在Alpha-Beta算法被广泛运用后,对该算法的很多改进算法也相继被提出.这些改进算法主要在以下几个方面对Alpha-Beta算法进行改进[7]:
1. 择序(ordering).在搜索博弈树时,内部结点有多个可能的移动.择序指的是搜索这些分支的顺序.择序影响着搜索叶结点的个数,使得其数目在[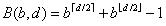 ,
,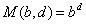 ]区间内变化.如果择序使得博弈树是随机的,那么所需搜索的叶结点的个数较多,如果择序使得博弈树是强有序的,那么所需搜索的叶结点的个数较少.
]区间内变化.如果择序使得博弈树是随机的,那么所需搜索的叶结点的个数较多,如果择序使得博弈树是强有序的,那么所需搜索的叶结点的个数较少.
在Alpha-Beta算法中,提高择序的好坏就意味着提高剪枝发生的概率.所以一个好的移动(sufficientor good move)可以定义为:
a. 导致剪枝的移动.
b. 或者如果没有导致剪枝,但是产生了最小最大值.
注意一个好的移动并不一定是最优的移动(best move),因为一个导致剪枝的移动可能引起了该子结点上的搜索停止,但是并不意味着其后的子结点的搜索不会产生一个更好的值(value).
2. 搜索窗口的大小.搜索窗口的大小指的是β和α之差.搜索窗口越小,发生剪枝的概率越大.
3. 信息的重用.保存子树的搜索结果,并审查这棵子树是否在随后的搜索中再次出现.如果该子树再次出现,那么关于子树的搜索结果的信息就可重复使用.
对Alpha-Beta算法比较常用的改进[8]将在下面介绍.
4.1 吸出搜索(Aspirationsearch)
为了保证Alpha-Beta搜索能返回最大最小值,一般将搜索的窗口设置为[-∞,+∞].如果能够同过一种有效的方法就出最大最小值的估计值V及其误差范围e,那么搜索窗口上下限可以设的更紧一些[V - e, V + e].这样做虽然可能导致搜索不能返回正确的最大最小值,但是也有可能更快地找到正确最大最小值.当发现返回的值不处在预测的范围之内时,需要重新进行搜索.如果由于缩小窗口而节省的开销大于由于重新搜索而增加的开销,则搜索速度得到了提升.
普通的Alpha-Beta搜索一般按照如下方式调用函数发起对博弈树的搜索:
1: node ← root
2: AlphaBeta(node, -∞, +∞)
吸出搜索使用如下策略发起对博弈树的搜索:
1: node ← root
2: V ← estimated_value(node)
3: e ← expected_error_limit(node)
4: alpha ← V - e
5: beta ← V + e
6: V ← AlphaBeta(node, alpha, beta)
7: if V ≥ beta then
8: V ← AlphaBeta(node, -∞, beta)
9: if V ≤ alpha then
10: V ← AlphaBeta(node, alpha, +∞)
4.2 转移表(Transposition Table)
转移表是一个大的直接访问表(direct access table),表中存储了已经搜索过的结点(或者子树)的搜索结果,包括子树的博弈值,最佳移动(best move)和位置.不管该子树是搜索完全得到了博弈值,还是只是完成部分搜索得到缩小的搜索窗口,由于重新搜索一个曾经搜索过的位置经常发生,所以使用转移表可以达到一些提高搜索效率的目的.首先,可能可以通过使用转移表来缩小搜索窗口.其次,以前的最佳移动被率先尝试,而这个移动可能曾经导致了一个剪枝,并有可能再次引发剪枝.跟进一步的,如果该子树已经搜索完成,那么根本没有必要再次搜索,只需要返回转换表中的博弈值即可.
下面的程序就是使用转移表的Alpha-Beta算法[8]:
AlphaBeta(node, alpha, beta)
1: (length, score, flag) ← Retrieve(node, node.opt)
2: if length ≥ node.depth then
3: if flag = VALID then
4: return score
5: if flag = LBOND then
6: alpha ← Max(alpha, score)
7: if alpha ≥ beta then
8: return score;
9: if depth ≤ 0 then
10: return EvaluateNegaMax(node)
11: for i ← 1 to node.branch.length
12: new_node ← Traverse(node, node.branch[i])
13: value ← -AlphaBeta(new_node, -beta, -max(alpha, score))
14: if value > score then
15: score ← value
16: node.opt ← node.branch[i]
17: if score ≥ beta then
18: goto done
19:done:
20: flag ← VALID
21: if score ≤ alpha then
22: flag ← UBOUND
23: if score ≥beta then
24: flag ← LBOUND
25: if length ≤ depth then
26: Store(node, depth, score, flag, node.opt);
在上述伪代码中,对转换表中的表项,flag用来标识该表项对应子树的搜索是否搜索完成.如果flag为VALID则表明搜索完成,score就是该子树的博弈值,否则,flag为LBOND或UBOND则表明搜索不完全,score只能用来修改搜索窗口的上下限.由于一个位置可能以不同的搜索深度搜索多次,所以用表项的length和结点的depth对比,如果length比depth小,则表明表项中的数据不满足当前搜索深度的要求,不能使用.Retrieve()和Store()分别用来在转移表中读出或写入表项.
转移表的一大缺点是对内存空间要求大.如果对每个不同的结点都维护一个表项,那么当博弈树的深度d很大时,转移表将非常之大.所以在内存有限的情况下,不得不对转移表分配有限大小,并采用散列地方式管理存取.
4.3 驳斥表(Refutation Table)
在迭代深化搜索中,只有使用了存储表(例如转移表或者驳斥表)来指导其迭代搜索才能获得较好的搜索效率.相对于转移表,驳斥表尝试保留转移表的一些优点,但使用较少的存储空间.在每次迭代时,由根结点出发,有b个可能移动.对每个移动,驳斥表存储其子树的主变量.由于本次迭代得到各子树的主变量很可能是下次迭代的主编量的前缀,所以在下次迭代中再次尝试主变量的移动序列,可以提高搜索的效率.变量(variation,或曾用的continuation)指的是博弈双方从初始位置到另一个位置所经过的移动,反映在博弈树中就是从博弈树的根结点到某一个非根结点所经过的边.主变量(principal variation,或者principal continuation)指的是在博弈树或者其子树中,博弈双方达到对各自均最优的位置所经过的移动.由于主变量的最优性,所以子树的主变量也是对该移动的最好的驳斥(refutation).
在驳斥表中,只有移动序列是重要的,这是因为:在当前迭代中,搜索深度大于上次迭代的搜索深度,所以上次迭代获得的博弈值不能重用.因而驳斥表中只需要存储主变量,像转移表那样存储上次迭代的博弈值是没有必要的.深度为d的迭代搜索,驳斥表只需要消耗O(d*b)的内存空间.这相对于转移表,内存需求是很小的.而且,如果d并不大(例如小于6),那么驳斥表能获得和转移表一样的搜索效率.
4.4 迭代深化(Iterative Deepening)
迭代深化搜索[9](Iterative deepening search, IDS)或者(迭代深化深度优先搜索,Iterative deepeningdepth-first search)是一种常用的搜索机制,经常使用在深度优先搜索中.通过逐渐地提高深度限制搜索(Depth-limited search)的深度限制(depth limit)——从1开始,然后2,一直到找到目标结点位置为止——迭代深化搜索能够找出最好的深度限制.深度限制搜索指的是在深度优先搜索中,引入深度限制limit,如果从根结点出发到结点N的深度为limit,那么N被当做没有子结点的叶结点那样处理.
迭代深化搜索也许看起来比较浪费时间,因为状态有可能被多次产生.但是事实并非如此,因为大多数的结点处在底层,而底层结点的搜索次数很少.对于一个深度为d,分支因子为b的树,.最多需要搜索的结点个数为:
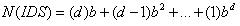
故此迭代深化搜索的时间复杂度和深度优先搜索的一样是O( )
)
将迭代深化应用到Alpha-Beta算法中,有许多的好处.其中之一是便于时间控制.在搜索时间受限的情况下,搜索整个博弈树也许会花费太多的时间.如果使用迭代深化搜索,即使搜索由于时间限制必须停止,上次迭代的博弈值也是一个可以接受的解.
迭代深化的另一个优点是,每次迭代都可以为下次迭代收集有用的信息.例如以下几种情形:
a.上次迭代的主变量(principalvariation)经常是当前迭代的主变量的方向标.如果率先搜索上次迭代的主变量的分支,很有可能提高搜索的效率.
b.上次迭代可能保有了一些关键分支的优劣信息.如果当前迭代使用这些信息对分支的择序进行排序,可以提高搜索的性能.
c.上次迭代返回的博弈值很有可能是当前迭代返回的博弈值的一个很好的估计.所以上次迭代返回的博弈值可以用来设置当前迭代的搜索窗口.例如下面的Alpha-Beta算法[1]就使用了迭代深化策略,主要思想就是:使用上次迭代后得到的博弈值,为当前迭代的搜索窗口估值,并使用吸出搜索,计算当前迭代的博弈值.
1: node ← Root
2: V ←initial_estimate
3: for d ← 1 to depth
4: node.depth ← d
5: alpha ← V - e
6: beta ← V + e
7: score = AlphaBeta(node, alpha, beta)
8: if score = beta then
9: score = AlphaBeta(node, beta,+1)
10: elsif score = alpha then
11: score = AlphaBeta(node, +∞, alpha)
12: V ← score
4.5 主变量搜索(Principal Variationsearch)
主变量搜索(Principal Variation Search,简称PVS),又被称作最小窗口搜索(Minimal window Search),或者NegaScout算法.它基于这样的基本思想:在一个强有序的博弈树中,每个结点上第一个移动很有可能是最好,而且证明一个子树是低劣的(inferior)比求出该子树的博弈值所花费的时间少.
基于这个思想,最小窗口算法假设每个结点上第一个移动是最好的,并尝试不断证明接下来的移动是相对低劣的,直到证明这个假设是错误的为止.最小窗口算法对每个结点的第一个子树,使用完全的搜索窗口[α, β],进行完全搜索(exhaustively search),得到该子树的博弈值V,对该结点的剩余子树,使用最小的搜索窗口[V, V + 1]进行搜索,以快速找出该子树是否相对低劣,如果证明当前子树不是低劣的,则需要重新搜索该子树,并修改博弈值V.这种最小的窗口又称为零窗口(Null Window).
一个最小窗口搜索的伪代码如下所示[1]:
Negascout(node, alpha, beta)
1: if node.depth = 0 then
2: return EvaluateNegaMax(node)
3: new_node ← Traverse(node, node.branch[1])
4: value ← -Negascout(new_node,-beta,-alpha)
5: if value ≥ beta then
6: return beta
7: if value > alpha then
8: alpha ← value
9: for i ← 2 to node.branch.length
10: new_node ← Traverse(node, node.branch[i])
11: value ← -Negascout(new_node,-alpha - 1,-alpha)
12: if value > alpha and value < beta then
13: value ← -Negascout(new_node,-beta,-alpha - 1)
14: if value ≥beta then
15: return beta
16: if value > alpha then
17: alpha ← value
18: return alpha
PVS搜索在博弈树是强有序的情况下,搜索效率较高.
4.6 杀手启发(Killer Heuristic)
杀手启发基于这样一个前提[6]:如果移动My驳斥(refute)了移动Mx,My也很有可能会在其他的位置发生作用.其中My称为一个杀手移动(killer move).对任何一个处于N层的移动,如果它导致了一个剪枝,那么称它驳斥了N-1层的移动.如果在博弈树中,从根结点到一个移动的深度为N,则称该移动处于N层(level).
杀手启发可以用来对移动进行动态重排序(dynamically reorder).例如N层的移动(My)驳斥了N-1层的移动.如果My移动在N-2层是合法的,那么值得在该位置按序搜索其他移动之前,率先尝试My移动.使用杀手启发的另一个好处是提高了转换表的用处,因为通过反复地尝试杀手移动,使得达到的位置在转换表中有对应的表项的概率很大.
4.7 历史启发(History Heuristic)
在博弈树中,同样的一个移动可能在不同的结点出现很多次.历史启发(HistoryHeuristic)[7]的基本思想是:维护每种不同移动的历史,记录移动对产生最佳博弈值方面有多成功,在搜索的时候,按照移动的历史来排位来对子树的搜索进行择序.
一个使用历史得分(history score),来实现历史启发的Alpha-Beta算法的伪代码如下所示[7]:
AlphaBeta(node, alpha, beta)
1: if node.depth = 0 then
2: return EvaluateNegaMax(node)
3: for i ← 1 to node.branch.length
4: rating[i] = HistoryTable[node.move[i]]
5: Sort(node.branch, rating)
6: score ← -∞
7: for i ← 1 to node.branch.length
8: new_node ← Traverse(node, node.branch[i])
9: value ← -AlphaBeta(new_node, -beta, -alpha)
10: if value ≥ score then
11: score ← value
12: if score ≥ beta then
13: bestmove ← node.move[i]
14: goto done
15: if score > alpha then
16: alpha ← value
17:done:
18: HistoryTable[bestmove] = HistoryTable[bestmove] + 1<<node.depth
10: return score
在上述的伪代码中,历史表HistoryTable的每一项都对应着一种不同移动.如果在结点node处,一个移动称为最好的移动,那么历史表的对应表项就上 的分值.
的分值.
在Alpha-Beta算法中,内部结点分支的择序对搜索的效率影响非常大.相对于随机择序和基于知识(knowledge-based)的择序,历史启发是一种基于经验的择序标准.基于知识的择序存在着一些缺点:首先它是静态的,不能适应条件的变化,其次,它不能很好地处理意外情况.这两个缺点可以归结为一个问题,就是知识的不足(inadequate knowledge).一个实际问题的知识太多了,以至于设计者不得不在成本和效率之间做折中的选择.历史启发却使得算法的择序具有很强的动态适应性.同时应该注意到,杀手启发实际是历史启发的特例.
4.8 MTD(f)算法
MTD(f)(MTD(n, f)的简称,其含义是Memory-enhanced Test Driver with node n and value f)算法[10]基于两个思想:相比较宽的搜索窗口,零窗口可以产生更多的剪枝,可以通过转移表,使得之前的搜索不需重新进行,从而将多个零窗口的搜索粘合(glue together).
MTD(f)不断地使用零窗口进行搜索,然后根据搜索结果,不断调整零窗口的位置,故此零窗口的初始位置的选择也很重要.一个较好地预测窗口初始位置的办法是引入迭代深入方法,将上次迭代的博弈值作为当前迭代的窗口位置.
一个使用迭代深入方法的MTD(f)算法的伪代码如下:
MTDF(root, f, depth)
1: g ← f
2: upperbound ← +∞
3: lowerbound ← -∞
4: repeat
5: if g = lowerbound then
6: beta ←g + 1
7: else
8: beta ← g
9: g ← AlphaBetaWithMemory(root, beta - 1, beta, depth)
10: if g < beta then
11: upperbound ← g
12: else
13: lowerbound ← g
14: until lowerbound ≥ upperbound
15: return gIterative_deepening(root)
1: firstguess ← 0
2: for depth = 1 to MAX_SEARCH_DEPTH do
3: firstguess ← MTDF(root, firstguess, depth)
4: if times_up() then
5: break
6: return firstguess
其中Iterative_deepening()函数将上次迭代获得的博弈值传给MTDF()函数作为初始窗口位置,并从该函数取得当前迭代的博弈值.AlphaBetaWithMemory()函数使用Alpha-Bet算法,并使用转移表存储已搜索结点的结果.
本文章欢迎转载,请保留原始博客链接http://blog.csdn.net/fsdev/article
--------------------
[1] Valavan Manohararajah(2001). Parallel Alpha-Beta Search on SharedMemory Multiprocessors. Master’s thesis, Graduate Department of Electrical andComputer Engineering, University of Toronto, Canada.
[2] A. Newell and H.A. Simon (1972). Human Problem Solving.Prentice-Hall, 1972.
[3] Stuart Russell and Prter Norvig (1995). Artificial Intelligence, AModern Approach. Prentice-Hall, Egnlewood Cliffs, 1995.
[4] Knuth, D.E. and Moore, R.W. (1975). An Analysis of Alpha-Beta Pruning.Artificial Intelligence, 6:293–326.
[5] Hopp, Holger and Sanders, Peter (1995). Parallel Game Tree Search onSIMD Machines. IRREGULAR '95: Proceedings of the Second International Workshopon Parallel Algorithms for Irregularly Structured Problems. 349-361.
[6] Marsland, T.A. and Campbell, M.S. (1982). Parallel Search ofStrongly Ordered Game Trees. ACM Computing Surveys, Vol. 14, No. 4, pp.533-551. ISSN 0360-0300.
[7] Schaeffer J.(1989). The History Heuristic and Alpha-Beta SearchEnhancements in Practice. IEEE Transactions on Pattern Analysis and MachineIntelligence. Vol. PAMI-11, No.11, pp. 1203-1212.
[8] Marsland, T.A. (1986). A Review of Game-Tree Pruning. ICCA Journal,Vol. 9, No. 1, pp. 3-19. ISSN 0920-234X.
[9] Korf , R.E. (1985). Depth-first Iterative-deepening Search: AnOptimal Admissible Tree Search. Artificial Intelligence, 27(1), 97-109.
[10] Aske Plaat, Jonathan Schaeffer,Wim Pijls, and Arie de Bruin(1995). Best-First and Depth-First Minimax Searchin Practice. In Proceedings of Computing Science in the Netherlands 1995,Utrecht, the Netherlands, November 27-28, 1995, pages 182-193.