之前的NLP课程作业要求爬取一些科技新闻来训练语言模型,本文就简单来说一说用Python来爬取新闻的过程。虽然以前写过简单的爬虫,但是没有处理过浏览器动态加载数据的情况,这次碰到了就记录一下。
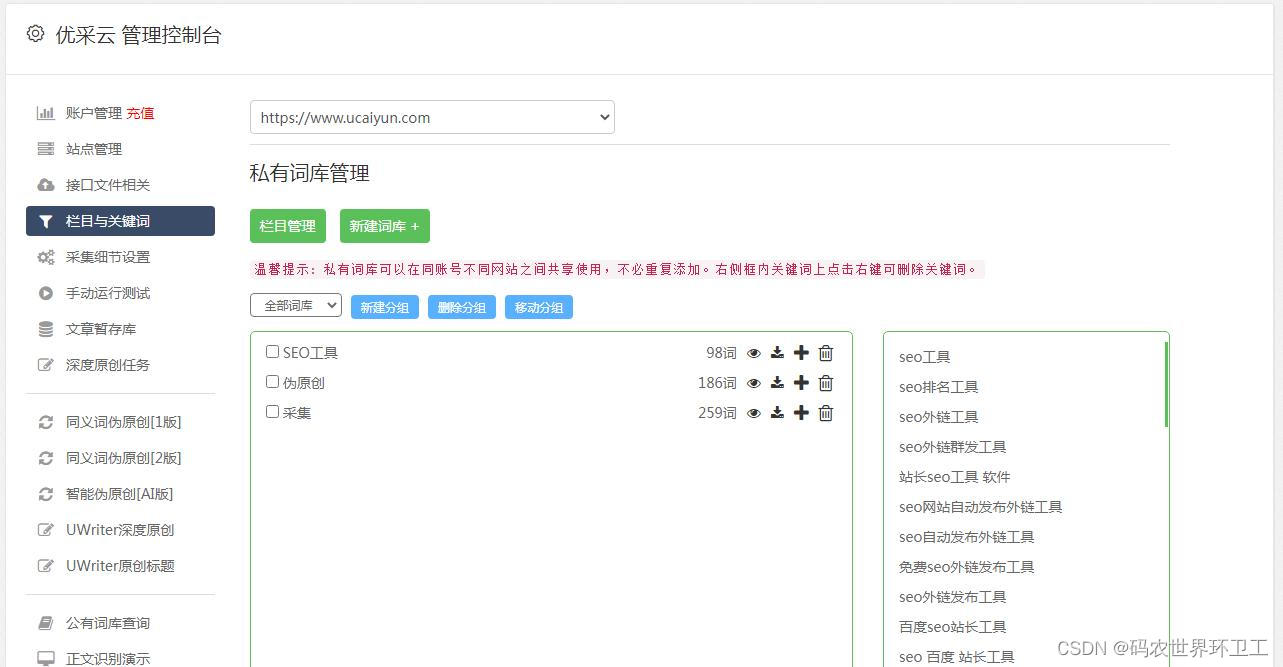
这次爬取的新闻来源是 新浪科技滚动新闻,打开之后网页长这样:

该网页中包含了50条新闻,我们希望拿到上图中的新闻链接,然后发送request请求来得到新闻内容。但是查看该网页的源码后发现,这些新闻的链接并不在其中,所以猜测该网页是通过js动态加载得到数据,然后再放入页面。
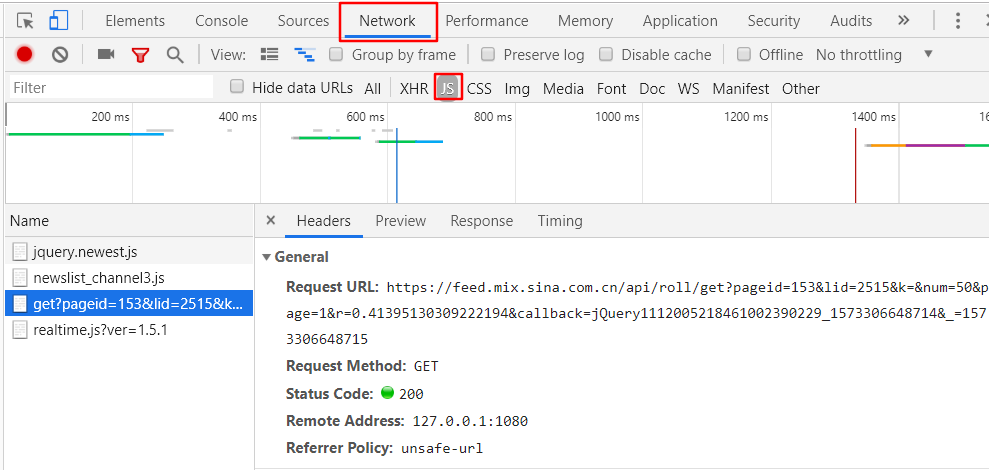
于是打开浏览器调试工具观察,重新刷新一下界面,可以看到这时浏览器发出了一个请求,请求的url中包含了一些页面的信息,比如页码,该页的新闻数:
点击Response,查看得到的响应如下,尤其注意图中的框出来的部分包含url,title等信息,其中 ‘\u’开头的字符串就基本表明是跟unicode编码相关的,猜测这些是新闻相关的信息: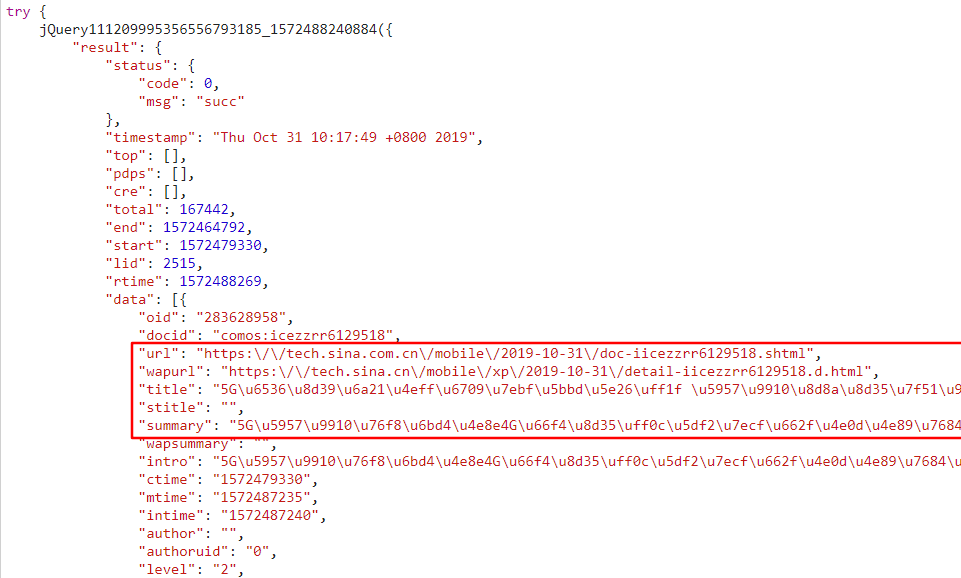
得到的响应比较长,这是结尾,这与后面解析这个json文件有关:
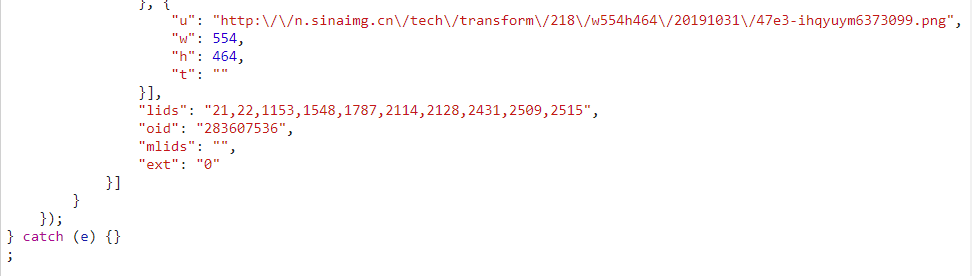
然后尝试打开其中一个url,发现的确就是一个新闻链接。于是使用python的json库对该响应进行解析,因为这个响应的头部和尾部是一些无关紧要的字符串,并且会影响json的解析,所以要将他们去掉:
reply = json.loads(r.text[46:-14])
得到解析结果后,输出一下长度:
print(len(reply['result']['data']))
发现正好是50!也就是之前截图的那个网页的新闻数,到此,可以确定新闻网址的确是这样得到的,我们就可以构造请求头去获取所需的新闻链接了。
观察上面发送请求头的url:
https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2515&k=&num=50&page=1&r=0.7908182387933844&callback=jQuery11120751503391487965_1572504701420&_=1572504701424
其中的pageid,lid都是与 "科技"这个主题相关的,不用改变,num = 50是指页面的新闻数,也不用变, page就是第几页,所以翻页时需要改变它,后面的r 以及 jQuery后面的的一串数字可能是与时间戳相关的信息或者随机数,测试后发现改不改得到的结果都是一样,所以不做修改。
所以我们就只需套层循环来改变 page 就可以构造目的url请求了。到此,就可以动手写代码了:
for page_num in range(1, 50):try:url = f'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2515&k=&num=50&page={str(page_num)}&r=0.5' \ f'&callback=jQuery111206769814687743869_1572427017317&_=1572427017314'kv = {'user-agent': 'Mozilla/5.0'}r = requests.get(url, headers=kv)# 解析 json文件reply = json.loads(r.text[46:-14])# print(len(reply['result']['data']))# 处理该页的50条新闻for i in range(0, 50):news_info = [reply['result']['data'][i]['title'], reply['result']['data'][i]['url']]succeed = get_one_news(news_info, news_num)# 成功保存才算数if succeed:news_num += 1news_title_url.append(news_info)if news_num > 1000:breakexcept:print('Something wrong! Ignore it and continue crawl...')continue
接下来就是对网页新闻内容进行提取,也就是上面的 get_one_news()函数的实现。
点开一个新闻链接,观察新闻网页源码可以看到:

新闻内容在 <div class="article" id="artibody" data-sudaclick="blk_content">标签中,利用soup.select('.article'),选出就可以找出原文内容了。
这里的用到了BeautifulSoup库中的select()函数,该函数可以用来查找经BeautifulSoup解析后的网页中的一些内容,比如某个标签,class,或者id,函数返回一个包含搜索结果的list. 该函数的一般用法有:
(1)直接通过标签名查找
print(soup.select('a'))
# [<a href="http://tech.sina.com.cn/" data-sudaclick="nav_tech_p">科技</a>...]
(2)通过类名查找, class名前加 .
print(soup.select('.footer'))
# [<div class="footer">...]
(3)通过 id 名查找,id名前加
print(soup.select('#search_type'))
# [<select id="search_type" name="c" style="visibility: hidden;">...]
(4)组合查找,即查找包含搜索的id,class,标签的组合的结果,关键字用逗号隔开如a标签中 class 为 ico-nav-gotop
print(soup.select('a .ico-nav-gotop'))
# [[<i class="ico-nav-gotop"></i>]]
(5)子标签查找
print(soup.select('tr > td'))
# [<td class="order">序号</td>, <td class="title">关键词</td>...]
(6)属性查找,中间不能加空格,否则匹配不到
print(soup.select('a[href="https://www.aizhan.com/"]'))
# [<a href="https://www.aizhan.com/"><img alt="爱站网" src=...]
通过上面的操作我们就得到了新闻内容了,有个别的网页在该标签的内部还放有其他内容,比如:

对于第一张图的情况,因为该网站的新闻数足够多,所以直接判断内容开头的几个字符是不是中文,不是就直接跳过这条新闻。
对于第二张图的情况,输出新闻内容字符串可以看到,每次新闻结尾都会有 8 个换行符,然后才会出现后面的内容,所以我们直接从该处截断即可。最后按顺序保存新闻标题及内容即可,考虑到爬取的内容是用于训练的,所以保存的都是500字以上的新闻。另外,这只是粗略的处理了一下文本内容,真正用前还需要再做预处理。这部分都在get_one_news()函数中实现,见下:
def get_one_news(news_infor, n):"""接受新闻标题和网址,以及已爬取的网页数,返回是否成功保存:param news_infor: list,[title, url]:return: 成功保存返回True,否则False"""news_url = news_infor[1]kv2 = {'user-agent': 'Mozilla/5.0'}r2 = requests.get(news_url, headers=kv2)r2.raise_for_status()r2.encoding = r2.apparent_encodingsoup = BeautifulSoup(r2.text, "html.parser")# 取出正文article = []for p in soup.select('.article'):article.append(p.text.strip().lstrip())# 合成字符串article_content = ''.join(article)# 去掉结尾的不需要的内容end = article_content.find('\n\n\n\n\n\n')article_content = article_content[:end]# 判断开头是否含有汉字,因为有可能存在style,这种就直接放弃has_chinese = Falsefor char in article_content[:10]:if '\u4e00' <= char <= '\u9fff':has_chinese = Truebreak# 保证新闻长于500字if has_chinese and len(article_content) > 500:print('[', n, '/ 1000 ] ', news_infor)# 保存新闻filename = str(n) + '.txt'cur_path = os.getcwd()file_path = cur_path + '\\' + filenamewith open(file_path, 'w', encoding='utf-8') as f:f.write(news_infor[0] + '\n')f.write(article_content)return Truereturn False
到此,新闻爬取就完成了,以下是运行结果:


有些新闻网站翻页需要点击 “加载更多” 来加载更多新闻,其实原理和上面也是一样的,在点击的同时会发送一个类似的请求,得到响应内容后,在加载到界面中。当然,像这种还可以用 selenium 库模拟点击动作完成,也比较简单灵活,但是使用该库还需要下载合适的浏览器驱动,而且相对来说速度较慢,尤其是爬取的网页比较多时就可能会比较耗时,具体还得根据实际情况来选择。