文章目录
- 基本组成
- 阻塞队列
- 有界队列与无界队列
- ArrayBlockingQueue
- LinkedBlockingQueue
- SynchronousQueue
- 流量控制与信号量(Semaphore)
- 双缓冲与Exchanger
基本组成
生产者:生产者的任务是生产产品,产品可以是数据,也可以是任务。(将产品存入传输通道的线程被称为生产者线程)
消费者:消费者的主要职责是消费的产品。(从传输通道中取出产品进行消费的线程被称为消费者线程)
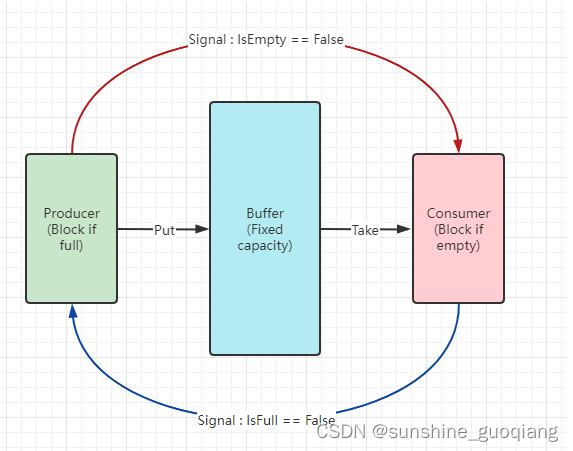
传输通道:生产者和消费者是并发运行在各自的线程中,这就意味着可以使程序原本串行的处理得以并发化。但线程之间无法像函数调用那样通过参数直接传递数据,因此生产者和消费者之间需要一个用于传递产品的传输通道,通道相当于中间的缓冲区,生产者每生产一个产品就将其放入到传输通道,消费者则不断的从传输通道中取出产品进行消费。因为生产者和消费者都可以各自运行在一个或多个线程中,所以传输通道一般使用线程安全的队列。
阻塞队列
有界队列与无界队列
当传输通道为空的时候消费者无法取出产品,此时消费者进行等待,直到传输通道非空;当传输通道存储空间满的时候生产者无法存入新的产品,此时生产者线程进行等待,直到传输通道非满。生产者线程向传输通道成功存入产品后会唤醒等待传输通道非空的消费者线程,消费者线程从传输通道取出一个产品后会唤醒等待传输通道非满的生产者线程,这种方式被称为阻塞式(Blocking)。一个方法或操作能够导致其执行的线程被暂停(生命状态变为WAITING或BLOCKED),这种方法就被称为阻塞方法(Blocking Method),常见的阻塞方法有ReentrantLock.lock、申请内部锁等。相反,如果一个方法或操作并不会导致其执行线程被暂停,那么相应的方法就被称为非阻塞方法(Non-blocking Method)。
阻塞队列按照其存储空间是否受限制来划分,可分为有界队列(Bounded Queue)和无界队列(Unbounded Queue),有界队列的存储容量限制是由程序指定的,无界队列的最大容量为Integer.MAX_VALUE个元素。
往队列中存入一个元素的操作被称为put操作,从队列中取出一个元素的操作被称为take操作。
当消费者处理能力低于生产者处理能力时,这会导致队列中的产品积压,由此导致队列中的产品所占用的内存空间越来越多,如果想要限制传输通道的存储容量,可以使用有界阻塞队列作为传输通道。
有界队列的另外一个好处是可以“反压”:当消费者能力跟不上生产者的生产能力时,队列中的产品会逐渐积压变满,此时生产者会被暂停,直到消费者消费了部分线程而使队列非满。这在一定程度上给了消费者跟上步伐的机会,但生产者会进行上下文切换。
ArrayBlockingQueue
有界队列可以使用 ArrayBlockingQueue 或者 LinkedBlockingQueue ,ArrayBlockingQueue内部使用一个数组作为存储空间,是预先分配好的,因此它的put和take操作不会增加垃圾回收的负担。但其缺点是在执行put、take操作时使用的是同一把锁,多个生产者或消费者情况下会导致过多的上下文切换。
LinkedBlockingQueue
LinkedBlockingQueue 既可以实现无界队列,也可以实现有界队列。它的优点是内部在实现take、put操作的时候使用两个锁(putLock和takeLock),这样就降低了锁竞争,减少了上下文切换,但其内部实现是一个链表,链表节点所需的存储空间是动态分配的,因此会增加垃圾回收的负担。除此之外,因为LinkedBlockingQueue使用的是两把锁,其维护当前队列长度的时候无法使用int变量,需要使用原子变量AtomicInteger,因而也增加了额外的开销。
SynchronousQueue
SynchronousQueue 是一种特殊的无界队列,当生产者线程执行put操作时,如果没有消费者线程执行take,则该生产者线程会被暂停;当消费者线程执行take时,如果没有生产者执行put,则消费者线程会被暂停,也就是说,以SynchronousQueue作为传输通道的话,生产者和消费者只能“交换”一个产品,就像是一手交钱,一手交货。因此,SynchronousQueue 适用于生产者和消费者处理能力差不多的情况下,否则,当生产者执行put,但消费者没有执行take(反过来也是一样),就会进行较多的等待。
阻塞队列也可以支持非阻塞操作,可以使用BlockingQueue接口定义的offer和poll来替代put和take。offer返回false表示队列已满或入队失败,poll返回null表示队列为空。
提示:
1、LinkedBlockingQueue 适合在生产者线程和消费者线程之间并发程度比较大的情况下使用。
2、ArrayBlockingQueue 适合在生产者线程和消费者线程之间并发程度较低的情况下使用。
3、SynchronousQueue 适合在生产者线程和消费者线程之间处理能力相差不大的情况下使用。
流量控制与信号量(Semaphore)
使用无界队列的一个好处是不会导致线程被阻塞。但消费者的消费能力跟不上生产者的生产能力时,会导致数据的积压,因此,在使用无界队列作为传输通道的时候一般会限制生产者的速率,即进行流量控制。
我们可以使用jdk 1.5中的Semaphore来实现限流。我们把代码所访问的特定资源或者执行的特定操作的机会统一看作一种资源,这种资源被称为虚拟资源。Semaphore 相当于虚拟资源配额管理器,它可以用来控制同一时间内对虚拟资源的访问次数。只有当线程获取到配额,才能访问资源,并在访问完资源后进行配额的释放。 acquire、release 分别对应获取配额和释放配额。如果当前配额不足,则执行acquire会进行阻塞,直到配额不为0。Semaphore内部会维护一个等待队列用于存储这些被暂停的线程,在执行acquire时会将配额减1,在执行release时会将配额加1,并随机唤醒等待队列中的一个线程。
下面实现一个demo来对上面所有的内容进行一个回顾:
队列的抽象接口:
public interface Channel<P> {//向传输通道中放入一个产品void put(P product);//从传输通道中取出一个产品P take();}
队列的实现类:
public class SemaphoreDemo<P> implements Channel<P> {private final BlockingQueue<P> queue;private final Semaphore semaphore;public SemaphoreDemo(BlockingQueue<P> queue, int flowLimit) {this(queue, flowLimit, false);}public SemaphoreDemo(BlockingQueue<P> queue, int flowLimit, boolean isFair) {this.queue = queue;this.semaphore = new Semaphore(flowLimit, isFair);}@SneakyThrows@Overridepublic void put(P product) {//申请一个配额semaphore.acquire();try {//访问虚拟资源queue.put(product);} catch (InterruptedException e) {e.printStackTrace();} finally {//返回一个配额semaphore.release();}}@SneakyThrows@Overridepublic P take() {return queue.take();}
}
客户端:
public class Demo {public static void main(String[] args) throws InterruptedException {//使用无界队列,最多只能有两个线程同时执行SemaphoreDemo<String> semaphoreDemo = new SemaphoreDemo<>(new LinkedBlockingQueue<String>() , 2);//5个线程同时putfor (int i = 0; i < 5; i++) {int finalI = i;new Thread(() -> {StopWatch stopWatch = new StopWatch(String.valueOf(finalI));stopWatch.start(String.valueOf(finalI));semaphoreDemo.put("product" + finalI);stopWatch.stop();System.out.println(stopWatch.prettyPrint());}).start();}Thread.sleep(1000);for (int i = 0; i < 5; i++) {String product = semaphoreDemo.take();}}
}
下面是打印的结果,可以看出有两个线程一个开始执行时间是1ms,说明没有被阻塞,后面的线程执行时间是2ms,是被阻塞的,也就是说,同时只能满足两个线程获取资源。
StopWatch '0': running time (millis) = 2
-----------------------------------------
ms % Task name
-----------------------------------------
00002 100% 0StopWatch '3': running time (millis) = 2
-----------------------------------------
ms % Task name
-----------------------------------------
00002 100% 3StopWatch '2': running time (millis) = 1
-----------------------------------------
ms % Task name
-----------------------------------------
00001 100% 2StopWatch '1': running time (millis) = 1
-----------------------------------------
ms % Task name
-----------------------------------------
00001 100% 1StopWatch '4': running time (millis) = 2
-----------------------------------------
ms % Task name
-----------------------------------------
00002 100% 4
双缓冲与Exchanger
多线程环境下,有时候我们会使用两个或者更多的缓冲区来实现数据从数据源到使用方的移动。其中一个缓冲区填充满来自数据源的数据后可以被数据使用方进行消费,另外一个空的或已经使用过的缓冲区则用来填充数据源的新数据。负责填充缓冲区的是生产者线程, 负责消费一个已经填充了缓冲区的线程是消费者线程。因此,当消费者线程消费了一个已经填充的缓冲区时,另外一个缓冲区可以由生产者进行填充,从而实现了数据生成与消费的并发。这种缓冲技术被称为双缓冲(Double Buffering)。
jdk 1.5中的Exchanger可以实现双缓冲,Exchanger相当于只有两个参与方的CyclicBarrier,Exchanger.exchange 相当于CyclicBarrier.await(如果有关CyclicBarrier使用不明确的可参考我的这篇博客这篇博客)
初始状态下,生产者和消费者各自创建一个空的缓冲区,消费者线程执行Exchanger.exchange时将参数指定一个空的或者已经使用过的缓冲区,生产者执行Exchanger.exchange时将参数指定一个已经填充完毕的缓冲区。只有当二者都执行完毕之后,才进行下一步操作。Exchanger.exchange的参数是对方需要的,返回值是自己需要的(也就是对方所指定的参数)。因此,这也可以看成是SynchronousQueue。
下面通过Exchanger实现一个一手交钱一手交货的小demo:
@Slf4j
public class ExchangerDemo {private static final Exchanger<String> exchanger = new Exchanger<String>();public static void main(String[] args) {new Thread(()->{String money = "money";try {String product = exchanger.exchange(money);log.info("I get the {}",product);} catch (InterruptedException e) {e.printStackTrace();}}).start();new Thread(()->{String product = "product";try {String money = exchanger.exchange(product);log.info("I get the {}",money);} catch (InterruptedException e) {e.printStackTrace();}}).start();}
}
打印结果如下: