写在前面
在写这篇文章之前,首先安利下jupyter,简直是神作,既可以用来写文章,又可以用来写代码,文章和代码并存,简直就是写代码/文章/教程的利器。
安装很简单:pip install jupyter
使用很简单: 当前面目录下shift+右键呼出在此处打开命令窗口,输入jupyter notebook召唤神龙。
上面这段文字在jupyter中是这样的(markdown格式):
本文介绍
基于iris数据集进行数据分析。
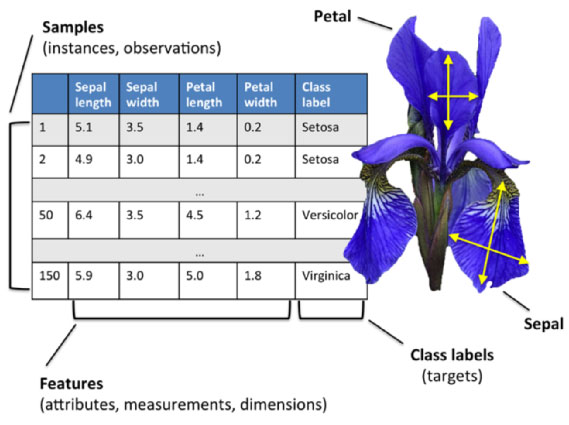
iris数据集是常用的分类实验数据集,由Fisher,1936收集整理。iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。(来自百度百科)
数据预处理
首先使用padas相关的库进行数据读取,处理和预分析。
pandas的可视化user guide参见:
https://pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html
首先读取信息,并查看数据的基本信息:可以看到数据的字段,数量,数据类型和大小。
%matplotlib notebookimport pandas as pdimport matplotlib.pyplot as plt# 读取数据iris = pd.read_csv('iris.data.csv')
iris.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
Sepal.Length 150 non-null float64
Sepal.Width 150 non-null float64
Petal.Length 150 non-null float64
Petal.Width 150 non-null float64
type 150 non-null object
dtypes: float64(4), object(1)
memory usage: 5.9+ KB # 前5个数据iris.head()
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | type | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
# 数据描述iris.describe()
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | |
|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 |
| mean | 5.843333 | 3.054000 | 3.758667 | 1.198667 |
| std | 0.828066 | 0.433594 | 1.764420 | 0.763161 |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 |
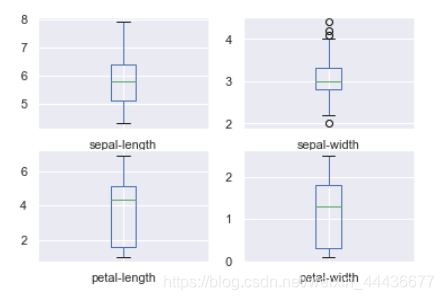
箱线图描述了数据的分布情况,包括:上下界,上下四分位数和中位数,可以简单的查看数据的分布情况。
比如:上下四分位数相隔较远的话,一般可以很容易分为2类。
在《深入浅出统计分析》一书中,一个平均年龄17岁的游泳班,可能是父母带着婴儿的早教班,这种情况在箱线图上就能够清楚的反映出来。
# 箱线图iris.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
Sepal.Length AxesSubplot(0.125,0.536818;0.352273x0.343182)
Sepal.Width AxesSubplot(0.547727,0.536818;0.352273x0.343182)
Petal.Length AxesSubplot(0.125,0.125;0.352273x0.343182)
Petal.Width AxesSubplot(0.547727,0.125;0.352273x0.343182)
dtype: object #直方图,反馈的是数据的频度,一般常见的是高斯分布(正态分布)。iris.hist()
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x000000001418E7B8>,<matplotlib.axes._subplots.AxesSubplot object at 0x00000000141C3208>],[<matplotlib.axes._subplots.AxesSubplot object at 0x00000000141EB470>,<matplotlib.axes._subplots.AxesSubplot object at 0x00000000142146D8>]],dtype=object) ![]()
# plot直接展示数据的分布情况,kde核密度估计对比直方图来看iris.plot()
iris.plot(kind = 'kde')
<matplotlib.axes._subplots.AxesSubplot at 0x14395518>径向可视化是多维数据降维的可视化方法,不管是数据分析还是机器学习,降维是最基础的方法之一,通过降维,可以有效的减少复杂度。
径向坐标可视化是基于弹簧张力最小化算法。
它把数据集的特征映射成二维目标空间单位圆中的一个点,点的位置由系在点上的特征决定。把实例投入圆的中心,特征会朝圆中此实例位置(实例对应的归一化数值)“拉”实例。
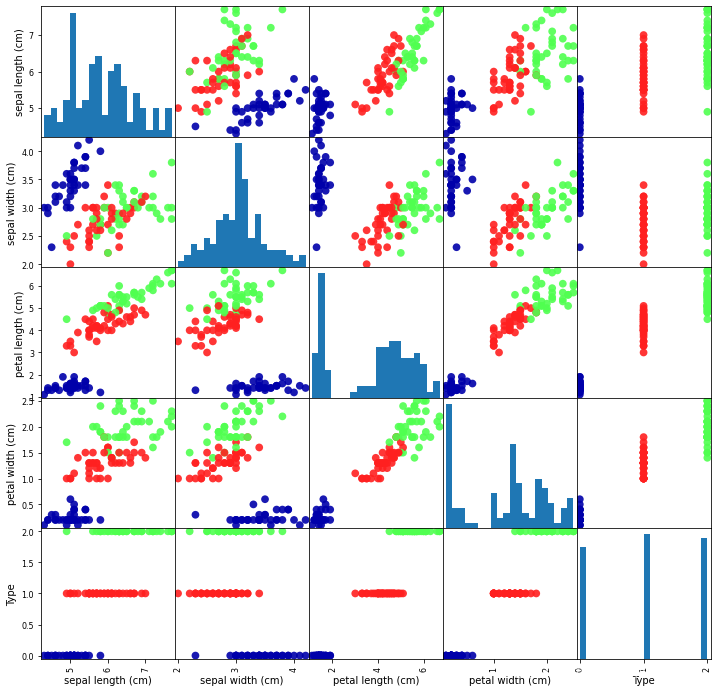
ax = pd.plotting.radviz(iris, 'type', colormap = 'brg')# radviz的源码中Circle未设置edgecolor,画圆需要自己处理ax.add_artist(plt.Circle((0,0), 1, color='r', fill = False))
<matplotlib.patches.Circle at 0x1e68ba58> # Andrews曲线将每个样本的属性值转化为傅里叶序列的系数来创建曲线。# 通过将每一类曲线标成不同颜色可以可视化聚类数据,# 属于相同类别的样本的曲线通常更加接近并构成了更大的结构。pd.plotting.andrews_curves(iris, 'type', colormap='brg')
<matplotlib.axes._subplots.AxesSubplot at 0x1e68b978> # 平行坐标可以看到数据中的类别以及从视觉上估计其他的统计量。# 使用平行坐标时,每个点用线段联接,每个垂直的线代表一个属性,# 一组联接的线段表示一个数据点。可能是一类的数据点会更加接近。pd.plotting.parallel_coordinates(iris, 'type', colormap = 'brg')
<matplotlib.axes._subplots.AxesSubplot at 0x1e931160> # scatter matrixcolors = {'Iris-setosa': 'blue', 'Iris-versicolor': 'green', 'Iris-virginica': 'red'}
pd.plotting.scatter_matrix(iris, color = [colors[type] for type in iris['type']])
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EB1B6A0>,<matplotlib.axes._subplots.AxesSubplot object at 0x0000000014349860>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001C67D550>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001434D198>],[<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EB3C6A0>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EB6BC18>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EB9C198>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EBC3748>],[<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EBC3780>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EE0C240>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EE357B8>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EE5CD30>],[<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EE8E2E8>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EEB4860>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EEDCDD8>,<matplotlib.axes._subplots.AxesSubplot object at 0x000000001EF0D390>]],dtype=object) # 相关系数的热力图import seaborn as sea
sea.heatmap(iris.corr(), annot=True, cmap='GnBu', linewidths=1, linecolor='k',square=True)
<matplotlib.axes._subplots.AxesSubplot at 0x1f56ce10> # pandas_profiling这个库可以对数据集进行初步预览,并进行报告,很不错,安装方式 pip install pandas_profiling# 运行略# import pandas_profiling as pp# pp.ProfileReport(iris)
# 数据分类import sklearn as skfrom sklearn import preprocessingfrom sklearn import model_selection
# 预处理X = iris[['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']]y = iris['type']encoder = preprocessing.LabelEncoder()y = encoder.fit_transform(y)
print(y)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 22 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 22 2] from sklearn import metricsdef model_fit_show(model, model_name, X, y, test_size = 0.3, cluster = False):
train_X, test_X, train_y, test_y = model_selection.train_test_split(X, y, test_size = 0.3)
print(train_X.shape, test_X.shape, train_y.shape, test_y.shape)
model.fit(train_X, train_y)
prediction = model.predict(test_X)
print(prediction) if not cluster:
print('accuracy of {} is: {}'.format(model_name, metrics.accuracy_score(prediction, test_y)))
pre = model.predict([[4.7, 3.2, 1.3, 0.2]])
print(pre)
L1 = X['Petal.Length'].values
L2 = X['Petal.Width'].values
cc = 50*['r'] + 50*['g'] + 50*['b']
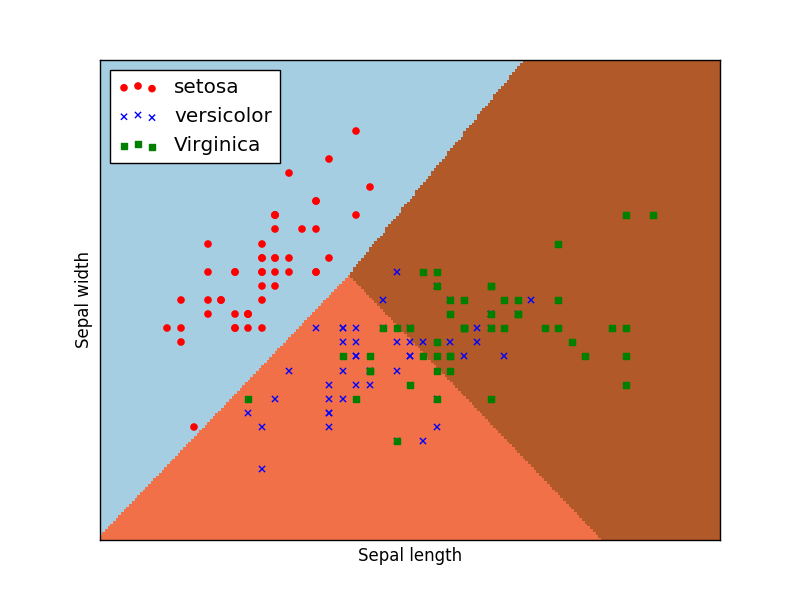
plt.scatter(L1, L2, c = cc, marker = '.')
L1 = test_X['Petal.Length'].values
L2 = test_X['Petal.Width'].values
MAP = {0:'r', 1:'g', 2:'b', 3:'y', 4:'k', 5:'w', 6:'m', 7:'c'}
cc = [MAP[_] for _ in prediction]
plt.scatter(L1, L2, c = cc, marker = 's' if cluster else 'x')
plt.show()
# logisticfrom sklearn import linear_model
model_fit_show(linear_model.LogisticRegression(), 'LogisticRegression', X, y)
(105, 4) (45, 4) (105,) (45,)
[1 2 2 0 2 0 2 1 0 1 2 1 0 0 0 2 2 1 2 0 2 0 1 2 2 1 0 1 2 1 2 1 0 2 0 1 01 0 0 1 2 2 0 0]
accuracy of LogisticRegression is: 0.9111111111111111
[0] # treefrom sklearn import tree
model_fit_show(tree.DecisionTreeClassifier(), 'DecisionTreeClassifier', X, y)
(105, 4) (45, 4) (105,) (45,)
[2 0 1 0 0 0 1 2 0 0 1 0 2 0 2 1 1 0 2 0 2 0 0 1 1 2 0 2 0 1 2 1 1 1 1 2 11 2 1 1 2 2 2 0]
accuracy of DecisionTreeClassifier is: 0.9111111111111111
[0] #SVMfrom sklearn import svm
model_fit_show(svm.SVC(), 'svm.svc', X, y)
(105, 4) (45, 4) (105,) (45,)
[2 0 0 2 0 1 0 2 1 2 2 0 1 1 0 1 1 2 1 0 2 2 2 1 0 2 2 1 1 1 0 1 0 0 2 0 02 0 0 1 2 1 0 0]
accuracy of svm.svc is: 0.9111111111111111
[0]
py:193: FutureWarning: The default value of gamma will change from 'auto' to 'scale' in version 0.22 to account better for unscaled features. Set gamma explicitly to 'auto' or 'scale' to avoid this warning."avoid this warning.", FutureWarning)![]()
# KNNfrom sklearn import neighbors
model_fit_show(neighbors.KNeighborsClassifier(), 'neighbors.KNeighborsClassifier', X, y)
(105, 4) (45, 4) (105,) (45,)
[1 2 2 2 0 0 0 1 2 2 1 2 1 1 1 2 0 2 0 0 1 1 0 0 1 0 2 2 0 0 2 2 1 1 0 1 10 1 1 2 1 1 0 0]
accuracy of neighbors.KNeighborsClassifier is: 0.9555555555555556
[0] # Kmeanfrom sklearn import cluster
model_fit_show(cluster.KMeans(n_clusters = 3), 'cluster.KMeans', X, y, cluster = True)
(105, 4) (45, 4) (105,) (45,)
[1 2 1 2 2 2 2 2 0 2 2 0 0 2 0 2 0 2 2 1 0 2 1 0 2 2 0 2 0 1 2 2 0 0 2 0 11 1 2 0 1 2 1 0]
[2]![]()
# naive bayes# https://scikit-learn.org/dev/modules/classes.html#module-sklearn.naive_bayes# 分别是GaussianNB,MultinomialNB和BernoulliNB。# GaussianNB:先验为高斯分布的朴素贝叶斯,一般应用于连续值# MultinomialNB:先验为多项式分布的朴素贝叶斯,离散多元值分类# BernoulliNB:先验为伯努利分布的朴素贝叶斯,离散二值分类# ComplementNB:对MultinomialNB的补充,适用于非平衡数据from sklearn import naive_bayes
model_fit_show(naive_bayes.BernoulliNB(), 'naive_bayes.BernoulliNB', X, y)
model_fit_show(naive_bayes.GaussianNB(), 'naive_bayes.GaussianNB', X, y)
model_fit_show(naive_bayes.MultinomialNB(), 'naive_bayes.MultinomialNB', X, y)
model_fit_show(naive_bayes.ComplementNB(), 'naive_bayes.ComplementNB', X, y)
(105, 4) (45, 4) (105,) (45,)
[2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 22 2 2 2 2 2 2 2]
accuracy of naive_bayes.BernoulliNB is: 0.24444444444444444
[2](105, 4) (45, 4) (105,) (45,)
[1 0 1 0 0 1 0 0 0 0 0 0 1 1 1 2 1 0 1 1 2 0 0 2 2 1 2 0 0 1 0 2 0 1 0 2 12 2 2 0 2 0 2 2]
accuracy of naive_bayes.GaussianNB is: 0.9333333333333333
[0](105, 4) (45, 4) (105,) (45,)
[0 2 2 1 2 1 2 0 2 1 2 0 2 0 1 1 2 1 0 2 2 2 0 1 1 1 0 2 2 1 1 2 1 0 0 1 00 1 1 2 2 1 2 1]
accuracy of naive_bayes.MultinomialNB is: 0.9555555555555556
[0](105, 4) (45, 4) (105,) (45,)
[2 2 2 2 2 2 2 2 2 2 2 0 2 2 2 0 2 2 2 2 0 0 0 2 2 2 0 0 2 2 2 0 2 2 2 0 02 0 2 2 2 2 0 2]
accuracy of naive_bayes.ComplementNB is: 0.6
[0]