最近我又又又开始了我的机器学习道路,并且回过头来重新看了一遍Iris数据分析,作为机器学习里面最经典的案例之一,鸢尾花既是我入门机器学习到放弃的地方,又是再次细读之后给予我灵感的地方。
下面介绍一下这次灵感之旅,希望也能带给看到这篇文章的你一些帮助。
1. 从一堆鸢尾花说起
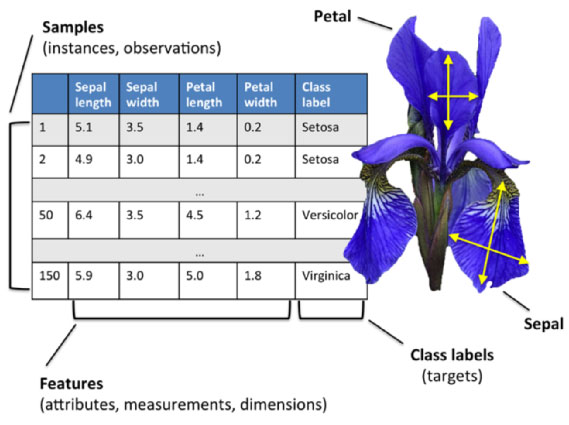
如果一个植物学家在野外看到一花萼长5cm宽2.9cm,花瓣长1cm宽0.2cm的鸢尾花,并且在他的认知里,这种鸢尾花有三个分支品种,这时候,他手里有来自UCI数据集网站的鸢尾花数据,那么他能否根据这对数据集预测这株鸢尾花的所属分支
2. 导入鸢尾花数据
import sklearn
from sklearn.datasets import load_irisiris_dataset :sklearn.utils.Bunch= load_iris() # 这里是将Python数据指定类型,转换成强语言,为了方便读取可用方法属性print(type(iris_dataset)) # 查看类型,返回的是一种类似于字典的数据类型
print("iris_Keys : " , iris_dataset.keys()) #对这种类似字典的数据操作,查看数据集的属性输出:
<class 'sklearn.utils.Bunch'>
iris_Keys : dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])
3. 核心数据
# 通过对values获取,得到鸢尾花特征值集合,其实也可以通过上面类字典的键获取,下面介绍
print("iris_values : \n")
iris_dataset.values()
# 这段代码可以获取鸢尾花特征名字,比如花瓣长度
iris_dataset['feature_names']
到这里我们获得一堆鸢尾花特征数据,我把它整理并放在了网上, 点击获取
4. 回望我们的目的
一开始我就介绍,植物学家想通过数据集预测这是个什么种类的鸢尾花,这时候我们可以就获取这些相关种类了
# 获取种类
iris_dataset['target_names']# 这里返回的是一个numpy.ndarray数组,并且以表格形式呈现
setosa
versicolor
virginica
在实际数据集中,种类被简化成0、1、2这三个数字,我们可以通过下列方法查看。
flowerTypes = iris_dataset['target']
flowerTypes通过第三点的核心数据,以及第四点的种类,我们使用pandas.Dataframe转换成更明显完整的可视化表格,因为往后我还会用到这个完整表格
import pandas, numpy
data = iris_dataset['data']
col :list = iris_dataset['feature_names']
copyCol = col.copy()
copyCol.append('Type')
flowerTypes = iris_dataset['target']
newData = numpy.c_[data, flowerTypes]
dataDf = pandas.DataFrame(newData, columns=copyCol)
dataDf这里附上完整版本的表格(相对上一个链接多了种类),点击下载
5. 到现在我们做了什么?
写到这,其实我们只是导入了一个数据集,并处理好,仅此而已,下面才是真正的建立模型
6. 做一个小思考
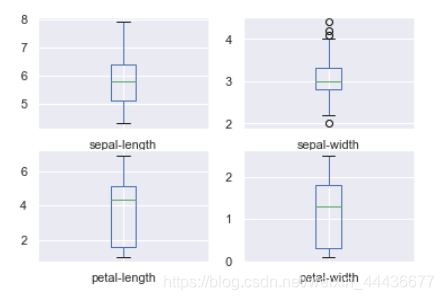
通过对上面的数据集查看,我们仅有150个鸢尾花数据,我们将围绕这一个数据集团团转,下面将要提到的额外预测方法也是,在机器学习书上,会经常提到泛化这个词,听起来很学术的一个词,其实就是想要表达一个训练过的模型的向外扩展能力怎么样(比如这里就是预测一株新的鸢尾花种类),这里就需要对数据集有经验的分类,这里暂且以25%(大佬们的经验法则)鸢尾花数据作为测试,剩下的作为训练集。
7.开始建立
按照上一点进行数据划分。
from sklearn.model_selection import train_test_split
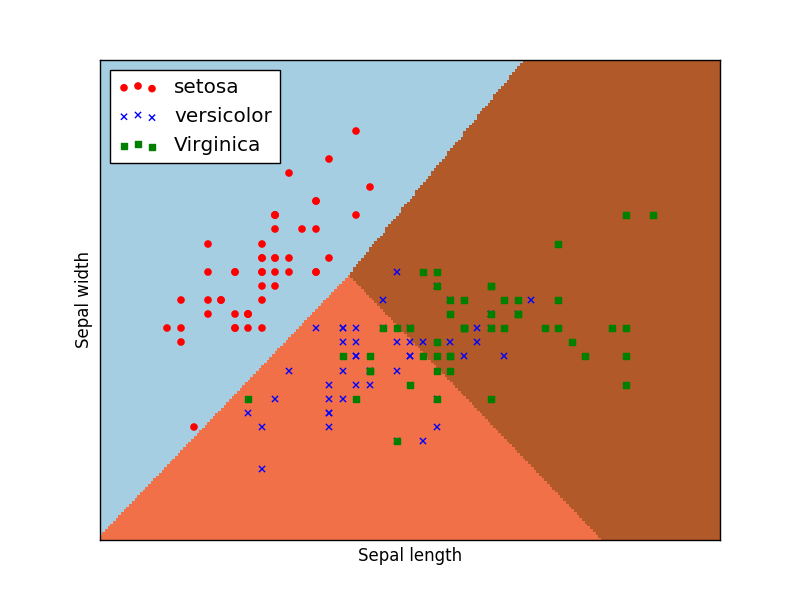
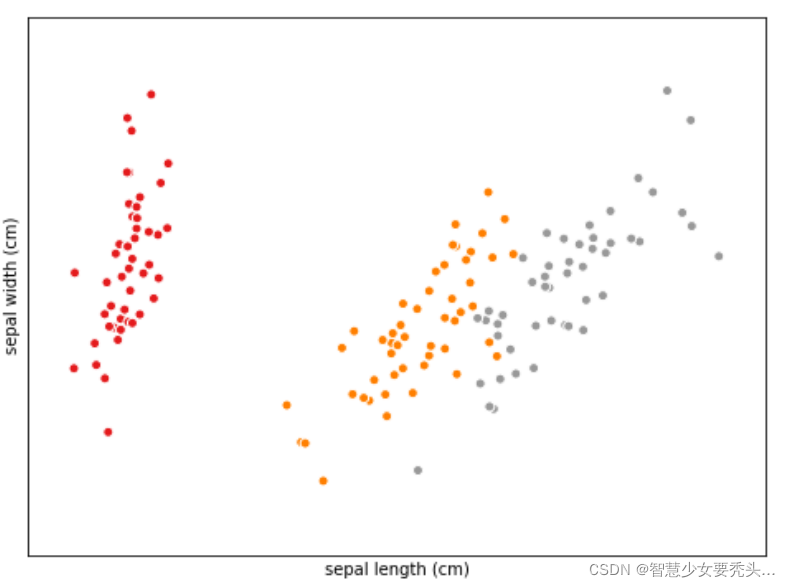
X_train, X_test, y_train, y_test = train_test_split(data, iris_dataset['target'], random_state=42)对数据分析的一个很好方式就是进行可视化,这里也不例外。这里我们通过绘制散点图矩阵(就是各种特征组成坐标轴的图片,其实我好奇为什么不叫矩阵散点图@_@),mglearn库在这里是一个颜色渲染用的,大可不必纠结。
from pandas import plotting
import mglearn
grr = plotting.scatter_matrix(iris_dataframe,c=y_train,figsize=(16, 16),marker='o',hist_kwds=dict(bins=20),s=60,alpha=0.9,cmap=mglearn.cm3)
grr
你是否感到这张密密麻麻的图片不容易对数据分析,我当时感到就是这样(这图是什么鸟玩意@_@) ,那么不必担心,这时候我上面提到的第二个完整版本的数据就有用处了
newX_train, newX_test, newy_train, newy_test = train_test_split(newData, iris_dataset['target'], random_state=42)
new_iris_dataframe = pandas.DataFrame(newX_train, columns=copyCol)
new_grr = plotting.scatter_matrix(new_iris_dataframe,c=newy_train,figsize=(16, 16),marker='0',hist_kwds=dict(bins=20),s=60,alpha=0.9,cmap=mglearn.cm3)我把种类也作为特征,并对每一种本身特征进行划分,从下图边缘几个图你会很容易看到
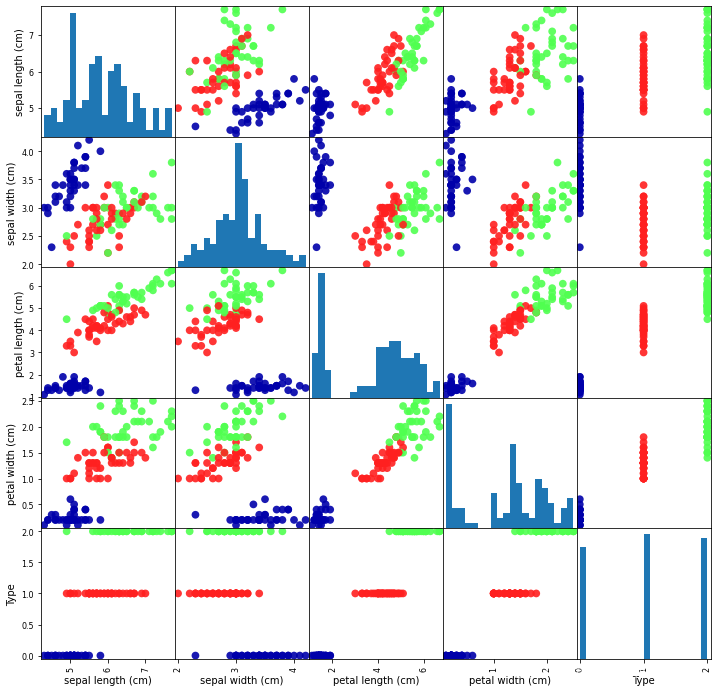
如果让坐标轴放大并且更精确,我们简直可以对着数据找种类,但是我们不打算这么做,因为有模型这种强大的工具,可以帮我们以高精度演算,并且对于决策边界周围那样的数据(比如上图左下角可以看出sepal length=5.5cm可能属于0代表的种类,也可能是1代表的种类,假如其他三个特征也有这类情况出现),我肯定不希望另起草稿算可能性分布来帮助机器预测,这恐怕事与愿违,反而,应该是机器帮助我预测。
8.重头戏——模型建立
终于,在经历种种准备后,我们要开始建模了,就像是一个固定的“流水线”,把处理好的数据导入模型,下面我们开始第一个用于分类的模型——KNN(K近邻算法)。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)"流水线"一般分为以下几个步骤:
1. 选择模型并且导入
from sklearn.neighbors import KNeighborsClassifier
2. 创建模型实例并传入参数
knn = KNeighborsClassifier(n_neighbors=5)
3. 准备数据
X_train, X_test, y_train, y_test = train_test_split(data, iris_dataset['target'], random_state=42)
4. 数据拟合
knn.fit(X_train, y_train)
# 预测
X_new = numpy.array([[5, 2.9, 1, 0.2]])
prediction = knn.predict(X_new)
print("predict : " , prediction)
print("prediction type : " , iris_dataset['target_names'][prediction])
5. 预测
见上述代码
结果:
predict : [0]
prediction type : ['setosa']
得到预测种类了,我们是不是可以告诉植物学家这是一种 'setosa'鸢尾花,还没有!
我们不知道,我们创建的这个模型准确率如何?下面还得验证一下。
y_pre = knn.predict(X_test)
print(y_pre) # [1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0 0 0 1 0 0 2 12]
knn.score(X_test, y_test) # 0.9797%! 已经是一个很高的预测准确率了。
下面尝试另一种方法,SVM,可以将每一种种类可能性都预测一遍,返回一组评估数组
from sklearn.svm import SVC
svmClf = SVC(random_state=42)
svmClf.fit(X_train, y_train)
all_pre_and_get_score = svmClf.decision_function(X_new)
all_pre_and_get_score结果:
2.237142,1.101841,-0.247978
我们得到的数组有三个值,分别对应0、1、2这三个种类,我们尝试用softmax函数在保持数大小关系不动的前提将它们转换成0~1之间的数,目的是折换成概率(你也可以跳过softmax函数,因为我们只追求SVM作用)
Softmax函数实现:
# Softmax函数
def Softmax(s : list or numpy.ndarray):S = numpy.array([numpy.exp(i) for i in s])u = numpy.sum(S)for j in S:yield j/u
# 转换
for i in Softmax(all_pre_and_get_score):print(i)结果:
[0.71192572 0.22875983 0.05931445]
我们得到71%概率是0代表种类,……
在SVM中,哪种预测结果最大,我们就认为该结果属于最大一类,因此我们可以通过SVM预测和测试集算出准确率。
# SVM基础上对测试集预测,并算出准确率
pre_list = []
for i in X_test:# 获取SVM预测对应的索引,索引即种类代号i = numpy.array([i])each_pre = svmClf.decision_function(i)eh = each_pre.reshape(-1)pre_list.append(numpy.where(eh == numpy.max(eh))[0][0])
pre_list = numpy.array(pre_list).reshape(y_test.shape)
print(pre_list == y_test)结果:
[ True True True True True True True True True True True True
True True True True True True True True True True True True
True True True True True True True True True True True True
True True]
结果很让人吃惊,居然达到100%准确率。
总结:
1. 机器学习的模型布创建步骤以及实践,即上述——“流水线”,其实这里需要补充一点,通过对参数的设置,会打乱数据(因为数据原来是有规律的——前面是一种鸢尾花,中间是一种,后面是一种)。 所以,打乱反而是好事。
2. 两种模型的对比和模型总结:
(1 ).两种模型都获得了理想的预测准确率(虽然我们不知道植物学家会不会相信我们的预测,但高准确率的结果让我们足够有把握)
(2).若想提高准确率(虽然以及够高了,甚至SVM达到100%),但是我们必须接受事实——数据集实在太少了,准确率就会有明显差,当数据集逐渐增加,我们能轻松想象到一个收敛函数终究收敛到一个值,如果出现97.3%, 97.5%都无所谓了,我就可以认为是97%(对于我来说)(假如97%已经算够高的!),另外这里仅仅用了2个模型,还可以尝试别的模型,比如SGD分类(我试了,虽然获得的精度不尽人意)