一、jquery发送ajax请求格式
"""
形式:$.ajax({name:val, name:val,...});
可选字段:
1)url:链接地址,字符串表示
2)data:需发送到服务器的数据,GET与POST都可以,格式为{A: '...', B: '...'}
3)type:"POST" 或 "GET",请求类型
4)timeout:请求超时时间,单位为毫秒,数值表示
5)cache:是否缓存请求结果,bool表示
6)contentType:内容类型,默认为"application/x-www-form-urlencoded"
7)dataType:服务器响应的数据类型,字符串表示;当填写为json时,回调函数中无需再对数据反序列化为json
8)success:请求成功后,服务器回调的函数
9)error:请求失败后,服务器回调的函数
10)complete:请求完成后调用的函数,无论请求是成功还是失败,都会调用该函数;如果设置了success与error函数,则该函数在它们之后被调用
11)async:是否异步处理,bool表示,默认为true;设置该值为false后,JS不会向下执行,而是原地等待服务器返回数据,并完成相应的回调函数后,再向下执行
12)username:访问认证请求中携带的用户名,字符串表示
13)password:返回认证请求中携带的密码,字符串表示"""
$.ajax({url: "/greet",data: {name: 'jenny'},type: "POST",dataType: "json",success: function(data) {// data = jQuery.parseJSON(data); //dataType指明了返回数据为json类型,故不需要再反序列化...}
});
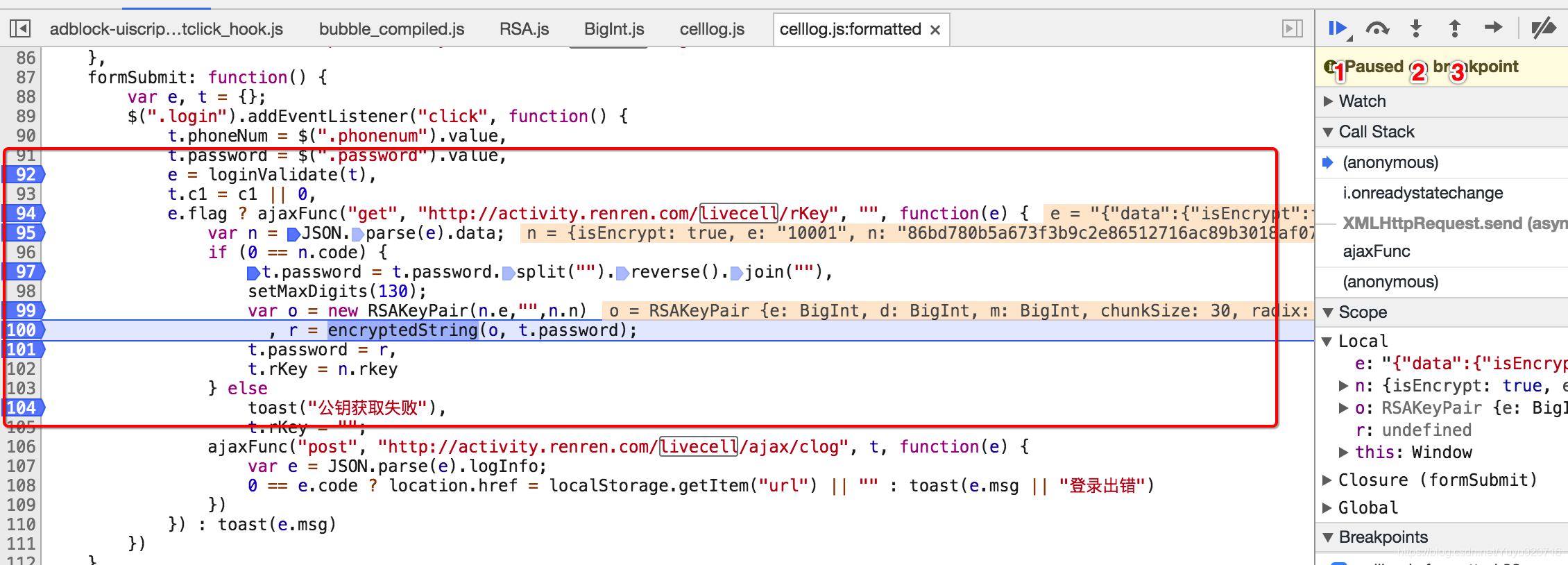
二、 2请求方式get或者post post请求会携带参数
参数可能是加密的

3、请求回来的数据对应的回调函数 响应数据可能也是加密的

3、执行js代码获取数据