互联网 Web 就是一个巨大无比的数据库,但是这个数据库没有一个像 SQL 语言可以直接获取里面的数据,因为更多时候 Web 是供肉眼阅读和操作的。如果要让机器在 Web 取得数据,那往往就是我们所说的“爬虫”了。现在项目需要,所以研究研究,把大概的过程和“坑”记录下来,也欢迎大渣批评和补充。
爬虫的思路十分简单:
- 按照一定的规律发送 HTTP 请求获得页面 HTML 源码(必要时需要加上一定的 HTTP 头信息,比如 cookie 或 referer 之类)
- 利用正则匹配或第三方模块解析 HTML 代码,提取有效数据
- 将数据持久化到数据库中。
上述过程虽描述得简单,但在实际过程遇到的问题还是不少的,世界上不存在完美的、一致的、通用的抓取工具。为了不同的目的,需要定制不同的代码。下面我们逐一分析。
解析 HTML
简单抓取
最基本的发送 HTTP 请求获得 HTML 代码,使用 node 自带的 http.request 功能即可。如果是爬简单的内容,比如获得某个指定 id 元素中的内容(常见于抓去商品价格),那么正则足以完成任务。但是对于复杂的页面,尤其是数据项较多的页面,使用 DOM 会更加方便高效。
而 node.js 最好的 DOM 实现非 cheerio 莫属了。其实 cheerio 应该算是 jQuery 的一个针对 DOM 操作优化和精简的子集,包含了 DOM 操作的大部分内容,去除了其它不必要的内容。使用 cheerio 你就可以像用普通 jQuery 选择器那样选择你需要的内容。
cheerio 使用方法如下所示,首先引入 cheerio = require('cheerio')。
jsdom 也可以。
var jsdom = require("jsdom");jsdom.env({url: "http://v.youku.com/v_show/id_XMTQ3Mzc1MTczNg==.html?from=y1.6-85.3.1.14b31ff68f3311e5a080&x",
// ['http://static.youku.com/h5/player/embed/unifull/unifull_.js'],
// {userAgent:'Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25'
// },,done:function (err, window) {console.log(err);setTimeout(function(){console.log("there have been", window.document.body.innerHTML);}, 2000);}
});使用 request.js
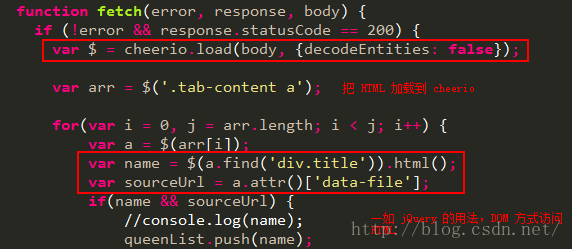
request.js 是对 http.request 更高级的封装。如果结合 cheerio 使用,是这样子的。
// 打开详情页
var request = require('request'), cheerio = require('cheerio');function loadInfo(url){request({url: url,headers: {'User-Agent': userAgent}}, function fetch(error, response, body) {if (!error && response.statusCode == 200) {var $ = cheerio.load(body, {decodeEntities: false});var video = $('video');console.log(video);} else {console.log('解析 HTML 错误或通讯故障。');}});
}详情参阅 request.js 文档以及教程。
JS 生成页面(通过 Phantom.js 抓取)
某些页面的内容显示是通过 JavaScript 动态调用显示的,所以就没法通过普通的获取页面 HTML 然后通过正则或者 XPath 的方式获取到想到的信息了。所幸我们现在有了 Phantom.js 的库,它是一个服务器端的没用界面的 webkit 浏览器。某种程度讲,因为 Phantom.js 内置了一个完整的 JS 运行时,所以这时候是无须要 cheerio 的帮助的。
首先,Phantom.js 不是 node 的库,是可以独立运行的程序——怎么让 Phantom.js 与 Node “联婚”呢?开源的方案搜索一下有不少,例如:
- https://github.com/SpookyJS/SpookyJS
- https://github.com/Medium/phantomjs
- https://github.com/alexscheelmeyer/node-phantom
- 貌似 Nightmare.js + Electron 也很强大
- https://github.com/amir20/phantomjs-node
发现只有 phantomjs-node 最近才在更新(最后的那個)。phantomjs-node 成功将 Phantom.js 作为 node 的一个模块来使用,其原理是通过 标准输出 sysin/sysout 来进行两者进程之通讯的(v2.x 改进),速度比较快。既然要依赖于 Phantom.js 那么就要下载 Phantom.js 并将 Phantom.js 配置进环境变量(PATH),命令行输入 phantomjs 如果有反应,那么就可以进行下一步了。
当前 Phantom.js 版本是 2.1,phantomjs-node 版本是 2.0.x。安装 phantomjs-node:
npm install phantom --save测试是否安装正确(phantomjs.exe 加入 PATH 环境变量)
var phantom = require('phantom');phantom.create().then(function(ph) {ph.createPage().then(function(page) {page.open('https://stackoverflow.com/').then(function(status) {console.log(status);page.property('content').then(function(content) {console.log(content);page.close();ph.exit();})})});
});下面重点谈谈 Phantom.js 的使用。
Phantom.js
按照上面的例子就可以把 HTML 打印出来(content 内容)。对于 page 打开的页面,往往需要与其进行一些交互,也就是 DOM 方式操控 HTML。page.evaluate() 提供了在page 打开页面的上下文的操作,因此 page.evaluate(function(){...}) 第一个函数是在页面操作的。比如 console.log("foo"),不是在我们 phantomjs 那个控制台里面输出那个文本,而是浏览器的。
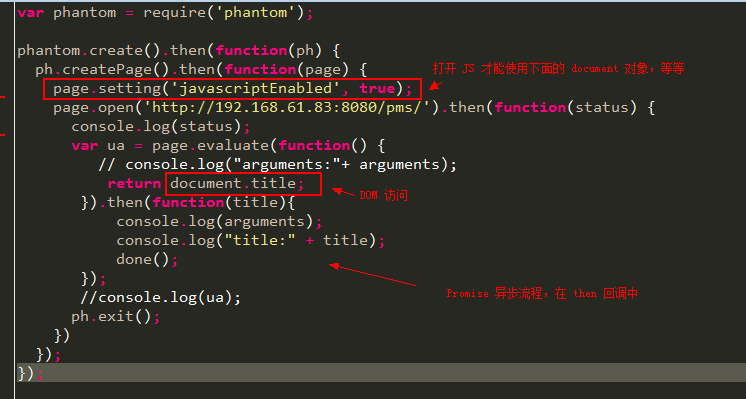
注意使用 page.evaluate() 的话一定先要将 JavaScript 激活!
phantomjs-node 提供的 API
phantom.createPage() 方法返回的 page 对象是 Phantom.js 的代理对象,一般情况下其所提供的方法与 Phantom.js 原生的一致。page 的方法为 Promise 异步调用方法,返回的总是一个 Promise 对象。
例如读取某个属性可以调用 page.property(),然后通过 Promise 的 then 异步返回,例如:
page.property('plainText').then(function(content) {console.log(content);
}); 设置属性方法如下,then 可以省略。But beware that the next method to phantom will block until it is ready to accept a new message.
page.property('viewportSize', {width: 800, height: 600}).then(function() {
}); 读取属性可以通过以下方法:
page.setting('javascriptEnabled').then(function(value){expect(value).toEqual(true);
}); 事件也用通过 property 设置,因为其实它是 page 的一个成员。
page.property('onResourceRequested', function(requestData, networkRequest) {console.log(requestData.url);
})