每日分享:
做人要狠
任何关系,合得来就合,合不来就散,没有什么大不了的,理解多了,迁就多了,顾忌多了,痛苦自然就多了,完全没这个必要。别说我狠,以前我比谁都善良,可他们都把我当傻子。
你怕的越多,欺负你的人就越多;什么都不怕了,反倒没人敢欺负你,甚至讨好你。现实教导我,好心没好报,该狠就得狠,人善被人欺,马善被人骑。
别问我为什么,生活告诉我的。
- 了解定位js的方法
- js2py简介
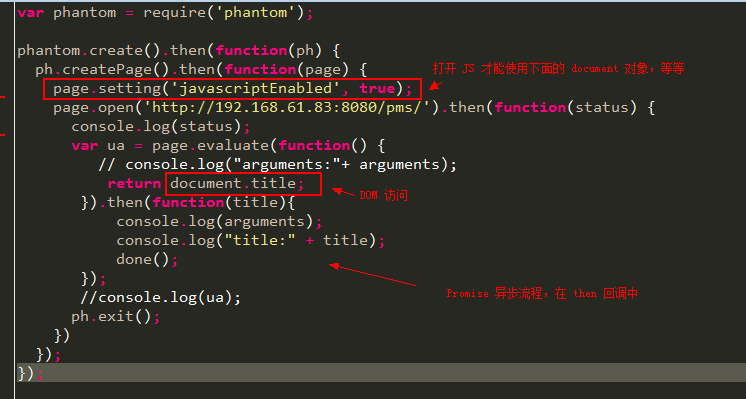
一、确定js的位置
url地址中有表单数据(里面有一些参数),这些参数部分是由js生成的,想要获取这些参数的规律,就要找到对应的js
- 通过initiator(发起程序)定位到is文件

- 通过search搜索(ctrl+f)关键字定位到js文件

- 通过元素绑定的事件监听函数找到js文件

二、js2py简介
确定js文件的位置后,我们需要观察来知道js是如何生成我们想要的数据的,之后再使用程序获取js执行后的结果
2.1 js2py的介绍
js2py是一个js的翻译工具,也是一个通过纯python实现的js的解释器
2.2 js的执行思路
js的执行的方式大致分为两种:
- 在了解了js内容和执行顺序后,通过python来完成js的执行过程,得到结果
- 在了解了js内容和执行顺序后,使用类似js2py的模块来执行js代码,得到结果
但是在使用python程序实现js的执行的时候,需要观察js的每一个步骤,非常麻烦,所以更多的时候我们会选择类似js2py的模块去执行js。