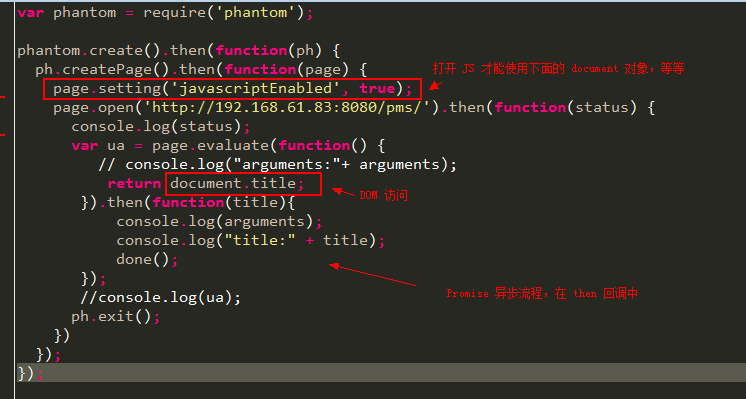
思考🤔
假设你正在为公司做市场调研,你需要获得一些能够提供关于你的目标受众的信息以进行研究,但是你发现这些信息并不能直接获取。你人工地搜索每个网站是不现实的,所以你需要一种更高效、更自动化、更快速的方式来获取这些信息。在这种情况下,我们应该如何高效的获取这些信息呢?
在如上思考中,我们需要解决的问题是:如何高效、自动化、快速的获取信息。那这个问题的答案就是:爬虫。
什么是爬虫?
爬虫是一种自动化程序,它模拟客户端行为,并访问网站以解析数据和获取有用信息。
它们通过模拟浏览器或访问API等方式,访问网站并解析页面,从而收集有关其内容的信息。
爬虫的分类
通用爬虫:能够访问互联网上的所有网站并自动收集数据,大多数情况下不包括互联网上的所有网站,速度相对较慢。
聚焦爬虫:只会在特定的域名集合内执行爬取操作,通常速度较快。
增量式爬虫:可以检查网站页面更新并定期抓取新数据,只抓取新数据或者更新的数据,然后将这些数据追加到原有数据的后面。
深度网页爬虫:可以访问动态网站,模拟用户在网站上进行交互的行为,例如使用一个按钮或者通过一个下拉列表等与网站进行交互,解析网站返回的数据。
这4类类型的爬虫大致上又可以分为两类,就是通用爬虫和聚集爬虫,其中聚焦网络爬虫,增量式网络爬虫和深层网络爬虫可以通俗地归纳为一类,因为这类爬虫都是定向爬取数据。
相比于通用爬虫,这类爬虫比较有目的性,也就是网络上经常说的网络爬虫,而通用爬虫在网络上通常称为搜索引擎。
爬虫的应用
-
搜索引擎:搜索引擎使用爬虫来扫描互联网上的网页,并建立索引,以便用户可以通过关键字搜索找到相关信息。
-
数据挖掘和分析:爬虫可以用于抓取大量的数据,并进行进一步的处理和分析,以获取有关市场趋势、用户行为、舆情分析等方面的见解。
-
价格比较和竞争情报:许多电子商务网站使用爬虫来抓取竞争对手的产品信息和价格,以便做出相应的调整和决策。
-
新闻聚合和摘要:爬虫可以帮助收集各种新闻网站的文章,并将它们聚合在一个平台上,使用户可以方便地浏览和获取最新的新闻摘要。
-
社交媒体分析:爬虫可以用于抓取社交媒体平台上的数据,例如推特或Instagram上的帖子和评论,以进行用户情感分析、话题趋势等。
-
学术研究:研究人员可以使用爬虫来获取学术论文、期刊文章和其他研究材料,以便进行文献综述和数据分析。
请注意,在进行爬虫时,应遵守法律和道德规范,尊重网站的隐私政策和使用条款。确保在爬取信息之前获取合适的许可,并尊重网站的访问频率限制,以避免给服务器造成过大的负担。
爬虫基本流程

从0-1实现爬取豆瓣电影 Top 250
0 我们看一下豆瓣电影首页的内容以及对应的dom结构,是一个列表,包含电影图片,电影名,简介等

1 初始化项目,并且添加 cheerio 和 axios 依赖
// 初始化项目
npm init -y
// 安装cheerio依赖,用于解析dom, axios 用于请求接口
npm i cheerio axios
2 使用 axios 请求接口,获取数据
// index.js
import axios from './axios.js'
// 请求网页,获取数据
axios.get('https://movie.douban.com/top250').then(res => {console.log(res)
}).catch(e => console.log('error=', e))
此时看res打印的是什么

这里可以看到 res 是一个对象,其中网页的dom内容存储在 data 中,我们可以对data进行解析,获取想要的数据
3 使用 cheerio 解析数据
import axios from './axios.js'
import * as cheerio from 'cheerio'axios.get('https://movie.douban.com/top250').then(res => {// 使用 cheerio 将页面内容解析为 dom 树const $ = cheerio.load(res.data)// 电影列表包含在一个类名为 article 的盒子里面,其中每一个电影包含在 类名为 item 的盒子里面// 因此,获取信息的逻辑如下:const items = Array.from($('.article .item'))items.forEach( item => {const title = $($($(item).find('.title'))[0]).text()const pic = $(item).find('.pic a').attr('href')const quote = $(item).find('.quote').text()?.trim()console.log({title, pic, quote})})
}).catch(e => console.log('error=', e))
至此,我们获取到了电影的 title, pic, quote

4 那我们如何把获取的数据保存在本地呢
import fs from 'fs'function saveFile(fileName, content) {try {fs.writeFileSync(fileName, JSON.stringify(content))} catch(error) {console.error(error)}
}export default saveFile
然后把我们刚刚爬取到的数据保存在本地
import axios from './axios.js'
import * as cheerio from 'cheerio'
import save from './save.js';axios.get('https://movie.douban.com/top250').then(res => {// 使用 cheerio 将页面内容解析为 dom 树const $ = cheerio.load(res.data)// 电影列表包含在一个类名为 article 的盒子里面,其中每一个电影包含在 类名为 item 的盒子里面// 因此,获取信息的逻辑如下:const items = Array.from($('.article .item'))const movies = items.map( item => {const title = $($($(item).find('.title'))[0]).text()const pic = $(item).find('.pic a').attr('href')const quote = $(item).find('.quote').text()?.trim()return {title, pic, quote}})// 保存数据save('movies.json', movies)
}).catch(e => console.log('error=', e))
保存的数据如下:

这样,一个小小的爬虫demo就写好了,当然还有很多功能没有写,如下载图片文件而不是地址,爬取更多详细信息,翻页爬取等,大家有兴趣可以自己研究~~
反爬机制
随着爬虫技术的日渐成熟,各大网站的反爬机制也是与时俱进,大家相互促进式成长。
知道常见的反爬机制,不仅有助于保护自己,也可以爬取他人网站(此处应有🐶
常见的反爬机制如下:
- 检查cookie、header等信息
- 接口携带token等信息
- 使用滑块、验证码等
- 需要登录
- 屏蔽高频调用接口的IP
- …
写在最后
通过本文我们了解到,爬虫技术在互联网时代的数据获取和信息分析中扮演着重要的角色。
不同类型的爬虫有不同的应用场景,但是我们也需要注意爬虫技术的合法性和道德性,遵守相关法律法规和道德规范,保护个人隐私和知识产权。
同时,随着爬虫技术的不断发展和应用场景的不断拓展,各大网站的反爬机制也在不断升级,我们需要了解和应对这些反爬机制。
总之,爬虫技术的合理应用可以为我们带来更多的便利和机遇,但是我们也需要在合法合规的前提下使用它。