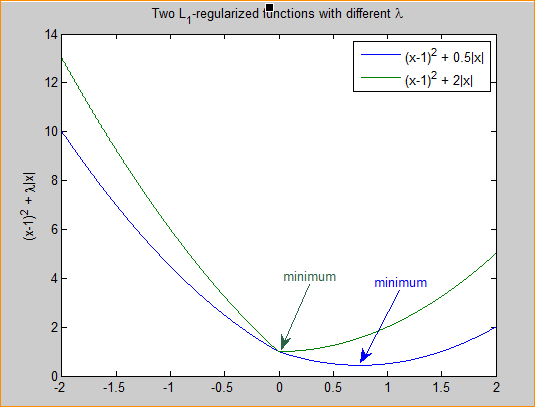
CPU缓存:通过优化的的读取机制,可以使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),
也就是说CPU下一次要读取的数据90%都在缓存(SRAM)中;
只有大约10%需要从内存(DRAM、DDR等)读取。
这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。

总的来说:CPU读取数据的顺序是先缓存后内存。
SRAM主要用于二级高速缓存(Level2 Cache)。它利用晶体管来存储数据。与DRAM相比,SRAM的速度快,但在相同面积中SRAM的容量要比其他类型的内存小。
CPU -----缓存------内存
SRAM的速度快但昂贵,一般用小容量的SRAM作为更高速CPU和较低速DRAM 之间的缓存(cache)
CPU内核集成的缓存称为一级缓存(L1 cache)静态SRAM,而外部的称为二级缓存(L2 Cache)动态DRAM;后来随着生产技术的不断提高,最终二级缓存也被挪进了CPU当中。
通常一级缓存中还分数据缓存(Data Cache,D-Cache)和指令缓存(Instruction Cache,I-Cache)。二者分别用来存放数据和执行这些数据的指令,而且两者可以同时被CPU访问,减少了争用Cache所造成的冲突,提高了CPU效能。
CPU的一级缓存L1 cache通常都是静态SRAM,速度非常的快,但是静态SRAM集成度低(存储相同的数据,静态SRAM的体积是动态DRAM的6倍),而且价格也相对较为昂贵(同容量的静态SRAM是动态RAM的四倍)。
扩大静态SRAM作为缓存是一个不太合算的做法,但是为了提高系统的性能和速度又必须要扩大缓存,这就有了一个折中的方法:在不扩大原来的静态SRAM缓存容量的情况下,仅仅增加一些高速动态DRAM做为L2级缓存。高速动态DRAM速度要比常规动态DRAM快,但比原来的静态SRAM缓存慢,而且成本也较为适中。一级缓存和二级缓存中的内容都是内存中访问频率高的数据的复制品(映射),它们的存在都是为了减少高速CPU对慢速内存的访问。
二级缓存是CPU性能表现的关键之一,在CPU核心不变化的情况下,增加二级缓存容量能使性能大幅度提高。而同一核心的CPU高低端之分往往也是在二级缓存上存在差异,由此可见二级缓存对CPU的重要性。
CPU在缓存中找到有用的数据被称为命中,当缓存中没有CPU所需的数据时(这时称为未命中),CPU才访问内存。从理论上讲,在一颗拥有二级缓存的CPU中,读取一级缓存的命中率为80%。也就是说CPU一级缓存中找到的有用数据占数据总量的80%,剩下的20%从二级缓存中读取。由于不能准确预测将要执行的数据,读取二级缓存的命中率也在80%左右(从二级缓存读到有用的数据占总数据的16%)。那么还有的数据就不得不从内存调用,但这已经是一个相当小的比例了。
目前的较高端CPU中,还会带有三级缓存,它是为读取二级缓存后未命中的数据设计的—种缓存,在拥有三级缓存的CPU中,只有约5%的数据需要从内存中调用,这进一步提高了CPU的效率,从某种意义上说,预取效率的提高,大大降低了生产成本却提供了非常接近理想状态的性能。除非某天生产技术变得非常强,否则内存仍会存在,缓存的性能递增特性也仍会保留。
CPU缓存
缓存大小是CPU的重要指标之一,并且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是同处理器同频运行,工作效率远远大于系统内存和硬盘。实际工作时,CPU经常需要重复读取同样的数据块,而缓存容量的增大能大幅提升CPU内部读取数据的命中率,不需要到内存或者硬盘上寻找,从而提升系统新能。但由于受限于CPU芯片成本和面积,缓存都很小。
L1 Cache(一级缓存)
L1 Cache(一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。一般服务器CPU的L1缓存的容量通常在32—256KB。
L2 Cache(二级缓存)
L2 Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。内部的芯片二级缓存运行速度与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的
性能,原则是越大越好,现在家庭用CPU容量最大是512KB,而服务器和工作站上用CPU的L2高速缓存更高达256KB—1MB。
L3 Cache(三级缓存)
L3 Cache(三级缓存)分为两种,早期的是外置,现在的都是内置的。而它的实际作用是进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力。而在服务器领域增加L3缓存在性能方面仍然有显著的提升。比方具有较大L3缓存的配置利用物理内存会更有效,故它比较慢的磁盘I/O子系统可以处理更多的数据请求。具有较大L3缓存的处理器提供更有效的文件系统缓存行为及较短消息和处理器队列长度。
存储器是用来存储程序代码和数据的部件
一.存储器的种类
其中的“易失/非易失”是指存储器断电后,它存储的数据内容是否会丢失的特性;
在计算机中易失性存储器最典型的代表是内存,非易失性存储器的代表则是硬盘

二.RAM
RAM 可随读取其内部任意地址的数据,时间都是相同的
1.动态随机存储器 DRAM(Dynamic RAM)
动态随机存储器 DRAM的存储单元以电容的电荷来表示数据,有电荷代表 1,无电荷代表 0,代表 1 的电容会放电,代表 0的电容会吸收电荷,因此它需要定期刷新操作,这就是“动态(Dynamic)”一词所形容的特性。

1)SDRAM
根据 DRAM的通讯方式,又分为同步和异步两种,这两种方式根据通讯时是否需要使用时钟信号来区分。

图 22-3 是一种利用时钟进行同步的通讯时序,它在时钟的上升沿表示有效数据。
由于使用时钟同步的通讯速度更快,所以同步 DRAM 使用更为广泛,这种 DRAM 被称为 SDRAM(Synchronous DRAM)。
2)DDR SDRAM
DDR SDRAM 存储器(Double DataRate SDRAM),它的存储特性与 SDRAM 没有区别,但 SDRAM只在上升沿表示有效数
据,在 1个时钟周期内,只能表示 1 个有数据;而 DDR SDRAM 在时钟的上升沿及下降沿各表示一个数据,也就是说在 1 个时钟周期内可以表示 2 数据,在时钟频率同样的情况下,提高了一倍的速度。至于 DDRII和 DDRIII,它们的通讯方式并没有区别,主要是通讯同步时钟的频率提高了。
当前个人计算机常用的内存条是 DDRIII SDRAM 存储器,在一个内存条上包含多个DDRIII SDRAM芯片。
2。静态随机存储器 SRAM(Static RAM)
静态随机存储器 SRAM 的存储单元以锁存器来存储数据,不需要定时刷新充电

同样地,SRAM 根据其通讯方式也分为同步(SSRAM)和异步 SRAM
DRAM与 SRAM的应用场合
可知 DRAM 的结构简单得多,所以生产相同容量的存储器,DRAM的成本要更低,且集成度更高;
而 DRAM中的电容结构则决定了它的存取速度不如 SRAM;
SRAM一般只用于 CPU内部的高速缓存(Cache),而外部扩展的内存一般使用 DRAM;
三、ROM
1.MASK ROM
MASK(掩膜) ROM就是正宗的“Read Only Memory”,存储在它内部的数据是在出厂时使用特殊工艺固化的,生产后就不可修改,其主要优势是大批量生产时成本低。
2.OTPROM
OTPROM(One Time Programable ROM)是一次可编程存储器。这种存储器出厂时内部并没有资料,用户可以使用专用的编程器将自己的资料写入,但只能写入一次,被写入过后,它的内容也不可再修改
3.EPROM(已淘汰,要用紫外线擦除,说实话,真滴是麻烦)
EPROM(Erasable Programmable ROM)是可重复擦写的存储器,擦除和写入都要专用的设备(使用紫外线照射芯片内部擦除数据)。现在这种存储器基本淘汰,被 EEPROM 取代
4.EEPROM
EEPROM(Electrically Erasable Programmable ROM)是电可擦除存储器,EEPROM 可以重复擦写,它的擦除和写入都是直接使用电路控制,不需要再使用外部设备来擦写。而且可以按字节为单位修改数据,无需整个芯片擦除。现在主要使用的 ROM 芯片都是EEPROM。
三、FLASH
FLASH 存储器又称为闪存,它也是可重复擦写的存储器,部分书籍会把 FLASH 存储器称为 FLASH ROM,但它的容量一般比 EEPROM 大得多,且在擦除时,一般以多个字节为单位。
而 NOR与 NAND特性的差别,主要是由于其内部“地址/数据线”是否分开导致的。 NOR 的地址线和数据线分开, NAND的数据和地址线共用;
NOR FLASH :一般应用在代码存储的场合,如嵌入式控制器内部的程序存储空间。
NAND FLASH: 一般应用在大数据量存储的场合,包括 SD卡、U盘、固态硬盘以及eMMC等,都是 NAND FLASH 类型的。
eMMC (Embedded Multi Media Card)是一种NAND Flash
DDR是一种DRAM