决策树
- 数据集
- 实战
- 可视化
- 评价
决策树是什么?决策树(decision tree)是一种基本的分类与回归方法。举个通俗易懂的例子,流程图就是一种决策树。
有没有车,没车的话有没有房,没房的话有没有存款,没存款pass。这个流程就是一个简单的决策树。
分类决策树模型是一种描述对实例进行分类的树形结构。通过很多次判断来决定是否符合某类的特征。
数据集
首先附上数据集:
链接:https://pan.baidu.com/s/1bFDGa7E6lnuHOQpb1KCDSQ
提取码:exxv
#load the data
import pandas as pd
import numpy as np
data = pd.read_csv('./iris_data.csv')
data.head()
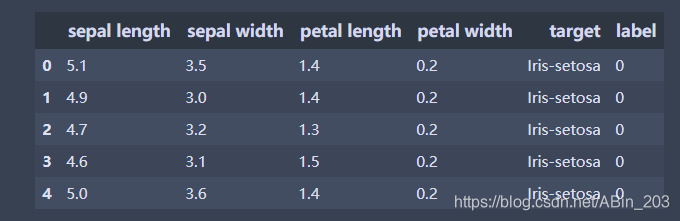
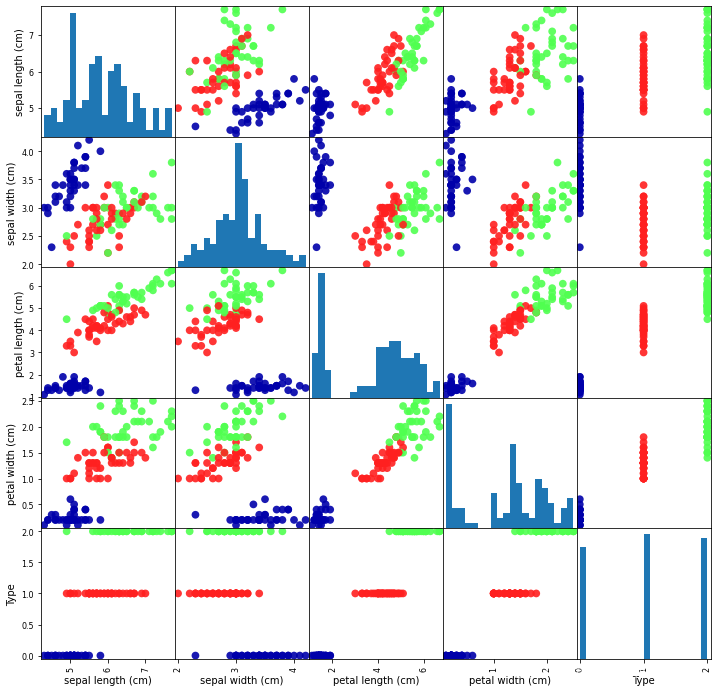
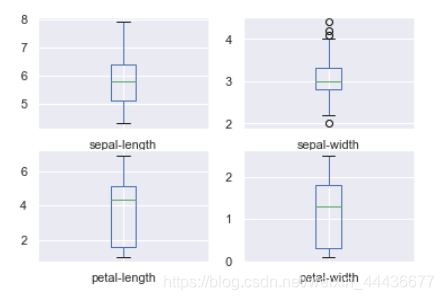
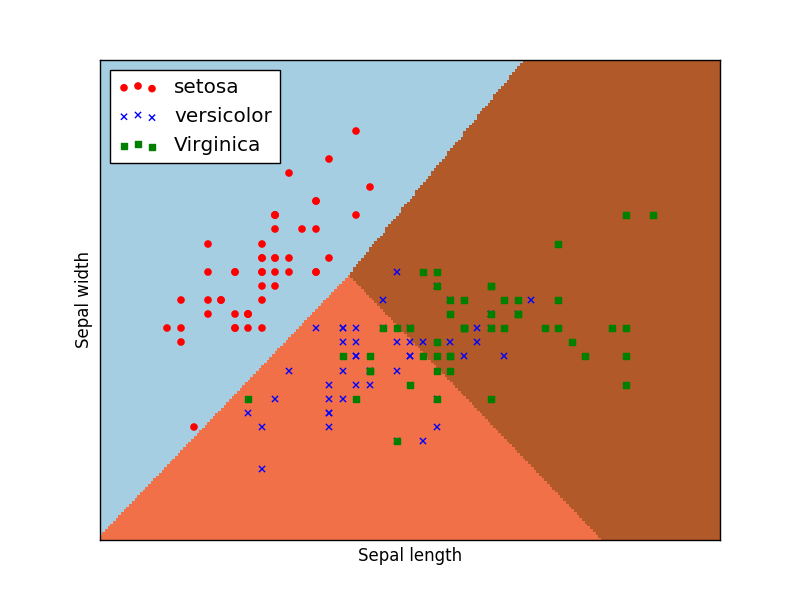
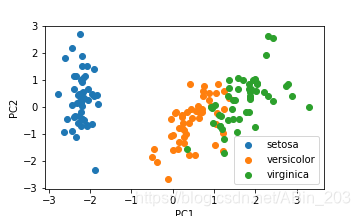
数据集有3类花,每种花有4个特征。把4个特征投影到二维平面可以很清楚看出。setosa与其余两种鸢尾花有明显的边界,而versicolor和virginica这两种花具有相似的特征,看起来有些重叠。
如果是人为判断的话,我们可以这样想,setosa与其余两种花区别最大的特征就作为第一个分叉。
如果满足那么全是setosa,不满足则是其余2种,则再进行判断。
那么决策树会不会和我们想的一样呢?
实战
X = data.drop(['target','label'],axis=1)
y = data.loc[:,'label']
print(X.shape,y.shape)
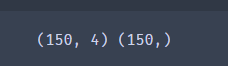
150个样本,每个样本有4个维度的特征。
接下来就是构建决策树模型了。
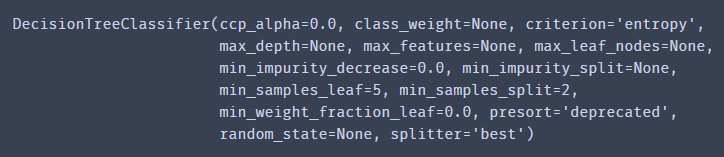
from sklearn import tree
dc_tree = tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
dc_tree.fit(X,y)
在可以评测哪个数据划分方式是最好的数据划分之前,集合信息的度量方式称为香农熵或者简称为熵(entropy),常见的计算信息熵有3种,ID3,C4.5,CART。
而大多数情况都是用ID3算法,它的核心是在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。具体方法是:从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树。ID3相当于用极大似然法进行概率模型的选择。
本文criterion='entropy’也就是采用ID3。
min_samples_leaf:叶子节点最少样本数,可选参数,默认是1。这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。叶结点需要最少的样本数,也就是最后到叶结点,需要多少个样本才能算一个叶结点。如果设置为1,哪怕这个类别只有1个样本,决策树也会构建出来。如果min_samples_leaf是整数,那么min_samples_leaf作为最小的样本数。如果是浮点数,那么min_samples_leaf就是一个百分比,同上,celi(min_samples_leaf * n_samples),数是向上取整的。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
这里我们先选择5试试。
y_predict = dc_tree.predict(X)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
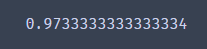
print(accuracy)
导入评判正确率的函数,预测和真实值进行比较得出正确率97%,还是很不错的。
可视化
让读者去空想决策树结构还是比较麻烦的。为了易于理解和解释。决策树可以可视化。
feature_names=[‘花萼长’, ‘花萼宽’, ‘花瓣长’, ‘花瓣宽’],这就是一些特征。
class_names=[‘山鸢尾’, ‘变色鸢尾’, ‘维吉尼亚鸢尾’],这些是标签。
import matplotlib as mpl
font2 = {'family' : 'SimHei',
'weight' : 'normal',
'size' : 20,
}
mpl.rcParams['font.family'] = 'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
%matplotlib inline
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(20,20))
tree.plot_tree(dc_tree,filled='True',feature_names=['花萼长', '花萼宽', '花瓣长', '花瓣宽'],class_names=['山鸢尾', '变色鸢尾', '维吉尼亚鸢尾'])
plt.savefig('D:/桌面/1.png', bbox_inches='tight', pad_inches=0.0)
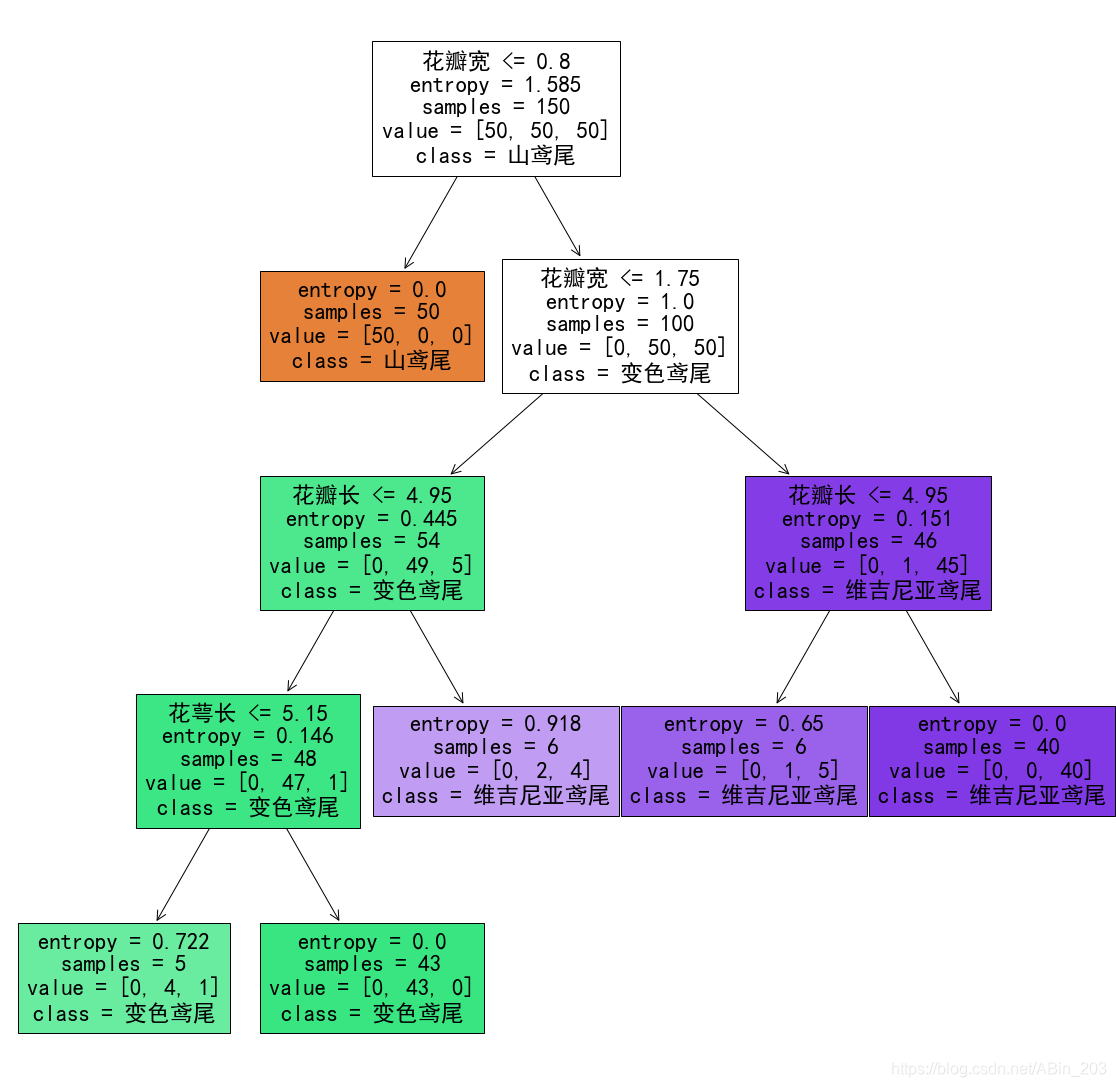
这是前文设置min_samples_leaf=5时候的决策树结构。
实际上min_samples_leaf有点的控制树的深度的意思,但是不是简单的值为多少深度就是多少。它是通过样本数来控制深度。如果再分下去的某个分支样本数小于5那么它就不会再分了。
如果想要直接控制深度的话,这里还有个参数是max_depth,这个参数值是多少那么决策树的深度就是多少了。
可以清晰看到决策树是怎么分类的。和前文博主构想的一样,鸢尾花数据集里面有一种花的特征与其余两种有很大区别,直接可以分类出。那这里就是如果花瓣宽小于等于0.8,那么就是山鸢尾花,而且注意到分类出来的山鸢尾花sample为50,说明根据这个特征分类出来山鸢尾花直接全部分类正确。其余的就再进行其他特征的判断,一层一层特征判断。
为了给读者展示min_samples_leaf如何控制决策树,博主这里令值为10再进行可视化看看。
dc_tree = tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=10)
dc_tree.fit(X,y)
fig = plt.figure(figsize=(8,8))
tree.plot_tree(dc_tree,filled='True',feature_names=['花萼长', '花萼宽', '花瓣长', '花瓣宽'],class_names=['山鸢尾', '变色鸢尾', '维吉尼亚鸢尾'])
plt.savefig('D:/桌面/2.png', bbox_inches='tight', pad_inches=0.0)
可以看到最后的sample样本数都是大于等于10的,它不会继续往下分,深度才5。而上面min_samples_leaf=5时候最后的sample是大于等于5的,深度为6。

评价
优点:
- 易于理解和解释。决策树可以可视化。
- 几乎不需要数据预处理。其他方法经常需要数据标准化,创建虚拟变量和删除缺失值。
- 可以处理多值输出变量问题。
- 预测正确率达到了97%,准确率高。
缺点:
- 参数比较多,不同的参数对于决策树的结构影响较大,从而结果也会有些偏差。
- 决策树学习可能创建一个过于复杂的树,并不能很好的预测数据。也就是过拟合。