正常的样本,因为这些正常样本的误差比这单个的异常值的误差小。
(2)稳定性
最小绝对值偏差方法的不稳定性意味着,对于数据集的一个小的水平方向的波动,回归线也许会跳跃很大(如,在转折点处求导)。在一些数据结构上,该方法有许多连续解;但是,对数据集的一个微小移动,就会跳过某个数据结构在一定区域内的许多连续解。在跳过这个区域内的解后,最小绝对值偏差线可能会比之前的线有更大的倾斜。
相反地,最小平方法的解是稳定的,因为对于一个数据点的任何微小波动,回归线总是只会发生轻微移动;也就说,回归参数是数据集的连续函数。