一、node的文件系统
1、二进制文件的读写(按字节读写:一个字节是8个二进制位)
(1)读二进制文件
fs.read(fd,buffer,offset,length,position,callback)
fd:文件描述符。由open函数返回。
buffer:被写入数据的缓冲区。(用来缓存从文件中读取的数据)
offset:偏移量,描述的是写入缓冲区的位置信息。读取的数据要放在缓冲区的什么位置。一般从0开始。
length:表示从文件中读取的字节数。
position:表示从文件中读取数据的位置。若为null(0),表示从当前位置开始读。
callback:回调函数。参数:err、bytesRead、buffer
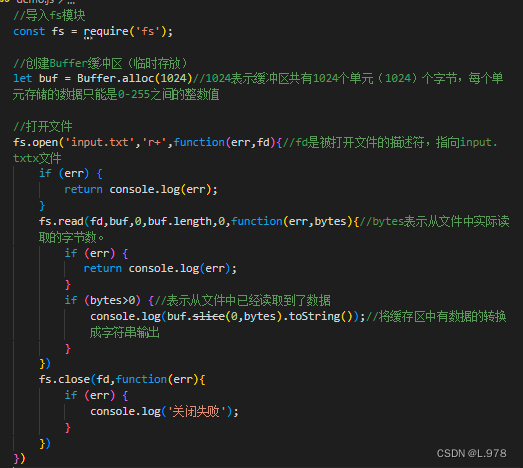
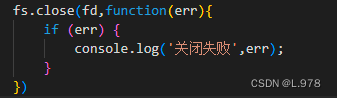
(2)关闭文件
fs.close(fd,callback)
fd:文件描述符
callback:回调函数。参数err。
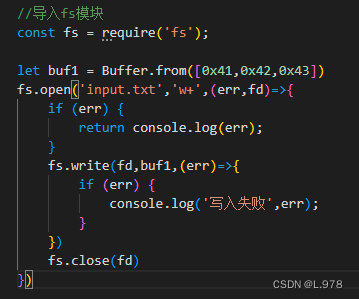
2、写二进制文件(向二进制文件写入内容)
fs.write(file,buffer,offset,length,position,callback) --- 将buffer中的数据写入到fd所描述的文件中去。
写入时若文件不存在则新建一个文件,若文件存在则覆盖原文件内容。
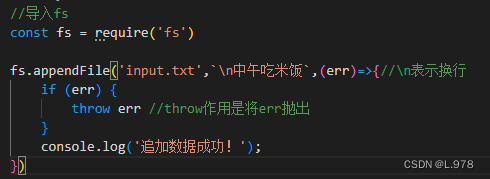
3、向文件中追加数据
(1)异步追加
fs.appendFile(path,data,options,callback)
path:文件全名(文件路径和文件名)
data:追加的数据
callback:回调函数,参数err
(2)同步追加
fs.appendFileSync(path,data,options,callback)
4、目录操作
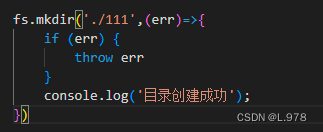
(1)创建目录
a、异步创建
fs.mkdir(path,model,callback)
path:目录名。(包含有路径)
model:可以设置计算机权限,可省略
callback:回调函数。
b、同步创建
fs.mkdirSync(path,model,callback)
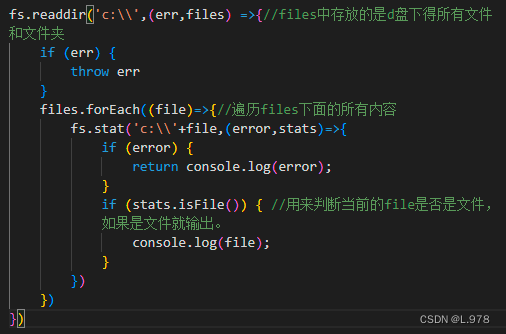
(2)读取目录
a、异步创建:
fs.readdir(path,callback)
path:目录名。(包含有路径)
callback:回调函数。参数err、files(files中存放的是读取目录中的文件和子目录信息,实质是一个集合)。
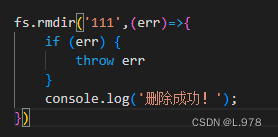
(3)删除目录
a、异步删除
fs.rmdir(path,callback)
path:目录名。(包含有路径)
callback:回调函数。
二、node的数据流(Stream接口)
1、系统处理缓存的方式
(1)传统方式:先将数据全部读入缓存(内存),然后再进行处理。
优点:符合人的思维方式,流程比较流畅
缺点:对于数据量很大的文件,处理的效率低下。
(2)数据流方式 :读一块处理一块,将待处理的数据分割成一块一块的,像流水一样,每当有新的数据块进入内存时会触发一个事件,程序就从内存中获取新数据进行处理。
优点:程序对数据的处理速度快,效率高。
2、node总的数据流
(1)Readable:用于读操作的数据流。
(2)Writeable:用于写操作的数据流
(3)Duplex:用于读写操作的数据流。
(4)Transform:输出基于输入的地方进行计算的一种双相流。
3、node中使用数据流时触发的事件:每个数据流都有一个EventEmitter实例,该实例的作用是触发事件。
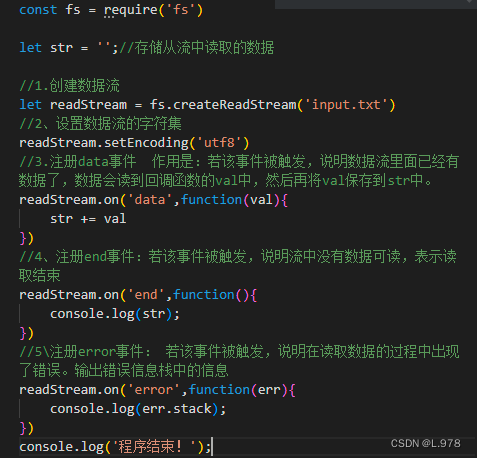
(1)data:当流中有数据可以读取时触发此事件。data是事件名
(2)end:当流中没有数据时事件被触发。end是事件名
(3)error:当有任何错误时触发。error是事件名
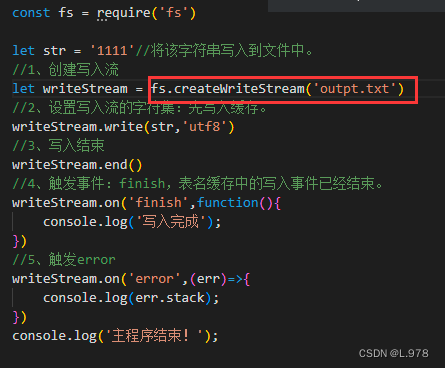
(4)finish:当所有数据已刷新到底层系统时触发此事件。finish是事件
4、从流中读取数据:fs模块的createReadStream方法的作用是创建一个读取数据的数据流。
fs.createReadStream(文件全名)
5、向流中写入数据:fs模块的createWriteStream方法可以创建一个写数据流
fs.createWriteStream(文件全名)
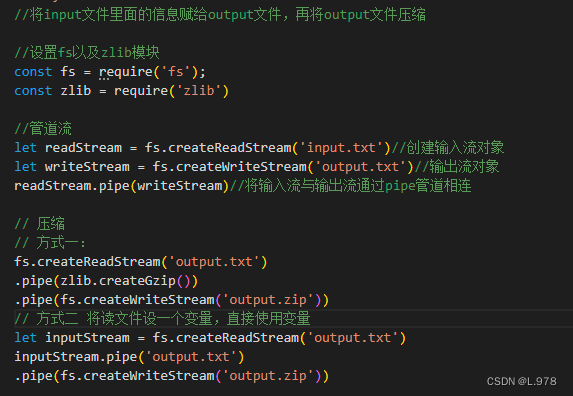
6、管道流:用于从一个流中获取数据,并通过该流输出到另一个流。
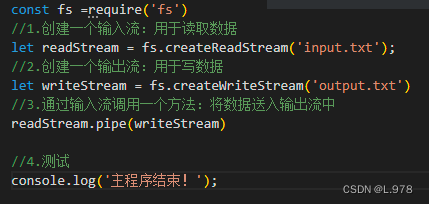
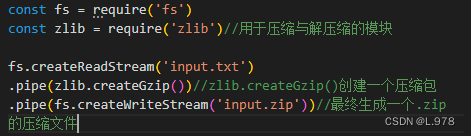
7、链式流:是一种机制,一个流的输出连接到另一个流,并创建一个链多流操作。
(1)压缩文件
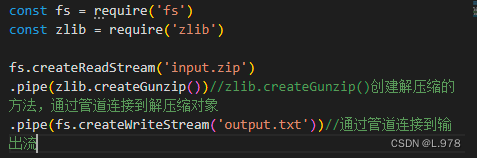
(2)解压缩
练习: