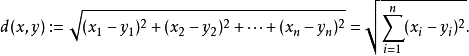鸢尾花数据集的数据显示
- 一、鸢尾花数据集介绍
- 1.历史
- 2.数据集
- 二、鸢尾花数据集可视化
- 1.普通读取数据方法
- 2.运行结果
- 3.普通读取数据方法
- 4.运行结果
- 5.未使用mglearn库的代码
- 6.运行结果
- 7.使用mglearn库的代码
- 8.运行结果
一、鸢尾花数据集介绍
1.历史
安德森鸢尾花卉数据集(英文:Anderson’s Iris data set),也称鸢尾花卉数据集(英文:Iris flower data set)或费雪鸢尾花卉数据集(英文:Fisher’s Iris data set),是一类多重变量分析的数据集。最初是埃德加·安德森从加拿大加斯帕半岛上的鸢尾属花朵中提取的地理变异数据。它首次出现在著名的英国统计学家和生物学家Ronald Fisher 1936年的论文《The use of multiple measurements in taxonomic problems》中,被用来介绍线性判别式分析。
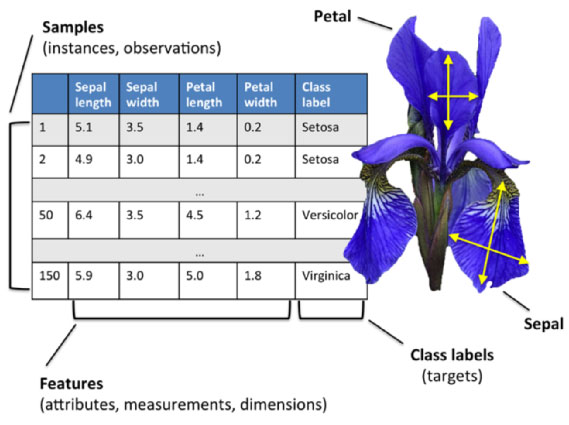
其数据集包含了150个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾、变色鸢尾和维吉尼亚鸢尾(Iris Setosa,Iris Versicolour,Iris Virginica)。四个特征被用作样本的定量分析,它们分别是花萼和花瓣的长度和宽度。基于这四个特征的集合,费雪发展了一个线性判别分析以确定其属种。
该数据集测量了所有150个样本的4个特征,分别是:sepal length(花萼长度)、sepal width(花萼宽度)、petal length(花瓣长度)、(花瓣宽度)。以上四个特征的单位都是厘米(cm)。
2.数据集
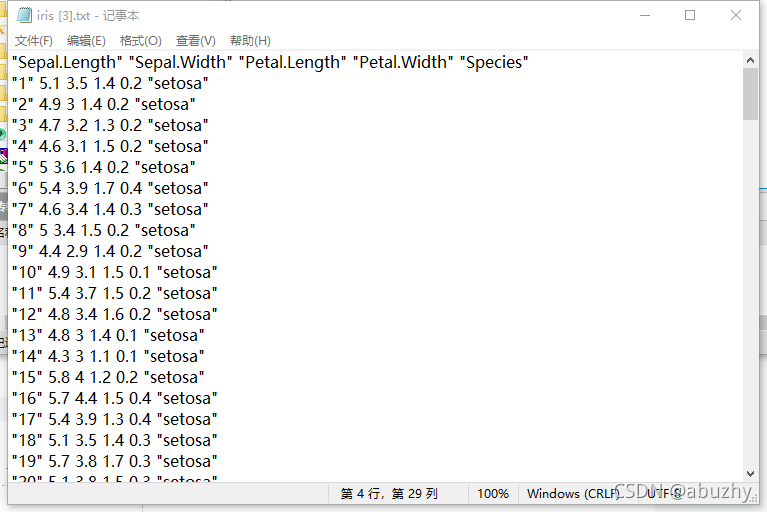
用记事本打开的iris.data文件如下图所示:
iris.data文件中的数据分别是“花萼长度,花萼宽度,花瓣长度,花瓣宽度,品种”,如下表(每种仅显示部分数据)所示。
| 花萼长度 | 花萼宽度 | 花瓣长度 | 花瓣宽度 | 品种 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 7.0 | 3.2 | 4.7 | 1.4 | Iris-versicolor |
| 6.4 | 3.2 | 4.5 | 1.5 | Iris-versicolor |
| 6.9 | 3.1 | 4.9 | 1.5 | Iris-versicolor |
| 5.5 | 2.3 | 4.0 | 1.3 | Iris-versicolor |
| 6.5 | 2.8 | 4.6 | 1.5 | Iris-versicolor |
| 6.3 | 3.3 | 6.0 | 2.5 | Iris-virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | Iris-virginica |
| 7.1 | 3.0 | 5.9 | 2.1 | Iris-virginica |
| 6.3 | 2.9 | 5.6 | 1.8 | Iris-virginica |
| 6.5 | 3.0 | 5.8 | 2.2 | Iris-virginica |
二、鸢尾花数据集可视化
1.普通读取数据方法
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mp
from sklearn.datasets import load_iris
#在图中显示中文
mp.rcParams['font.sans-serif'] = [u'SimHei']
mp.rcParams['axes.unicode_minus'] = Falseiris = load_iris()
##取150个样本,取前两列特征,花萼长度和宽度
x=iris.data[0:150,1:3] #能看特征数据的具体信息
y=iris.target[0:150] #能看每行数据的标签的值
##分别取前两类样本,0和1
samples_0 = x[y==0, :]#把y=0,即Iris-setosa的样本取出来
samples_1 = x[y==1, :]#把y=1,即Iris-versicolo的样本取出来
samples_2 = x[y==2, :]#把y=2,即Iris-virginica的样本取出来
#散点图可视化
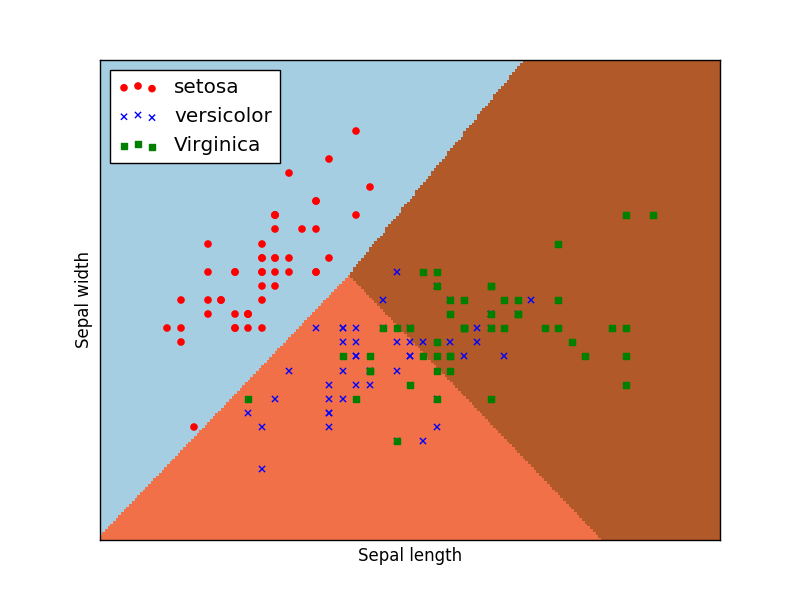
plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r')
plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='b')
plt.scatter(samples_2[:,0],samples_2[:,1],marker='*',color='y')
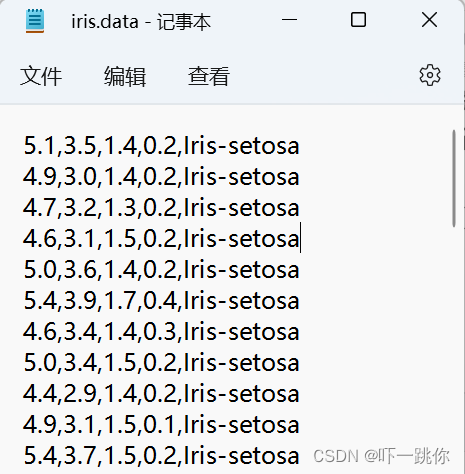
plt.xlabel('花萼宽度', fontsize=14)
plt.ylabel('花瓣长度',fontsize=14)
2.运行结果
3.普通读取数据方法
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mp
from sklearn.datasets import load_irisplt.style.use('seaborn-ticks')
mp.rcParams['font.sans-serif'] = [u'SimHei']
mp.rcParams['axes.unicode_minus'] = Falseiris = load_iris()
##取150个样本,取2,3两列特征,花萼宽度和花瓣长度
x=iris.data[0:150,1:3] #能看特征数据的具体信息
y=iris.target[0:150] #能看每行数据的标签的值
##分别取前两类样本,0和1
samples_0 = x[y==0, :]#把y=0的样本取出来
samples_1 = x[y==1, :]
samples_2 = x[y==2, :]
#散点图可视化
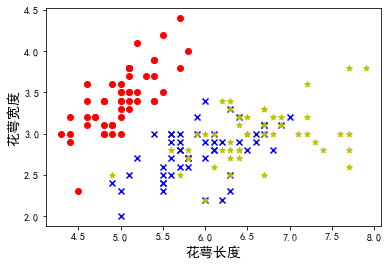
plt.scatter(samples_0[:,0],samples_0[:,1],marker='o',color='r',label='Iris Setosa')
plt.scatter(samples_1[:,0],samples_1[:,1],marker='x',color='b',label='Iris Versicolour')
plt.scatter(samples_2[:,0],samples_2[:,1],marker='*',color='y',label='Iris Virginica]')
plt.xlabel('花萼宽度', fontsize=14)
plt.ylabel('花瓣长度',fontsize=14)
plt.savefig('Iris Data Set.png', dpi=300)
plt.legend()
plt.show()
4.运行结果
5.未使用mglearn库的代码
代码如下(示例):
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitiris=load_iris()
#print(iris)
X_train,X_test,y_train,y_test = train_test_split(iris['data'],iris['target'],random_state=0)
print(y_train)
#分割训练集和测试集
#X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
#参数解释:
#train_data:所要划分的样本特征集,长度数据
#train_target:所要划分的样本结果,就是标签,鸢尾花的名字代号
#test_size:样本占比,如果是整数的话就是样本的数量
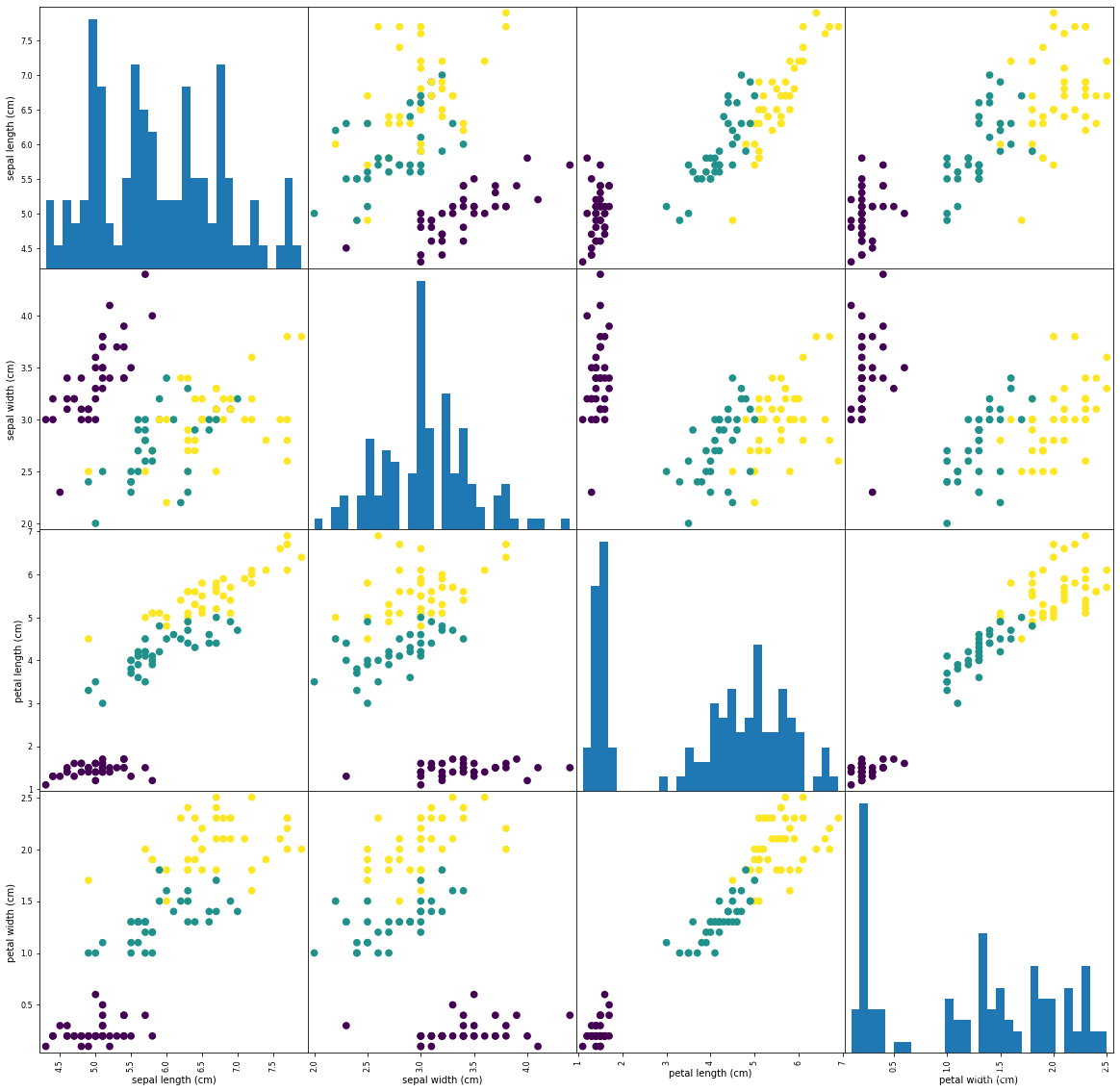
#random_state:是随机数的种子。iris_dataframe = pd.DataFrame(X_train,columns=iris.feature_names)
print(iris_dataframe)
#iris.feature_names 列名字 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
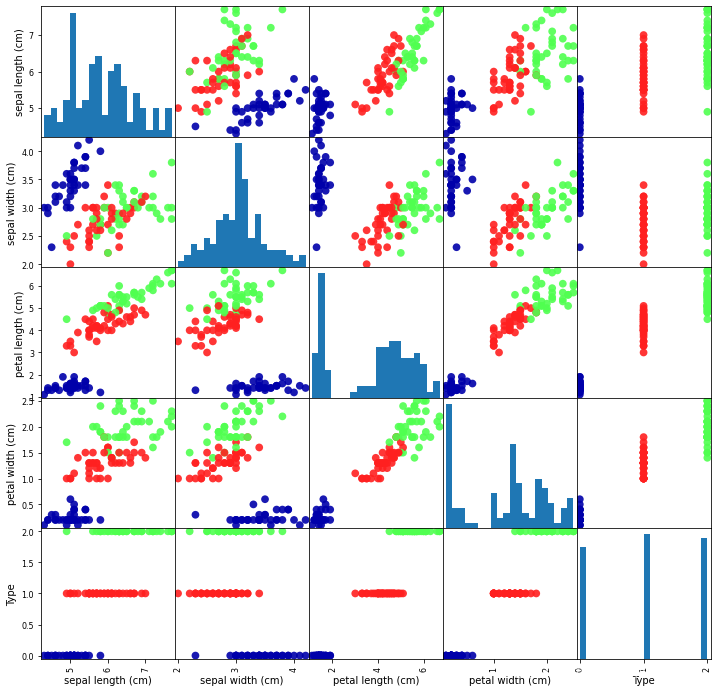
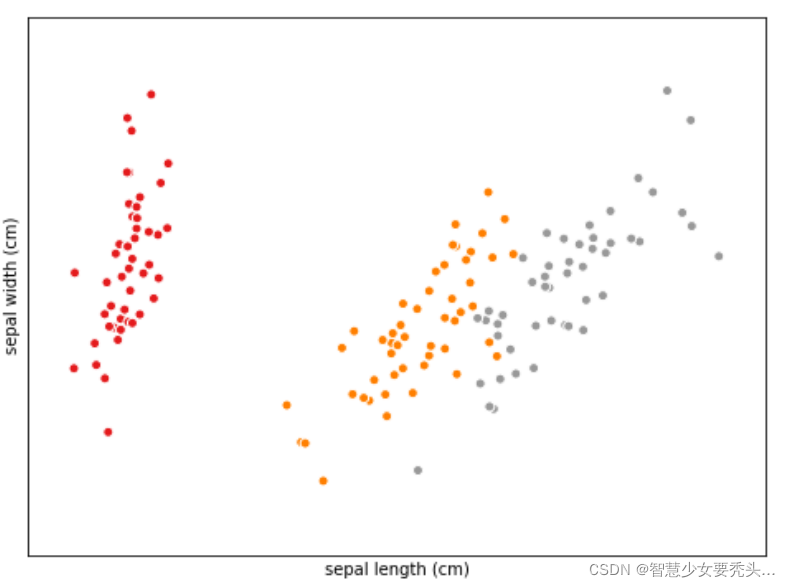
grr = pd.plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(20,20),marker='o',hist_kwds={'bins':30},s=60,alpha=1)
plt.show()
6.运行结果
7.使用mglearn库的代码
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
#使用了mglearn库
import mglearniris=load_iris()
#print(iris)
X_train,X_test,y_train,y_test = train_test_split(iris['data'],iris['target'],random_state=0)
print(y_train)
iris_dataframe = pd.DataFrame(X_train,columns=iris.feature_names)
print(iris_dataframe)
grr = pd.plotting.scatter_matrix(iris_dataframe,marker='o',c = y_train,hist_kwds={'bins':20},cmap=mglearn.cm3)
#使用了mglearn库的cm3数据视图的配色
plt.show()
8.运行结果