文章目录
- 一. 介绍
- 二. 公式
- 三. 代码细节
- 四. 代码
一. 介绍
node2vec是一种综合考虑DFS邻域和BFS邻域的graph embedding方法。简单来说,可以看作是deepwalk的一种扩展,是结合了DFS和BFS随机游走的deepwalk。node2vec通过调整方向的参数来控制模型更倾向BFS还是DFS。

BFS更能体现图网络的“结构性”,因为BFS生成的序列往往是由当前节点周边的组成的网络结构。这就能让最终生成的embedding具备更多局部结构化特征。
DFS更能体现图网络的“同质性”,因为DFS更有可能游走到当前节点远方的节点。但无论怎样,DFS的游走更大概率会在一个大的集合内部进行,这就使得一个集合内部节点的embedding更为相似,从而更多地表达网络的“同质性”
二. 公式



三. 代码细节
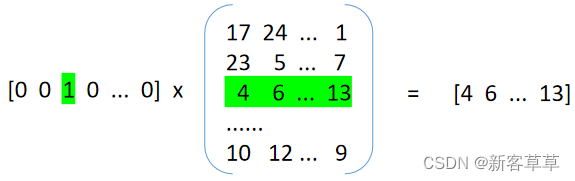
采样完顶点序列后,剩下的步骤就和deepwalk一样了,用word2vec去学习顶点的embedding向量。值得注意的是node2vecWalk中不再是随机抽取邻接点,而是按概率抽取,node2vec采用了Alias算法进行顶点采样。
关于Alias算法的一些参考:
- https://mp.weixin.qq.com/s/n_EveU9G_MRwuSHW5kyWkw
- https://zhuanlan.zhihu.com/p/54867139
- https://blog.csdn.net/haolexiao/article/details/65157026
四. 代码
import networkx as nx
from gensim.models import Word2Vec
import pandas as pd
import numpy as np
import itertools
import math
import random
from joblib import Parallel, delayed
from tqdm import trangeimport warningswarnings.filterwarnings('ignore')
G = nx.read_edgelist('./data/wiki/Wiki_edgelist.txt',create_using=nx.DiGraph(), nodetype=None, data=[('weight', int)])
#Alias采样
def create_alias_table(area_ratio):""":param area_ratio: sum(area_ratio)=1:return: accept,alias"""l = len(area_ratio)accept, alias = [0] * l, [0] * lsmall, large = [], []area_ratio_ = np.array(area_ratio) * lfor i, prob in enumerate(area_ratio_):if prob < 1.0:small.append(i)else:large.append(i)while small and large:small_idx, large_idx = small.pop(), large.pop()accept[small_idx] = area_ratio_[small_idx]alias[small_idx] = large_idxarea_ratio_[large_idx] = area_ratio_[large_idx] - \(1 - area_ratio_[small_idx])if area_ratio_[large_idx] < 1.0:small.append(large_idx)else:large.append(large_idx)while large:large_idx = large.pop()accept[large_idx] = 1while small:small_idx = small.pop()accept[small_idx] = 1return accept, aliasdef alias_sample(accept, alias):""":param accept::param alias::return: sample index"""N = len(accept)i = int(np.random.random()*N)r = np.random.random()if r < accept[i]:return ielse:return alias[i]
def partition_num(num, workers):if num % workers == 0:return [num//workers]*workerselse:return [num//workers]*workers + [num % workers]class RandomWalker:def __init__(self, G, p=1, q=1, use_rejection_sampling=0):""":param G::param p: Return parameter,controls the likelihood of immediately revisiting a node in the walk.:param q: In-out parameter,allows the search to differentiate between “inward” and “outward” nodes:param use_rejection_sampling: Whether to use the rejection sampling strategy in node2vec."""self.G = Gself.p = pself.q = qself.use_rejection_sampling = use_rejection_samplingdef deepwalk_walk(self, walk_length, start_node):walk = [start_node]while len(walk) < walk_length:cur = walk[-1]cur_nbrs = list(self.G.neighbors(cur))if len(cur_nbrs) > 0:walk.append(random.choice(cur_nbrs))else:breakreturn walkdef node2vec_walk(self, walk_length, start_node):G = self.Galias_nodes = self.alias_nodesalias_edges = self.alias_edgeswalk = [start_node]while len(walk) < walk_length:cur = walk[-1]cur_nbrs = list(G.neighbors(cur))if len(cur_nbrs) > 0:if len(walk) == 1:walk.append(cur_nbrs[alias_sample(alias_nodes[cur][0], alias_nodes[cur][1])])else:prev = walk[-2]edge = (prev, cur)next_node = cur_nbrs[alias_sample(alias_edges[edge][0],alias_edges[edge][1])]walk.append(next_node)else:breakreturn walkdef node2vec_walk2(self, walk_length, start_node):"""Reference:KnightKing: A Fast Distributed Graph Random Walk Enginehttp://madsys.cs.tsinghua.edu.cn/publications/SOSP19-yang.pdf"""def rejection_sample(inv_p, inv_q, nbrs_num):upper_bound = max(1.0, max(inv_p, inv_q))lower_bound = min(1.0, min(inv_p, inv_q))shatter = 0second_upper_bound = max(1.0, inv_q)if (inv_p > second_upper_bound):shatter = second_upper_bound / nbrs_numupper_bound = second_upper_bound + shatterreturn upper_bound, lower_bound, shatterG = self.Galias_nodes = self.alias_nodesinv_p = 1.0 / self.pinv_q = 1.0 / self.qwalk = [start_node]while len(walk) < walk_length:cur = walk[-1]cur_nbrs = list(G.neighbors(cur))if len(cur_nbrs) > 0:if len(walk) == 1:walk.append(cur_nbrs[alias_sample(alias_nodes[cur][0], alias_nodes[cur][1])])else:upper_bound, lower_bound, shatter = rejection_sample(inv_p, inv_q, len(cur_nbrs))prev = walk[-2]prev_nbrs = set(G.neighbors(prev))while True:prob = random.random() * upper_boundif (prob + shatter >= upper_bound):next_node = prevbreaknext_node = cur_nbrs[alias_sample(alias_nodes[cur][0], alias_nodes[cur][1])]if (prob < lower_bound):breakif (prob < inv_p and next_node == prev):break_prob = 1.0 if next_node in prev_nbrs else inv_qif (prob < _prob):breakwalk.append(next_node)else:breakreturn walkdef simulate_walks(self, num_walks, walk_length, workers=1, verbose=0):G = self.Gnodes = list(G.nodes())results = Parallel(n_jobs=workers, verbose=verbose, )(delayed(self._simulate_walks)(nodes, num, walk_length) for num inpartition_num(num_walks, workers))walks = list(itertools.chain(*results))return walksdef _simulate_walks(self, nodes, num_walks, walk_length,):walks = []for _ in range(num_walks):random.shuffle(nodes)for v in nodes:if self.use_rejection_sampling:walks.append(self.node2vec_walk2(walk_length=walk_length, start_node=v))else:walks.append(self.node2vec_walk(walk_length=walk_length, start_node=v))return walksdef get_alias_edge(self, t, v):"""compute unnormalized transition probability between nodes v and its neighbors give the previous visited node t.:param t::param v::return:"""G = self.Gp = self.pq = self.qunnormalized_probs = []for x in G.neighbors(v):weight = G[v][x].get('weight', 1.0) # w_vxif x == t: # d_tx == 0unnormalized_probs.append(weight/p)elif G.has_edge(x, t): # d_tx == 1unnormalized_probs.append(weight)else: # d_tx > 1unnormalized_probs.append(weight/q)norm_const = sum(unnormalized_probs)normalized_probs = [float(u_prob)/norm_const for u_prob in unnormalized_probs]return create_alias_table(normalized_probs)def preprocess_transition_probs(self):"""Preprocessing of transition probabilities for guiding the random walks."""G = self.Galias_nodes = {}for node in G.nodes():unnormalized_probs = [G[node][nbr].get('weight', 1.0)for nbr in G.neighbors(node)]norm_const = sum(unnormalized_probs)normalized_probs = [float(u_prob)/norm_const for u_prob in unnormalized_probs]alias_nodes[node] = create_alias_table(normalized_probs)if not self.use_rejection_sampling:alias_edges = {}for edge in G.edges():alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])if not G.is_directed():alias_edges[(edge[1], edge[0])] = self.get_alias_edge(edge[1], edge[0])self.alias_edges = alias_edgesself.alias_nodes = alias_nodesreturn
num_walks = 80 #序列数量
walk_length = 10 #序列长度
workers = 4#根据RandomWalker产生序列
rw = RandomWalker(G, p=0.25, q=4, use_rejection_sampling=0)
rw.preprocess_transition_probs()
sentences = rw.simulate_walks(num_walks=num_walks, walk_length=walk_length, workers=workers, verbose=1)model = Word2Vec(sentences = sentences,vector_size = 128,min_count=5,sg =1,hs=0,workers = workers,window=5, epochs=3)#获取embedding dict
embedding_dict = {}
for word in G.nodes(): embedding_dict[word] = model.wv[word]
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 2 out of 4 | elapsed: 3.1s remaining: 3.1s
[Parallel(n_jobs=4)]: Done 4 out of 4 | elapsed: 4.3s finished
#计算两个embedding之间的余弦相似度
def cosine_similarity(x,y):num = x.dot(y.T)denom = np.linalg.norm(x) * np.linalg.norm(y)return num / denomresult = cosine_similarity(embedding_dict['1397'],embedding_dict['1470'])
result
0.80252045