本文爬取的网站如下(可以找解密工具解码)
aHR0cHM6Ly9uZXdyYW5rLmNuLw==
爬取的内容为网站的资讯情报版块的新闻资讯

鼠标点击翻页,在开发者工具中查看请求包,很容看出请求地址和参数,
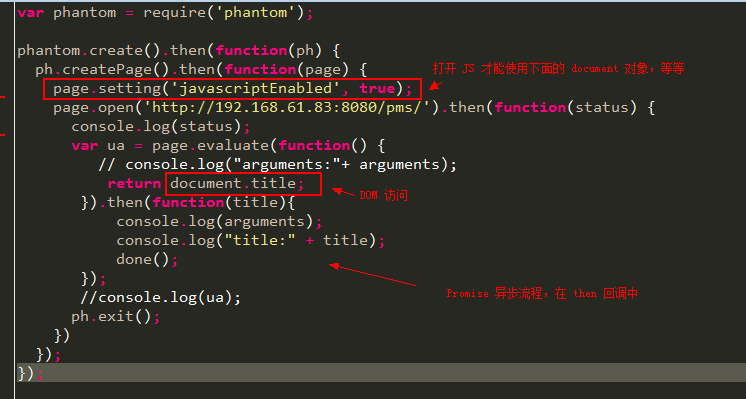
 其中post请求的参数如图:
其中post请求的参数如图:

其中变化的参数为nonce和xyz,我们的目标就是找出这两个参数的加密原理,就是加密函数。然后用python代码编写函数生成该加密参数,或者抠出JS代码,然后在python中调用生成加密参数,然后传入post请求,实现爬虫。
逆向过程:
1、搜索参数nonce,会有如下结果:

2、选择任一结果,选择美化代码,找到JS代码中该参数位置。

3、此时很容易看到两个参数的位置,打上断点。注意,nonce参数就是i,而上一行显示i就是j函数

4、在658行处也打上断点,点击调试。显示j函数的链接,点击进去,就找到了j函数的代买,也就是nonce参数的生成原理。


只要有一定java或者js或者C语言经验, 不难看出,这段代码就是随机生成一个由9个数字或字母组成的字符串。
此时我们可以在自己的编译器中(我用Vscode,记事本也可以)新建一个JS文件(如newrank.js),然后直接拷入上段JS代码,这样解决了第一个参数。(也可以自己用python直接写一个随机函数生成)

5、继续调试,寻找第二个参数xyz的加密原理。
xyz就是d函数,通过调试得知,d函数就是b函数,如下图。

我们点击进入b函数,结果如下

其实这个函数的作用就是把参数进行md5加密,仅此而已!!! 如果看不懂,也可以直接把JS代码抠出来,毕竟就是一个函数。抠的时候,千万要抠全了, 否则是无效的函数。亲手测试下就知道这个大坑了,尤其是新手。我们把这个函数的JS代码复制出来,加到上面新建的 JS文件里面,然后保存。
6、还要找到生成参数xyz的加密函数的参数。重复刚才的调试,可以看到,生成xyz的d函数的参数为h,而上一行显示参数h由'/xdnphb/index/getMedia?AppKey=joker&keyword=&pageNumber=页码&pageSize=10' 和字符串'&nonce='和nonce参数拼接而成。

至此,我们找到了参数生成函数,以及其参数的来源。
接下来我们只需要调用我们新建的js文件里的相应函数,生成加密参数,然后传入post请求,即可完成爬虫。
要注意调用js代码的方法,具体请见完整爬虫代码。
import requests
import pprint,time
import execjs
import hashlibheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64;` rv:47.0) Gecko/20100101 Firefox/47.0","referer": "https://www.newrank.cn/public/news.html?",}with open(r'D:\pythoncode\JS\newrank.js',encoding='utf-8') as f: #上面这个newrank.js文件就是我们新建的js文件,里面放入了从网站JS源码抠出的两个函数。js=f.read()ctx=execjs.compile(js)
for page in range(1,21): nonce=ctx.call('j') #调用JS代码中的函数生成第一个加密参数noncexyz=f'/xdnphb/index/getMedia?AppKey=joker&keyword=&pageNumber={page}&pageSize=10&nonce=' + noncexyz=ctx.call('b',xyz) #调用JS代码中的函数生成第二个加密参数xyz#xyz参数也可以直接用python的MD5加密实现# xyz=hashlib.md5(xyz.encode(encoding='utf-8')).hexdigest() data = {'keyword': '','pageNumber': str(page),'pageSize': '10','nonce': nonce,'xyz': xyz}# print(nonce, xyz)response = requests.post('https://www.newrank.cn/xdnphb/index/getMedia', headers=headers, data=data)print(response.status_code)# print(response.text)response_data=response.json()['value']# pprint.pprint(response_data)for item in response_data:print('资讯标题:',item['title'],'发布时间:',item['public_time'])看到如下的爬取结果如下,心里还是挺爽的。欢迎大家留言交流 !需要那个JS代码的也可以留言。