一、什么是爬虫
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定规则,自动的抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
- 搜索引擎
- 今日头条/网易新闻
- .抢票软件
- 最终都指向的是 12306
- 比价网
- ·淘宝
- 京东
- 拼多多
在生活中网络爬虫经常出现,搜索引擎就离不开网络爬虫。例如,百度搜索引擎的爬虫名字叫作百度蜘蛛(Baiduspider)。百度蜘蛛,是百度搜索引擎的一个自动程序。它每天都会在海量的互联网信息中进行爬取,收集并整理互联网上的网页、图片视频等信息。当用户在百度搜索引擎中输入对应的关键词时,百度将从收集的网络信息中找出相关的内容,按照一定的顺序将信息展现给用户。
二、接口抓取
如果网站提供了接口,那么就直接请求获取接口得到数据
// 请求获取接口数据// 前端发请求:
// XMLHttpRequest:axios
// Fetch// Node.js 发请求
// tcp 模块,最麻烦
// http 模块,
// const http = require('http')
// http.request()
// 为了方便,也有一些封装好的第三方库:request、axios
// axios 既可以在浏览器使用也可以在 Node 中使用
// 1. 都是 JavaScript
// 2. 在不同的平台做了适配,浏览器:XMLHttpRequest,Node:httpconst axios = require('axios')axios({url: 'https://blackhole-m.m.jd.com/getinfo',method: 'POST',// params: {}, // 查询参数data: {appname: 'jdwebm_pv',jdkey: '',isJdApp: false,jmafinger: '',whwswswws: 'eQY7noLwJFCJEuiO9SCt4Tw',businness: 'ProDetail',body: {sid: '80ff0fd789ec316ae0c222d686a51c2d',squence: '4',create_time: '1647001099375',shshshfpa: 'b0271365-4825-0def-83a7-9c6dc52c94a6-1647001029',ecflag: 'e',whwswswws: 'eQY7noLwJFCJEuiO9SCt4Tw',jdkey: '',isJdApp: false,jmafinger: '',browser_info: '23b8dc51f2f5538686ab08c97bf506a4',page_name: 'https://item.jd.com/100016777690.html',page_param: '',cookie_pin: '',msdk_version: '2.4.4',wid: '',pv_referer: 'https://list.jd.com/',lan: 'zh-CN',scrh: 864,scrah: 816,scrw: 1536,scaw: 1536,oscpu: '',platf: 'Win32',pros: '20030107',temp: 33,hll: false,hlr: false,hlo: false,hlb: false}} // 请求体数据// headers: {} // 请求头
}).then(res => {console.log(res.data)
})三、网页抓取
一些安全性比较高的网站会设置反爬虫,一般会校验请求头user-agent字段,判断请求来源(当然不全是)
const axios = require('axios')
const fs = require('fs')
const cheerio = require('cheerio') // 类似jq,在node环境下操作domconst getPage = async () => {const { data } = await axios.get('https://item.jd.com/100016777690.html', {headers: {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.36'}})return data// data 是什么?字符串// fs.writeFileSync('jd.html', data)// console.log('抓取网页成功')
}// const main = async () => {
// // const pageData = await getPage()
// const $ = cheerio.load(`
// <!DOCTYPE html>
// <html lang="en">
// <head>
// <meta charset="UTF-8" />
// <meta http-equiv="X-UA-Compatible" content="IE=edge" />
// <meta name="viewport" content="width=device-width, initial-scale=1.0" />
// <title>Document</title>
// </head>
// <body>
// <h1>hello</h1>
// <p id="p1" foo="bar">我是 p1</p>
// <p id="p2">我是 p2</p>
// <p id="p3">我是 p3</p>
// </body>
// </html>
// `)
// console.log($('#p1').text())
// console.log($('#p1').attr('foo'))
// console.log($('#p2').text())
// $('#p1').addClass('abc')
// console.log($.html())
// }const main = async () => {const pageData = await getPage()const $ = cheerio.load(pageData)console.log(`标题:${$('.sku-name').text().trim()}价格:${$('.price').text().trim()}`)
}main()四、puppeteer
puppeteer是chrome团队开发的一个node库,可以通过api来控制浏览器的行为(模拟浏览器),比如点击、跳转、刷新,在控制台执行javascript脚本等。通过这个工具可以用来处理爬虫、制动签到、网页截图、生成pdf、自动化测试等。
const puppeteer = require('puppeteer');(async () => {// 1. 打开浏览器const browser = await puppeteer.launch()// 2. 新建一个标签页const page = await browser.newPage()// 3. 输入地址敲回车await page.goto('https://item.jd.com/100016777690.html')// 4. 操作:// 对加载完毕的网页进行截图await page.screenshot({ path: '100016777690.png' })// 5. 关闭浏览器await browser.close()
})()
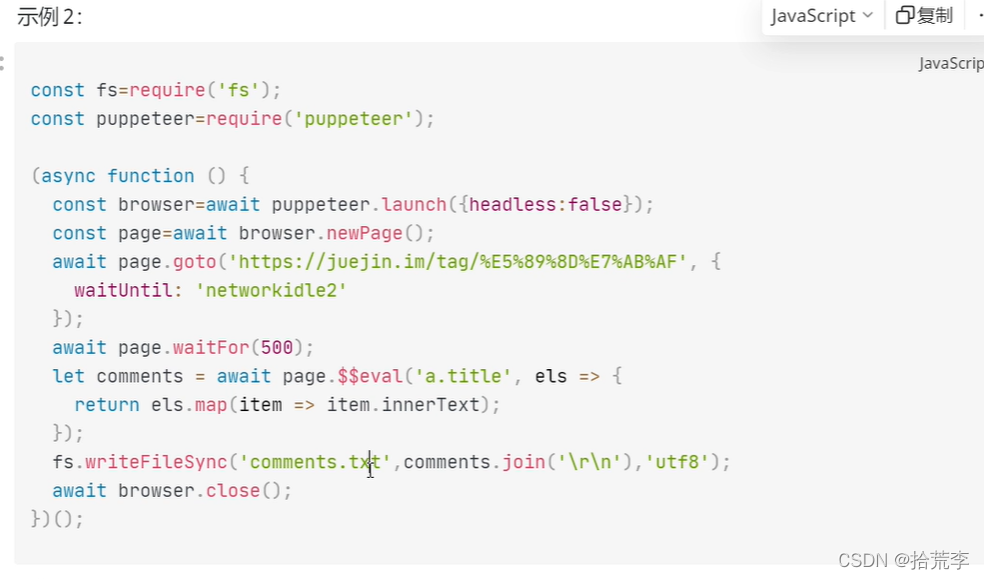
五、抓取文章
const cheerio = require('cheerio')
const axios = require('axios')
const url = require('url')
const fs = require('fs')const request = axios.create({baseURL: 'https://cnodejs.org/' // 基础路径
})const getLastPage = async () => {const { data } = await request({method: 'GET',url: '/',params: { // tab=all&page=1tab: 'all',page: 1}})const $ = cheerio.load(data)const paginations = $('.pagination a')const lastPageHref = paginations.eq(paginations.length - 1).attr('href')const { query } = url.parse(lastPageHref, true)return query.page
}// 需求:获取 cnodejs.org 网站所有的文章列表(文章标题、发布时间、文章内容)
// 并且将该数据存储到数据库中// 获取所有文章列表
const getArticles = async () => {const lastPage = await getLastPage()const links = []for (let page = 1; page <= lastPage; page++) {const { data } = await request({method: 'GET',url: '/',params: { // tab=all&page=1tab: 'all',page}})const $ = cheerio.load(data)$('.topic_title').each((index, element) => {const item = $(element) // 转换为 $ 元素links.push(item.attr('href'))})// 每次抓取完一页的数据就等待一段时间,太快容易被发现await new Promise(resolve => {setTimeout(resolve, 500)})console.log(links.length)}return links
}// 获取文章内容
const getArticleContent = async (url) => {const { data } = await request({method: 'GET',url})const $ = cheerio.load(data)const title = $('.topic_full_title').text().trim()const changes = $('.changes span')const date = changes.eq(0).text().trim()const author = changes.eq(1).find('a').text().trim()const content = $('.markdown-text').html()return {title,author,date,content}
}const main = async () => {// 1. 获取所有文章列表链接const articles = await getArticles()// 2. 遍历文章列表for (let i = 0; i < articles.length; i++) {const link = articles[i]const article = await getArticleContent(link)fs.appendFileSync('./db.txt', `
标题:${article.title}
作者:${article.author}
发布日期:${article.date}
文章内容:${article.content}
\r\n\r\n\r\n\r\n
`)console.log(`${link} 抓取完成`)await wait(500)}
}main()function wait (time) {return new Promise(resolve => {setTimeout(() => {resolve()}, time)})
}