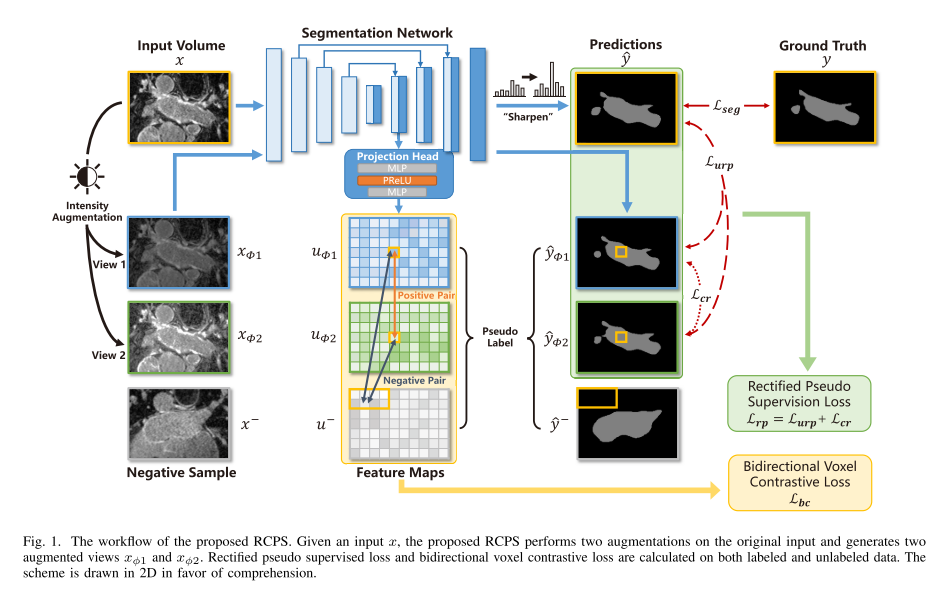
-
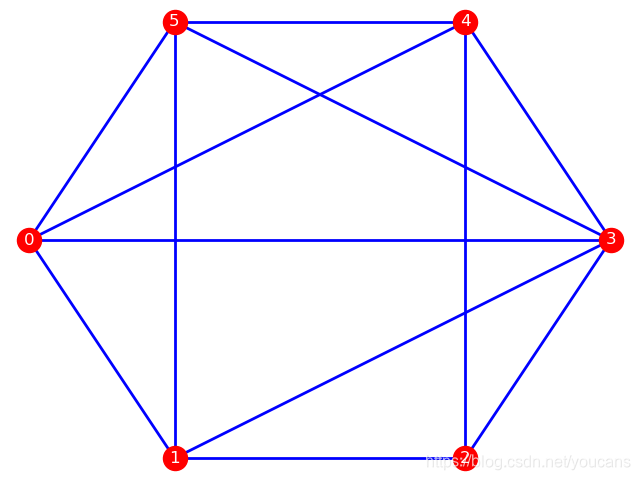
10.1 写出图10.20所示非赋权无向图的关联矩阵和邻接矩阵
-
绘制图
import networkx as nx import pylab as plt import numpy as np A=np.zeros((6,6)) List=[(1,2),(1,4),(2,3),(3,4),(3,5),(3,6),(4,5),(4,6),(5,6)] for i in List:A[i[0]-1,i[1]-1]=1 G=nx.Graph(A) pos=nx.spring_layout(G) nx.draw(G,pos,with_labels=True,font_size=12) plt.show()

-
-
10.2 计算图10.21所示赋权无向图中从 v 1 到 v 5 v_1到v_5 v1到v5的最短路径和最短距离
-
绘制图
import networkx as nx import pylab as plt import numpy as np LIST=[(1,2,7),(1,3,3),(1,4,12),(2,3,3),(2,6,2),(3,4,8),(4,5,1),(5,6,3)] G=nx.Graph() G.add_nodes_from(range(1,7)) G.add_weighted_edges_from(LIST) weight=nx.get_edge_attributes(G,'weight')#获取权重信息 pos=nx.shell_layout(G) nx.draw(G,pos,font_size=12,font_weight='bold',with_labels=True) nx.draw_networkx_edge_labels(G,pos,edge_labels=weight) plt.show()

-
求解任意两点的最短路
distance=dict(nx.shortest_path_length(G,weight='weight')) a=nx.to_numpy_matrix(G) m,n=a.shape for i in range(1,m+1):for j in range(1,n+1):if i!=j:print('{0}到{1}的最短距离为:{2}\n'.format(i, j, distance[i][j]))
-
-
10.3 求图10.21 所示赋权无向图的最小生成树
import networkx as nx import pylab as plt import numpy as np LIST=[(1,2,7),(1,3,3),(1,4,12),(2,3,3),(2,6,2),(3,4,8),(4,5,1),(5,6,3)] G=nx.Graph() G.add_nodes_from(range(1,7)) G.add_weighted_edges_from(LIST) T=nx.minimum_spanning_tree(G)#默认为破圈法 w=nx.get_edge_attributes(T,'weight') print("最小生成树的长度为:",sum(w.values())) nx.draw(T,pos=nx.shell_layout(T),with_labels=True,node_color='blue') nx.draw_networkx_edge_labels(T,pos=nx.shell_layout(T),edge_labels=w) plt.show()#最小生成树的长度为: 12

- 10.4 已知有6个村子,互相间道路的距离如图10.22所示,拟合建一所小学,已知A处有小学生100人,B处80人,C处60 人,D处40人,E处70人,F处90 人。问小学应再建在那个村庄,使学生上学最方便(走的总路程最短)

-
求每个点到其余各点的最短距离矩阵
-
(每个村庄)人数 × \times × 距离=总路程
import networkx as nx import pylab as plt import numpy as np #绘制图 nodes='abcdef'.upper() List=[(1,2,2),(1,3,7),(2,3,4),(2,4,6),(2,5,8),(3,4,1),(3,5,3),(4,5,1),(4,6,6),(5,6,3)] G=nx.Graph() G.add_nodes_from(range(1,7)) G.add_weighted_edges_from(List) w=nx.get_edge_attributes(G,'weight') pos=nx.shell_layout(G) nx.draw(G,pos,node_color='red',labels=dict(zip(range(1,7),list(nodes)))) nx.draw_networkx_edge_labels(G,pos,font_size=10,edge_labels=w) plt.show() #构造最短距离矩阵 distance=nx.shortest_path_length(G,weight='weight') matrix=np.zeros((6,6)) for i in distance:a=i[0]-1for j in range(1,7):matrix[a][j-1]=i[1][j] person=np.array([100,80,60,40,70,90]).reshape(6,1) print((matrix@person).flatten())#结果: #[2350. 1870. 1550. 1590. 1710. 2490.] 由此可见应在C处建学校 -
10.5 已知95个目标点的数据(excel),第一列是这95个点的编号,第2,3列是这95个点 x , y x,y x,y 坐标,第4列这些点重要性分类,表明“1”的是第一类重要目标点,表面“2”的是第二列重要点,未标明类别的是一般目标点,第5,6,7列标明了这些点的链接关系。如第三行数据:
C C C -1160 587.5 D F
表示顶点 C C C 的坐标为 ( − 1160 , 587.5 ) (-1160,587.5 ) (−1160,587.5) ,它是一般目标点, C 点和 D 点, F 点相连 C点和D点,F点相连 C点和D点,F点相连 完成以下问题:
-
画出上面的无向图,第一类目标点用 ⋆ \star ⋆ 表示,第二类目标点用*表示,一般目标点用‘.’这里要求画出无向图的度量图,即各个顶点的位置坐标必须准确(非拓扑图)
-
求顶点L到顶点M3的最短距离和最短路径,并画出最短路径
import networkx as nx import pylab as plt import math import numpy as np import pandas as pddata = pd.read_excel('Pex10_5.xlsx',keep_default_na=False) # 获取坐标构造pos x_site = data['x坐标'].tolist() y_site = data['y坐标'].tolist() d = len(x_site) position = zip(range(0, d), zip(x_site, y_site)) pos = dict(position) # 构造字典 nodes = data['顶点'].tolist() # 构造点的标签 matrix = pd.DataFrame(np.zeros((d, d)), index=nodes, columns=nodes) # 构造无向图的邻接矩阵 data1 = data.set_index('顶点') pos_alph = dict(zip(nodes, zip(x_site, y_site))) # 插寻点的坐标 f = lambda X, Y: np.round(np.sqrt((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2)) for i in nodes:if len(data1['相邻的顶点1'][i]) != 0:temp = data1['相邻的顶点1'][i]x1, y1 = pos_alph[i]x2, y2 = pos_alph[temp]matrix[i][temp] = f([x1, x2], [y1, y2]) # 修改为两点之间的距离if len(data1['相邻的顶点2'][i]) != 0:temp = data1['相邻的顶点2'][i]x1, y1 = pos_alph[i]x2, y2 = pos_alph[temp]matrix[i][temp] = f([x1, x2], [y1, y2]) # 修改为两点之间的距离x3, y3 = pos_alph['P3'] x4, y4 = pos_alph['G3'] x5, y5 = pos_alph['O3']matrix['P3']['G3'] = f([x3, x4], [y3, y4]) matrix['O3']['G3'] = f([x3, x5], [y3, y5]) mat = matrix.T.values # 转化为上三角矩阵G=nx.Graph(mat) w=nx.get_edge_attributes(G,'weight') #求最短距离 source=nodes.index('L');end=nodes.index('M3') dis=nx.shortest_path_length(G,source,end,weight='weight') print('L到M3的最短距离为:',dis) path=nx.shortest_path(G,source,end) print('L到M3的路径为:',path) path_edges=list(zip(path,path[1:])) #绘制最短路径 nx.draw(G,pos,node_size=100,node_color='blue',width=0.7,labels=dict(zip(range(d),nodes)),alpha=0.7,font_size=10) nx.draw_networkx_edge_labels(G,pos,edge_labels=w,font_size=4) nx.draw_networkx_edges(G,pos,edgelist=path_edges,edge_color='red',width=2) # 对应的点的标记修改 data2 = data.set_index('顶点类别') point1=data2['顶点'][1].tolist() point2=data2['顶点'][2].tolist() ind1=[nodes.index(i) for i in point1 if i in nodes] ind2=[nodes.index(i) for i in point2 if i in nodes] nx.draw_networkx_nodes(G,pos,nodelist=ind1,node_color='red',node_shape='*') nx.draw_networkx_nodes(G,pos,nodelist=ind2,node_color='red',node_shape='^') plt.show() #结果: #L到M3的最短距离为: 2613.0 #L到M3的路径为: [10, 9, 22, 14, 26, 27, 49, 80, 79, 89]

-
当边的权值为两点之间的距离时,求上面无向图的最小生成树,并画出最小生成树
import networkx as nx import pylab as plt import math import numpy as np import pandas as pddata = pd.read_excel('Pex10_5.xlsx',keep_default_na=False) # 获取坐标构造pos x_site = data['x坐标'].tolist() y_site = data['y坐标'].tolist() d = len(x_site) position = zip(range(0, d), zip(x_site, y_site)) pos = dict(position) # 构造字典 nodes = data['顶点'].tolist() # 构造点的标签 matrix = pd.DataFrame(np.zeros((d, d)), index=nodes, columns=nodes) # 构造无向图的邻接矩阵 data1 = data.set_index('顶点') pos_alph = dict(zip(nodes, zip(x_site, y_site))) # 插寻点的坐标 f = lambda X, Y: np.round(np.sqrt((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2)) print(pos_alph) print(data1) for i in nodes:if len(data1['相邻的顶点1'][i]) != 0:temp = data1['相邻的顶点1'][i]x1, y1 = pos_alph[i]x2, y2 = pos_alph[temp]matrix[i][temp] = f([x1, x2], [y1, y2]) # 修改为两点之间的距离if len(data1['相邻的顶点2'][i]) != 0:temp = data1['相邻的顶点2'][i]x1, y1 = pos_alph[i]x2, y2 = pos_alph[temp]matrix[i][temp] = f([x1, x2], [y1, y2]) # 修改为两点之间的距离x3, y3 = pos_alph['P3'] x4, y4 = pos_alph['G3'] x5, y5 = pos_alph['O3']matrix['P3']['G3'] = f([x3, x4], [y3, y4]) matrix['O3']['G3'] = f([x3, x5], [y3, y5]) mat = matrix.T.values # 转化为上三角矩阵G=nx.Graph(mat) T=nx.minimum_spanning_tree(G) w=nx.get_edge_attributes(T,'weight') nx.draw(T,pos=pos,labels=dict(zip(range(d), nodes)),node_size=100,font_size=9,node_color='green',width=0.7) nx.draw_networkx_edge_labels(T,pos,edge_labels=w,font_size='4') print(w) plt.show()

-
-
甲,乙两个煤矿分别生产煤500万吨,供应A,B,C三个电厂发电需要,各电厂用量分别为300,300,400(万吨)。已知煤矿之间,煤矿与电厂之间以及各电厂之间相互距离(单位:km)如表10.5,表10.6,表10.7所示。煤可以直接运达,也可以经转运抵达,试确定从煤矿到各电厂间煤的最优调运方案。
甲 乙 甲 0 120 乙 100 0 A B C 甲 150 120 80 乙 60 160 40 A B C A 0 70 100 B 50 0 120 C 100 150 0 参考:2012年数学建模集训小题目 - 豆丁网 (docin.com)
-
考虑为线性规划问题+图论问题:
- 求解出在最短路约束下的分配情况
-
求解最短路:顶点集为 V = { v 1 , v 2 , v 3 , v 4 , v 5 } V=\{v_1,v_2,v_3,v_4,v_5\} V={v1,v2,v3,v4,v5} (甲,乙,A,B,C)边集为相应的路径(权重)
import networkx as nx import pylab as plt import numpy as np import pandas as pd def floyd(graph):m = len(graph)dis = graphpath = np.zeros((m, m)) # 路由矩阵初始化for k in range(m):for i in range(m):for j in range(m):if dis[i][k] + dis[k][j] < dis[i][j]:dis[i][j] = dis[i][k] + dis[k][j]path[i][j] = k#更新先驱点return dis, path plt.rcParams['font.sans-serif']=['SimHei'] inf=np.infif __name__ == "__main__":W=np.array([[0,120,150,120,80],[100,0,60,160,40],[inf,inf,0,70,100],[inf,inf,50,0,120],[inf,inf,100,150,0]])nodes=list('甲乙ABC')edges=[(i,j,W[i-1,j-1])for i in range(1,6)for j in range (1,6) ]edge=edges.copy()for i in edges:if i[2]==inf or i[2]==0:edge.remove(i)G=nx.DiGraph()for k in range(len(edge)):G.add_edge(edge[k][0]-1,edge[k][1]-1,weight=edge[k][2])w=nx.get_edge_attributes(G,'weight')nx.draw(G,pos=nx.shell_layout(G),labels=dict(zip(range(5),nodes)),node_color='red')nx.draw_networkx_edge_labels(G,nx.shell_layout(G),edge_labels=w)plt.show()dis,path=floyd(W)#dis 为最短距离矩阵mat=dis[0:2,2:]#切片处理table=pd.DataFrame(mat,columns=list('ABC'),index=['甲','乙'])print(table.to_markdown())#转化为markdown格式

-
最短距离:
A B C 甲 150 120 80 乙 60 130 40 -
线性规划:
- x i j x_{ij} xij:第 i i i个煤矿到第 j j j个电厂的调运量
- c i j c_{ij} cij:第 i i i个煤矿到第 j j j个电厂的最短距离
- b j b_{j} bj:第 j j j个电厂的需求量
- a i a_{i} ai:第 i i i个煤矿的产量
- 目标函数:总吨公里数(吨数 × \times ×公里数)
- 约束条件:
- 产量约束
- 需求量约束
-
线性规划模型如下:
m i n z = ∑ i = 1 2 ∑ j = 3 3 c i j x i j s . t . { ∑ j = 1 3 x i j = a i , i = 1 , 2 ∑ i = 1 2 x i j = b j , j = 1 , 2 , 3 x i j ≥ 0 , i = 1 , 2 ; j = 1 , 2 , 3 min~~z=\sum_{i=1}^2\sum_{j=3}^3c_{ij}x_{ij}\\s.t. \left\{ \begin{aligned} &\sum_{j=1}^3x_{ij}=a_i,i=1,2\\ &\sum_{i=1}^2x_{ij}=b_j,j=1,2,3\\ &x_{ij}\ge0,i=1,2;j=1,2,3 \end{aligned} \right. min z=i=1∑2j=3∑3cijxijs.t.⎩ ⎨ ⎧j=1∑3xij=ai,i=1,2i=1∑2xij=bj,j=1,2,3xij≥0,i=1,2;j=1,2,3 -
LNGO:
sets: fac/1..2/:a; plant/1..3/:b; coo(fac,plant):x,c;endsetsdata: a=500,500; b=300,300,400; c=150,120,80,60,130,40; enddata min=@sum(coo(i,j):c(i,j)*x(i,j)); @for(fac(i):@sum(plant(j):x(i,j))=a(i)); @for(plant(j):@sum(fac(i):x(i,j))=b(j));Objective value: 78000.00X( 1, 1) 0.00000 X( 1, 2) 300.0000 X( 1, 3) 200.0000 X( 2, 1) 300.0000 X( 2, 2) 0.000000 X( 2, 3) 200.0000所以应该从甲地运往B地300万吨,C地200万吨;从乙地运往A地300 万吨,C地200万吨
-
-
10.7 图10.23 给出了6支球队的比赛结果,即1队战胜2,4,5,6对,而输给了3队;5队战胜3,6队,而输给1,2,4队;等等

-
利用竞赛图的适当方法,给出6支球队的一个排名顺序(竞赛图必存在哈密顿圈(不一定回到起始点))参考:《数学模型》(第五版)循环比赛问题
- 如果可以找到唯一的一条完全路径,则由它经过的顶点的顺序即为排名顺序
- 如果存在多条路径:
- 双向连通图:接连矩阵的最大特征值对应的特征向量 → \rightarrow → 排名顺序
- 非双向连通图:无法确定所有队的排名
- 如图所示已经存在以下两条完全路径:排除第一种情况
- 3-1-2-4-5-6
- 1-2-5-3-4-6
-
利用PageRank 算法,再次给出6支球队的排名顺序
import networkx as nx import pylab as plt import numpy as np from scipy.sparse.linalg import eigs# 绘制有向图 def floyd(graph):m = len(graph)dis = graphpath = np.zeros((m, m)) # 路由矩阵初始化for k in range(m):for i in range(m):for j in range(m):if dis[i][k] + dis[k][j] < dis[i][j]:dis[i][j] = dis[i][k] + dis[k][j]path[i][j] = k # 更新先驱点return dis, pathif __name__ == '__main__':L = [(1, 2), (1, 4), (1, 5), (1, 6), (2, 4), (2, 6), (2, 5), (3, 1), (3, 2), (3, 4), (4, 5), (4, 6), (5, 3), (5, 6),(6, 3)]G = nx.DiGraph()G.add_nodes_from(range(1, 7))G.add_edges_from(L)matrix = np.array(nx.to_numpy_matrix(G)) # 接连矩阵pos = nx.shell_layout(G)nx.draw(G, pos, node_size=250, font_weight='bold', node_color='red', with_labels=True, arrowsize=17, width=0.5,alpha=0.6)A1 = matrix.copy()A1[A1 == 0] = np.infdis, path = floyd(A1);print(dis) # 可以看出竞赛图是双向连通图# 竞赛图算法w, v = np.linalg.eig(matrix)print(v[:, 0].argsort()) # 1->3->2->5->4->6 排名顺序# PageRank 算法A2 = matrix / np.tile(matrix.sum(axis=1, keepdims=True), (1, matrix.shape[1])) # tile 扩展行和A2 = 0.15 / matrix.shape[0] + 0.85 * A2 # 构造状态转移矩阵W, V = eigs(A2.T, 1) # 特征值为1时的特征向量V = V.real;V = V.flatten() # 展开成一维数组V = V / V.sum() # 向量归一化# 绘制柱状图plt.figure(2)plt.bar(range(1, matrix.shape[0] + 1), V, width=0.7, color='b')plt.show() #排名为:1->2-> 5-> 4-> 6-> 3
- 计算如图10.24所示网络的度分布,网络直径,平均路径长度,各节点的聚类系数和整个网络的聚类系数

import networkx as nx
import pylab as pltL = [(1, 2), (1, 5), (2, 4), (2, 3), (2, 5),(3, 5), (3, 4), (5, 6)]
G = nx.Graph() # 构造无向图
G.add_nodes_from(range(1, 7)) # 添加顶点集
G.add_edges_from(L)
D = nx.diameter(G) # 求网络直径
LH = nx.average_shortest_path_length(G) # 求平均路径长度
Ci = nx.clustering(G) # 求各顶点的聚类系数
C = nx.average_clustering(G) # 求整个网络的聚类系数
print("网络直径为:", D, "\n平均路径长度为:", LH)
print("各顶点的聚类系数为:")
for index, value in enumerate(Ci.values()):print("(顶点v{:d}: {:.4f});".format(index + 1, value), end=' ')
print("\n整个网络的聚类系数为:{:.4f}".format(C))
nx.draw(G, pos=nx.shell_layout(G), with_labels=True)
plt.show()# 网络直径为: 3
# 平均路径长度为: 1.5333333333333334
# 各顶点的聚类系数为:
# (顶点v1: 1.0000); (顶点v2: 0.5000); (顶点v3: 0.6667); (顶点v4: 1.0000); (顶点v5: 0.3333); (顶点v6: 0.0000);
# 整个网络的聚类系数为:0.5833