目录
- 鸢尾花数据集
- 下载鸢尾花数据集iris
-
- csv文件
- 下载数据集
- Pandas访问csv数据集
-
- Pandas库
- Pandas二维数据基本操作
-
- 读取csv数据集文件
- 设置列标题
- names参数
- 访问数据
- 显示统计信息
- DataFrame的常用属性:ndim、size、shape
- 转化为NumPy数组
-
- 访问数组元素–索引和切片
- 鸢尾花数据集可视化
-
- 鸢尾花数据散点图
- 色彩映射
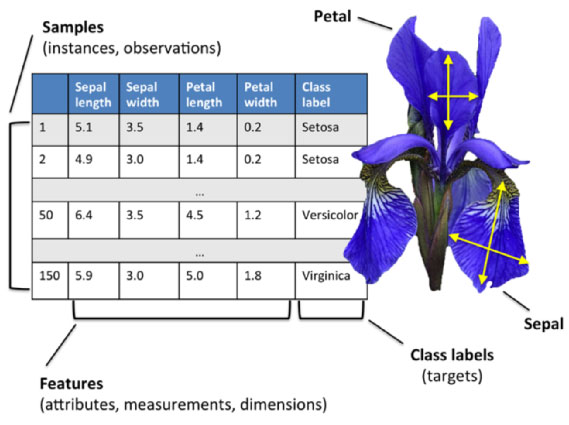
鸢尾花数据集
鸢尾花数据集是在加拿大的加斯帕半岛,在同一时间的同一个时段,在相同的牧场上由同一个人使用相同的测量仪器测量出来的。
包括三种鸢尾花类别,每个类别有50个样本,每个样本中包括4种鸢尾花的属性特征,和鸢尾花的品种。

这4种属性特征分别是花萼的长度和宽度,花瓣的长度和宽度,花萼是花的最外面一层的叶片。
这是鸢尾花数据集中的一部分数据。

可以看到前4列分别对应4种属性特征,最后一列是鸢尾花的品种,也就是数据的标签,这个数据集中包含的三个品种分别是山鸢尾,变色鸢尾和维基尼亚鸢尾。
鸳尾花数据集不是tensorflow和keras中集成了内置数据集,因此在使用之前,首先需要下载这些数据集。
在tensorflow中,要从指定的网络地址下载数据集,可以使用keras.utils模块中自带的下载函数get_file()。
tk.keras.utils.get_file(fname, origin, cache_dir)
其中参数
fname是下载后的文件名origin表示文件的url地址cache_dir表示下载后文件所存储的位置,这是windows系统中下载后的默认保存路径。
c:\Users\Administrator\.keras\datasets
这个函数的返回值是下载后的文件在本地磁盘中的绝对路径。
在执行这个函数时,首先会检查要下载的文件,fname是否存在,如果不存在则会根据origin参数提供的url地址下载文件,并把它命名为fname,存储在指定目录下,并返回文件地址。如果文件已经存在,则不再下载文件,直接返回文件地址。
下载鸢尾花数据集iris
我们使用get_file()函数来下载数据集
鸢尾花数据集划分为训练数据集和测试数据集,分别放在不同的两个文件中,文件名是iris_training.csv和iris_test.cvs。其中,训练数据集中有12条数据,测试数据集有30条数据。
这里我们只下载训练数据集。
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file("iris_train.csv", TRAIN_URL)
第一次执行这段代码时,会下载数据集。

这个数据集很小,所以下载的速度非常快。执行这段代码后,就可以在下载路径中找到这个数据及文件了。
csv文件
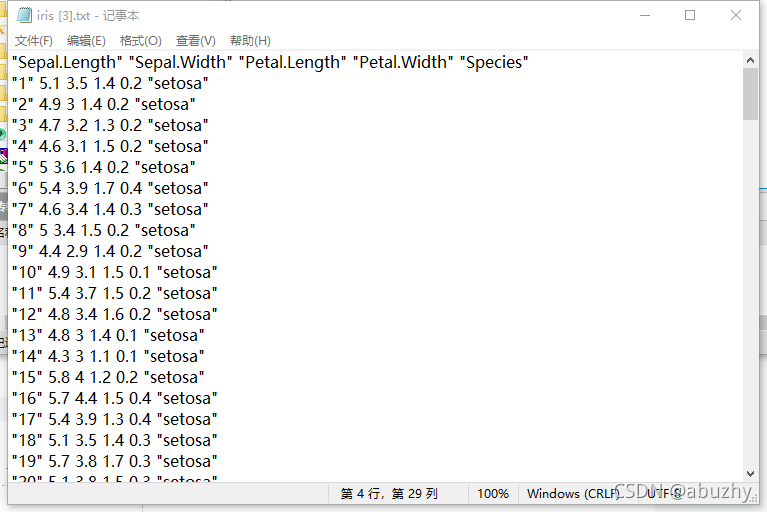
Csv文件是一种字符分割的文件,以纯文本形式存储表格。可以使用记事本打开,也可以使用Excel打开。
下面使用Excel打开这个文件
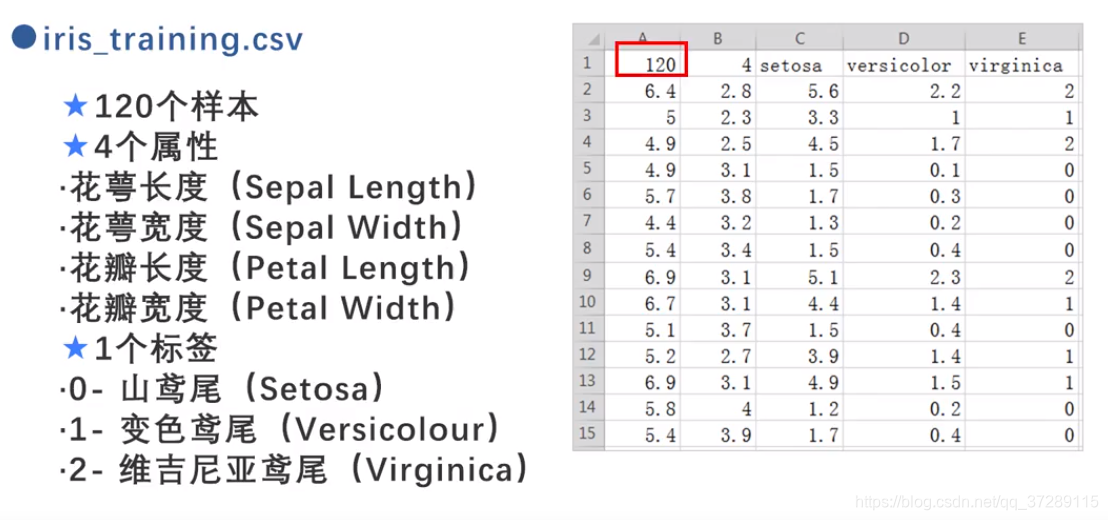
第1行这个120表示一共有120行数据。数据样本从第2行开始到第121行,所有数据都有5列。
其中前4列是鸢尾花的属性,第5列是鸳尾花的品种,用整数0,1,2分别表示山鸢尾,变色鸢尾和维基尼亚鸢尾。
下载数据集
如果以后要下载其他数据集,只需要改变url和fname就可以了。
为了提高代码的通用性,我们使用split()函数来分割字符串。
# 下载数据集
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL)
Pandas访问csv数据集
Pandas库
Pandas的名称来自于panel data和data analysis,是Python环境下最有名的用于数据统计和分析的第三方库。通过它可以高效方便的访问和操作大型数据集,在Anaconda中已经自带了pandas库,可以直接使用import语句导入,通常别名为pd。
import pandas as pd
Pandas二维数据基本操作
读取csv数据集文件
Pandas中使用read_csv()方法读取csv格式的数据文件。
pd.read_csv(filepath_or_buffer, header, names)
pd.read_csv(C:\Users\dell\.keras\datasets\iris_train.csv)
其中参数filepath_or_buffer是文件名,可以是绝对路径也可以是相对路径。
如果之前没有下载,那么使用get _file()函数下载数据集的返回值就是数据集文件在本地磁盘中的绝对路径,可以直接使用它作为read_csv()函数的参数。
这是运行结果。
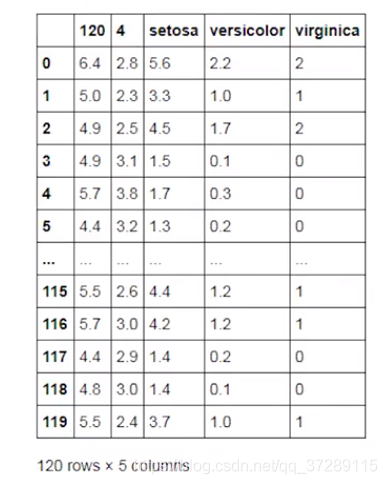
可以看到返回值是一个二维表格,其中一共有120行,5列。
将read_csv()函数的返回值赋值给变量df_iris,并输出它的数据类型,
df_iris = pd.read_csv(train_path)
print(type(df_iris))

这个DataFrame是二维表格类型,它是pandas中的一种非常常用的数据类型。
设置列标题
在read_csv()函数中,可以通过header参数指定数据表中的某一行或者某几行作为列标题,也就是表头。
pd.read_csv(filepath_or_buffer, header, names)
header的取值是行号,行号从0开始。
- header=0,第一行的数据作为列标题(默认设置)
- header=None,没有列标题
例如:
- header=0,第一行数据作为列标题
df_iris = pd.read_csv(train_path, header=0)
df_iris.head()
运行结果:

可以看到数据集中的第1行数据被当做了列标题,但是这一行数据其实并不是列标题,这些数据分别是样本的条数以及三种鸢尾花的名称,因此我们把header设置为None表示数据文件中没有表头。
- header=None,第一行数据作为列标题
df_iris = pd.read_csv(train_path, header=None)
df_iris.head()
运行结果:

可以看到系统自动的加上了数字序列,0~4作为列标题,这样显然并不友好,第1行数据现在被作为了数据样本,这样也不对,这一行数据既不是列标题,也不是数据样本,为了正确的显示列标题和数据样本,可以设置read_csv()方法中的names参数。
names参数
自定义列标题,代替header参数指定的列标题。
pd.read_csv(filepath_or_buffer, header, names)
names参数的值是一个列表用来指定自定义列标题,从而代替header参数指定的列标题。
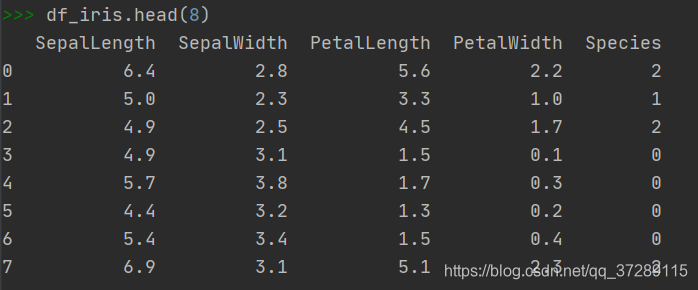
在这个例子中,我们希望自己定义一个更加友好的列标题,并且不显示第1行数据,可以首先使用header=0,把第1行看作列标题,然后再使用names参数指定新的列标题替换掉原有的列标题。
COLUMN_NAMES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']
df_iris = pd.read_csv(train_path, header=0, names=COLUMN_NAMES)
df_iris.head()
运行结果:

可以看到COLUMN_NAMES中的元素被显示为表头了
访问数据
head()函数:参数为空时,默认读取二维数据表中的前5行数据。
也可以设置参数n,读取前n行数据
head(n)
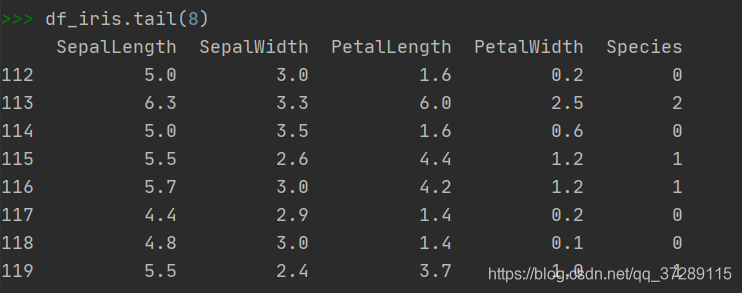
tail()函数:读取后n行数据
tail(n)
参数为空时,读取后5行数据。
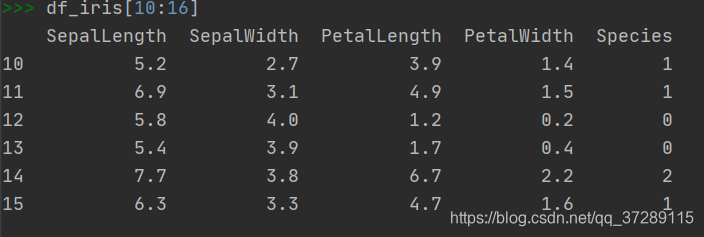
如果要更加灵活的读取指定的数据行,可以使用索引和切片
df_iris[10:16]
这是读取行号 10 - 15 的数据样本
显示统计信息
describe()方法:显示二维数组的统计信息。
describe()

从而了解数据是否有缺失,以及数据的分布情况。
DataFrame的常用属性:ndim、size、shape
| 属性 | 描述 |
|---|---|
| ndim | 数据表的维数 |
| shape | 数据表的形状 |
| size | 数据表元素的总个数 |
df_iris.ndim
# 2
df_iris.shape
# (120, 5)
df_iris.size
# 600
转化为NumPy数组
在对DataFrame数据进行后续处理时,经常需要将它转换成NumPy数组。这时,可以直接使用NumPy中的创建数组函数array()
iris = np.array(df_iris)
print(type(df_iris))
# <class 'pandas.core.frame.DataFrame'>
print(type(iris))
# <class 'numpy.ndarray'>
也可以使用.values和.as_matrix()来将Dataframe转化为数组
iris = df_iris.values
iris = df_iris.as_matrix()
访问数组元素–索引和切片
转化为NumPy后,也可以使用数组的索引和切片访问指定的数据。
例如:
- 读取前六行数据
iris[0:6]
"""
array([[6.4, 2.8, 5.6, 2.2, 2. ],[5. , 2.3, 3.3, 1. , 1. ],[4.9, 2.5, 4.5, 1.7, 2. ],[4.9, 3.1, 1.5, 0.1, 0. ],[5.7, 3.8, 1.7, 0.3, 0. ],[4.4, 3.2, 1.3, 0.2, 0. ]])
"""
- 读取前六行数据的前4列
iris[0:6, 0:4]
"""
array([[6.4, 2.8, 5.6, 2.2],[5. , 2.3, 3.3, 1. ],[4.9, 2.5, 4.5, 1.7],[4.9, 3.1, 1.5, 0.1],[5.7, 3.8, 1.7, 0.3],[4.4, 3.2, 1.3, 0.2]])
"""
- 得到所有数据行中“鸢尾花的种类”的取值
iris[:, 4]
"""
array([2., 1., 2., 0., 0., 0., 0., 2., 1., 0., 1., 1., 0., 0., 2., 1., 2.,2., 2., 0., 2., 2., 0., 2., 2., 0., 1., 2., 1., 1., 1., 1., 1., 2.,2., 2., 2., 2., 0., 0., 2., 2., 2., 0., 0., 2., 0., 2., 0., 2., 0.,1., 1., 0., 1., 2., 2., 2., 2., 1., 1., 2., 2., 2., 1., 2., 0., 2.,2., 0., 0., 1., 0., 2., 2., 0., 1., 1., 1., 2., 0., 1., 1., 1., 2.,0., 1., 1., 1., 0., 2., 1., 0., 0., 2., 0., 0., 2., 1., 0., 0., 1.,0., 1., 0., 0., 0., 0., 1., 0., 2., 1., 0., 2., 0., 1., 1., 0., 0.,1.])
"""
Pandas拥有丰富的数据处理函数,不仅可以处理二维数据表,还支持时间序列分析,具有非常强大的数据分析能力。
鸢尾花数据集可视化
这里,我们依然借助数据可视化的方法来观察鸢尾花的数据。
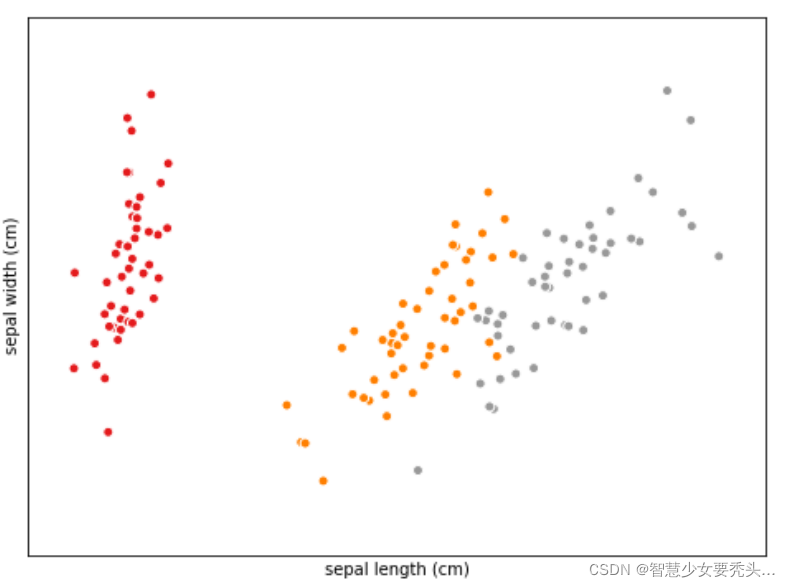
鸢尾花数据散点图
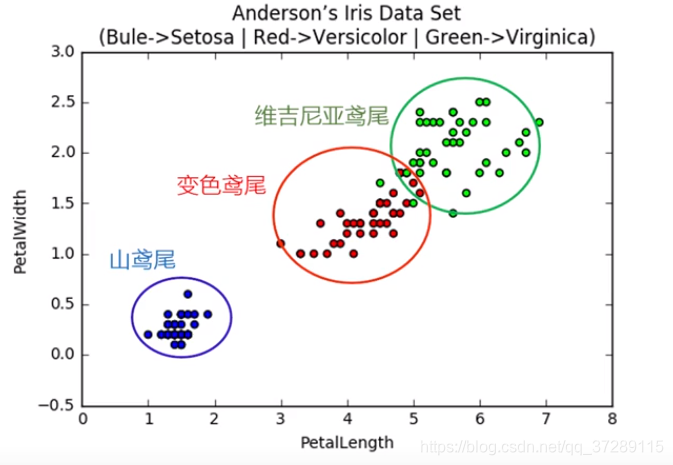
在这张图中,横坐标和列坐标分别是鸢尾花的花瓣长度和花瓣宽度。不同颜色代表不同种类的鸢尾花。
很容易看出来,花瓣最窄最短的是山鸢尾,花瓣最长最宽的是维基尼亚鸢尾,花瓣尺寸居中的是变色鸢尾,这种可视化后的数据和原始的数字相比更加的直观和清晰。
花瓣长度
iris[:,2]
array([5.6, 3.3, 4.5, 1.5, 1.7, 1.3, 1.5, 5.1, 4.4, 1.5, 3.9, 4.9, 1.2,1.7, 6.7, 4.7, 5.9, 6.6, 5.3, 1.5, 5.7, 5.6, 1.3, 5.6, 5.8, 1.5,4. , 5.1, 4.5, 5. , 4.4, 3. , 4.5, 5.5, 4.8, 5.7, 5.1, 5.1, 1.5,1.4, 6.4, 5.1, 5.2, 1.9, 1.6, 5. , 1.6, 6.9, 1. , 6. , 1.4, 4.4,4. , 1.2, 4.7, 4.8, 6.1, 5.1, 5.4, 3.5, 3.9, 5.6, 5. , 5.5, 4.5,6.3, 1.3, 6.1, 5.5, 1.5, 1.3, 4.6, 1.3, 6.1, 4.9, 1.5, 3.8, 4.2,4.5, 5.3, 1.5, 4.7, 4.6, 4.2, 5.6, 1.5, 4.8, 4.5, 5.1, 1.3, 5.2,4.7, 1.4, 1.5, 5.8, 1.4, 1.4, 6.7, 4.8, 1.6, 1.4, 3.3, 1.3, 4.1,1.6, 1.4, 1.5, 1.4, 3.6, 1.6, 4.9, 4.1, 1.6, 6. , 1.6, 4.4, 4.2,1.4, 1.4, 3.7])
花瓣宽度
iris[:,3]
array([2.2, 1. , 1.7, 0.1, 0.3, 0.2, 0.4, 2.3, 1.4, 0.4, 1.4, 1.5, 0.2,0.4, 2.2, 1.6, 2.3, 2.1, 2.3, 0.4, 2.1, 2.1, 0.4, 1.4, 1.6, 0.2,1.2, 1.8, 1.5, 1.7, 1.3, 1.1, 1.5, 2.1, 1.8, 2.3, 2. , 2.4, 0.3,0.3, 2. , 1.9, 2.3, 0.4, 0.2, 1.5, 0.2, 2.3, 0.2, 1.8, 0.2, 1.4,1.3, 0.2, 1.4, 1.8, 1.9, 1.9, 2.3, 1. , 1.1, 2.4, 1.9, 1.8, 1.5,1.8, 0.2, 2.5, 1.8, 0.2, 0.2, 1.3, 0.2, 2.3, 1.8, 0.1, 1.1, 1.3,1.5, 1.9, 0.2, 1.4, 1.5, 1.3, 2.4, 0.1, 1.4, 1.3, 1.6, 0.3, 2. ,1.2, 0.3, 0.2, 2.2, 0.3, 0.2, 2. , 1.8, 0.2, 0.2, 1. , 0.3, 1. ,0.4, 0.2, 0.2, 0.2, 1.3, 0.2, 1.8, 1.3, 0.2, 2.5, 0.6, 1.2, 1.2,0.2, 0.1, 1. ])
将它们作为横坐标和纵坐标绘制散点图
plt.scatter(iris[:, 2], iris[:, 3])
plt.show()

虽然散点图绘制出来了,但是不同类型的鸢尾花并没有被区分开。我们希望不同品种使用不同的颜色,这就要用到色彩映射。
色彩映射
将参数c指定为一个列表或数组,所绘制图形的颜色,可以随这个列表或数组中元素的值而改变,变换所对应的颜色由参数cmap中的颜色所提供。
plt.scatter(x, y, c, cmap)
# 颜色映射
x = np.arange(10)
y = np.arange(10)
dot_color = [0, 1, 2, 0, 1, 2, 2, 1, 1, 0]
plt.scatter(x, y, c=dot_color, cmap='brg')
plt.show()


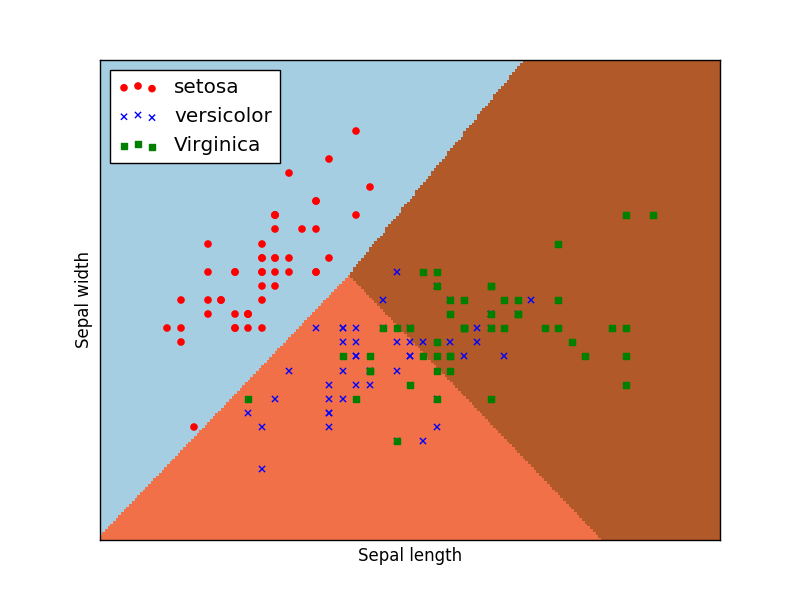
下面,我们用颜色映射来改进鸢尾花的散点图。我们应该用鸢尾花的种类来作为颜色变换的依据。鸢尾花的种类是数据集中的最后一列,也就是第二维的索引值为4.
plt.scatter(iris[:, 2], iris[:, 3], c=iris[:, 4], cmap='brg')
plt.show()
 可以看到,不同品种的鸢尾花,已经采用不同颜色分开了。
可以看到,不同品种的鸢尾花,已经采用不同颜色分开了。
下面再增加标题和横纵标签
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL)COLUMN_NAMES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']
df_iris = pd.read_csv(train_path, header=0, names=COLUMN_NAMES)iris = np.array(df_iris)plt.scatter(iris[:, 2], iris[:, 3], c=iris[:, 4], cmap='brg')
plt.title("Anderson's Iris Data Set\n(Blue->Setosa | Red->Versicolor | Green->Virginica)")
plt.xlabel(COLUMN_NAMES[2])
plt.ylabel(COLUMN_NAMES[3])
plt.show()
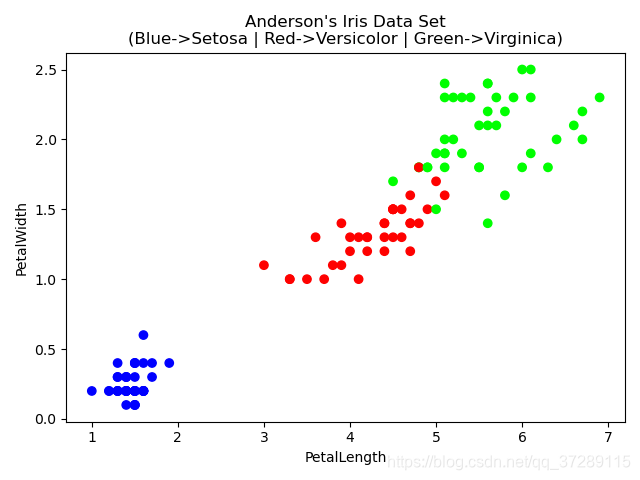
在这张图中,我们实现了对鸢尾花数据集中的属性,花瓣长度,花瓣宽度的可视化。可以发现,通过花瓣的尺寸可以比较好的区分开,不同品种的鸢尾花。那么通过这个数据集中的其他属性,是否也能够比较好的区分出鸢尾花的种类呢?
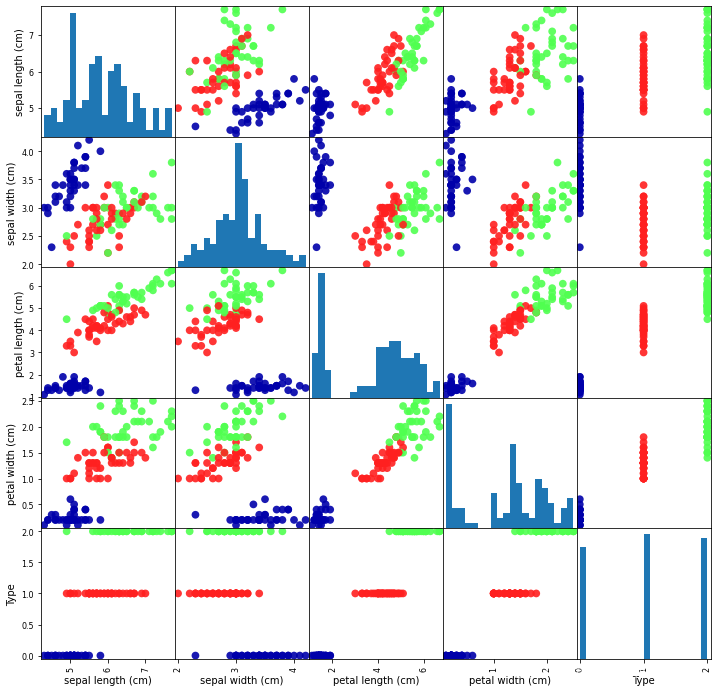
在鸢尾花数据集中,有4个属性。将所有的属性两两组合可以得到16种组合可以看到对角线上的这4种组合,是同一种属性自己的组合可以去除,右上角的这6种情况和左下角的这6种情况是对称的,就是说有效的组合有6种。

这是把所有可能的组合全部可视化在一张图的结果。

TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL)COLUMN_NAMES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']
df_iris = pd.read_csv(train_path, header=0, names=COLUMN_NAMES)iris = np.array(df_iris)# 设置画布尺寸
fig = plt.figure('Iris Data', figsize=(15, 3))
# 设置整个的画布标题
fig.suptitle("Anderson's Iris Data Set\n(Blue->Setosa | Red->Versicolor | Green->Virginica)")for i in range(4):plt.subplot(1, 4, i + 1)if i == 0:plt.text(0.3, 0.5, COLUMN_NAMES[0], fontsize=15)else:plt.scatter(iris[:, i], iris[:, 0], c=iris[:, 4], cmap='brg')plt.title(COLUMN_NAMES[i])plt.ylabel(COLUMN_NAMES[0])# 调整子图间距
plt.tight_layout(rect=[0, 0, 1, 0.9])
plt.show()
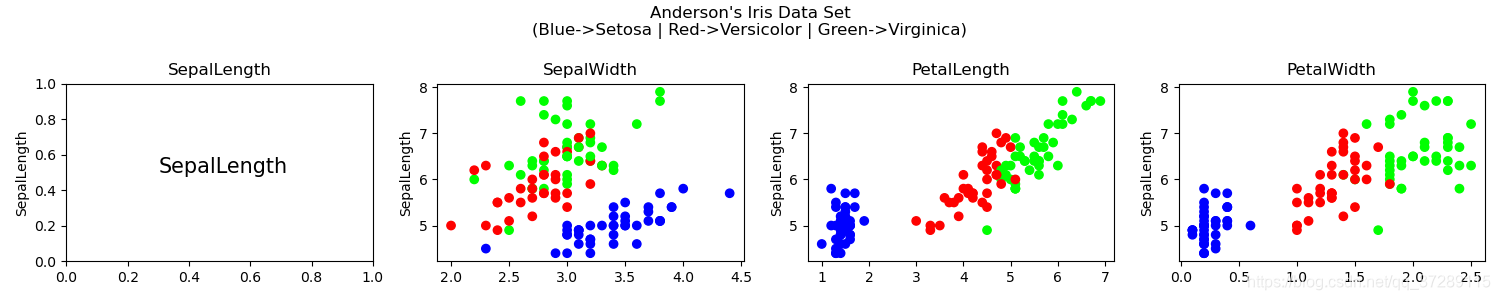
下面采用双重循环来绘制4*4的大图
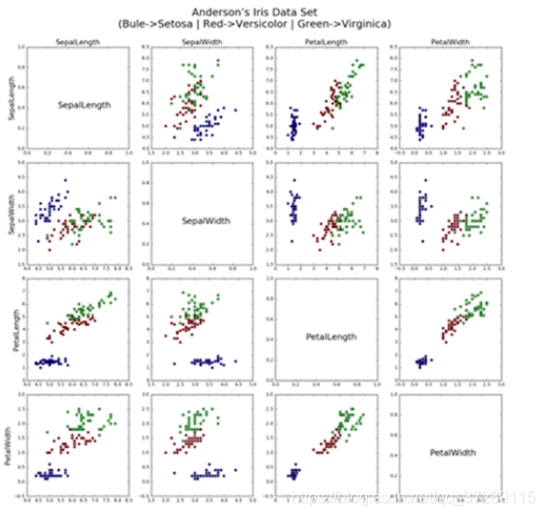
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL)COLUMN_NAMES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']
df_iris = pd.read_csv(train_path, header=0, names=COLUMN_NAMES)iris = np.array(df_iris)# 设置画布尺寸
fig = plt.figure('Iris Data', figsize=(15, 15))
# 设置整个的画布标题
fig.suptitle("Anderson's Iris Data Set\n(Blue->Setosa | Red->Versicolor | Green->Virginica)")for i in range(4):for j in range(4):plt.subplot(4, 4, 4 * i + (j + 1))if i == j:plt.text(0.3, 0.4, COLUMN_NAMES[i], fontsize=15)else:plt.scatter(iris[:, j], iris[:, i], c=iris[:, 4], cmap='brg')if i == 0:plt.title(COLUMN_NAMES[j])if j == 0:plt.ylabel(COLUMN_NAMES[i])# 调整子图间距
plt.tight_layout(rect=[0, 0, 1, 0.93])
plt.show()

可以看出来,通过花瓣和花萼的属性的任何组合,都能够很容易地将山鸢尾和另外两种鸢尾花区分开来。而变色鸢尾和维基尼亚鸢尾,通过花瓣属性能够比较容易的区分,通过花落属性则不能明显的区分。
这种可视化数据的方法为我们分析数据提供了有效的手段。