1. 安装
pip install node2vec2. 使用案例
import networkx as nx
from node2vec import Node2Vec# Create a graph 这里可以给出自己的graph
graph = nx.fast_gnp_random_graph(n=100, p=0.5)# Precompute probabilities and generate walks - **ON WINDOWS ONLY WORKS WITH workers=1**
node2vec = Node2Vec(graph, dimensions=64, walk_length=30, num_walks=200, workers=4) # Use temp_folder for big graphs# Embed nodes
model = node2vec.fit(window=10, min_count=1, batch_words=4) # Any keywords acceptable by gensim.Word2Vec can be passed, `diemnsions` and `workers` are automatically passed (from the Node2Vec constructor)# Look for most similar nodes
model.wv.most_similar('2') # Output node names are always strings# Save embeddings for later use
model.wv.save_word2vec_format(EMBEDDING_FILENAME)# Save model for later use
model.save(EMBEDDING_MODEL_FILENAME)# Embed edges using Hadamard method
from node2vec.edges import HadamardEmbedderedges_embs = HadamardEmbedder(keyed_vectors=model.wv)# Look for embeddings on the fly - here we pass normal tuples
edges_embs[('1', '2')]
''' OUTPUT
array([ 5.75068220e-03, -1.10937878e-02, 3.76693785e-01, 2.69105062e-02,... ... ......................................................................],dtype=float32)
'''# Get all edges in a separate KeyedVectors instance - use with caution could be huge for big networks
edges_kv = edges_embs.as_keyed_vectors()# Look for most similar edges - this time tuples must be sorted and as str
edges_kv.most_similar(str(('1', '2')))# Save embeddings for later use
edges_kv.save_word2vec_format(EDGES_EMBEDDING_FILENAME)3. 重要源码文件参数说明
这里主要介绍 node2vec 文件。
node2vec.Node2Vec 总体流程:

(a) node2vec 构造函数: 初始化 node2vec 对象,预先计算 walk 概率 并 生成 walks。
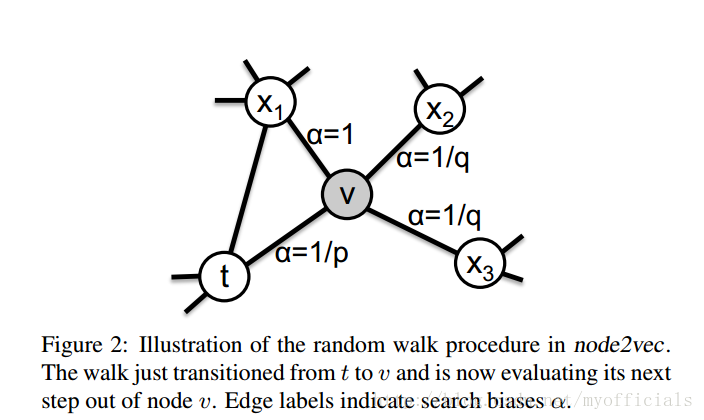
def __init__(self, graph, dimensions=128, walk_length=80, num_walks=10, p=1, q=1, weight_key='weight', workers=1, sampling_strategy=None, quiet=False, temp_folder=None):self.graph = graphself.dimensions = dimensionsself.walk_length = walk_lengthself.num_walks = num_walksself.p = pself.q = qself.weight_key = weight_keyself.workers = workersself.quiet = quietself.d_graph = defaultdict(dict)if sampling_strategy is None:self.sampling_strategy = {}else:self.sampling_strategy = sampling_strategyself.temp_folder, self.require = None, Noneif temp_folder:if not os.path.isdir(temp_folder):raise NotADirectoryError("temp_folder does not exist or is not a directory. ({})".format(temp_folder))self.temp_folder = temp_folderself.require = "sharedmem"self._precompute_probabilities()self.walks = self._generate_walks()graph: 第1个位置的参数必须是 networkx 图。节点名必须都是整数或都是字符串。在输出模型上,它们始终是字符串。dimensions: 嵌入维度(默认值:128)walk_length: 每个路径的节点数(默认值:80)num_walks: 经过每个节点的次数(默认值:10)p: 返回超参数(默认值:1)# p 和 q 是决定采用DFS或者BFS的关键参数q: 输入输出参数(默认值:1)weight_key: 在加权图上,这是 权重属性的关键字(默认值:“weight”)。workers: 并行执行的工作者数目(默认值:1)sampling_strategy: 特定节点的采样策略, 支持设置节点特定的“q”、“p”、“num_walks”和“walk_length” 参数。请准确地使用这些关键字。如果未设置,将默认为对象初始化时传递的全局参数。quiet: 控制布尔值长度。(默认值:false)temp_folder: 指向文件夹的字符串路径,用于保存图形的共享内存副本 - 在算法执行过程中处理过大而无法放入内存的图时提供。
(b) Node2Vec.precompute_probabilities 函数:预先计算每个节点的转换概率。
(c) Node2Vec.generate_walks 函数:生成随机路径,将用作 skip-gram 的输入。
1. return:路径列表。每个路径都是一个节点列表。
(d) Node2Vec.fit函数: 使用 gensim 的 word2vec 创建嵌入对象。(因为node2vec 是基于 word2vec 的)
1. 参数 skip_gram_params: gensim.models.word2vec 的参数 - 不提供 “size”,它取自 node2vec 的 “dimensions” 参数
2. skip_gram_params 的类型: dict
3. return: 一个 gensim word2vec 模型
def fit(self, **skip_gram_params):if 'workers' not in skip_gram_params:skip_gram_params['workers'] = self.workersif 'size' not in skip_gram_params:skip_gram_params['size'] = self.dimensionsreturn gensim.models.Word2Vec(self.walks, **skip_gram_params)