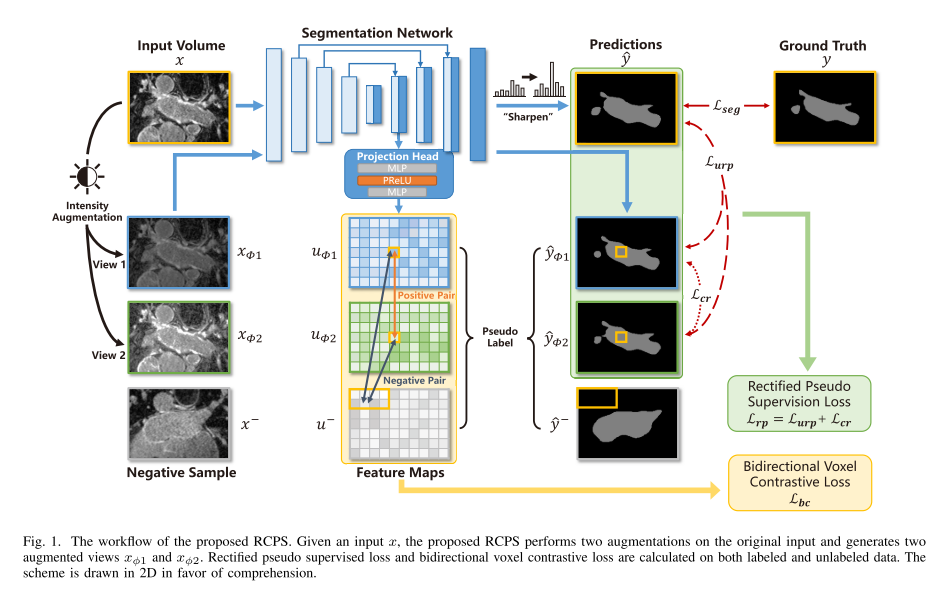
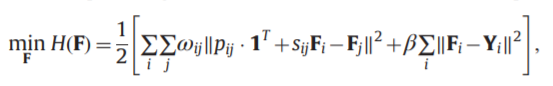半监督学习
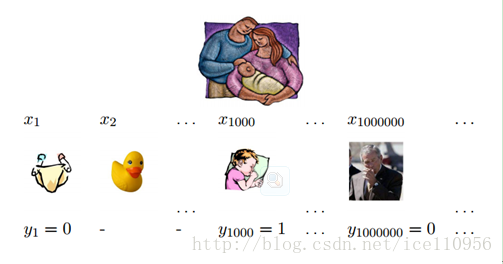
Positive-unlabeled learning
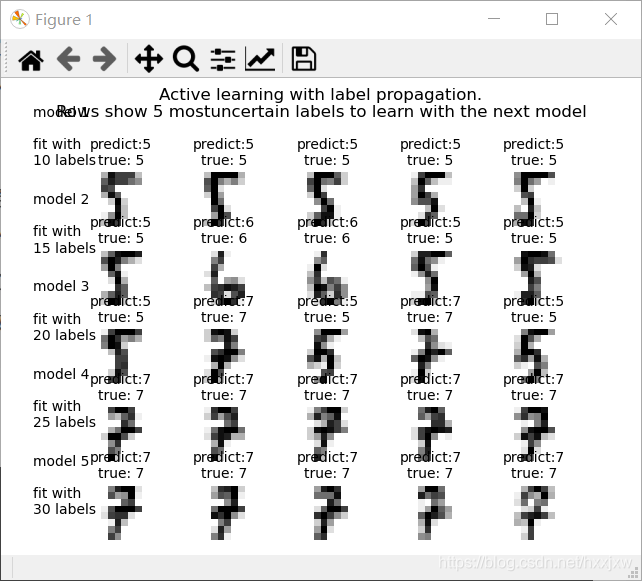
什么是半监督学习
让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习(semi-supervised learning)。
要利用未标记样本,必然要做一些将未标记样本所揭示的数据分布信息与类别标记相联系的假设。假设的本质是“相似的样本拥有相似的输出”。
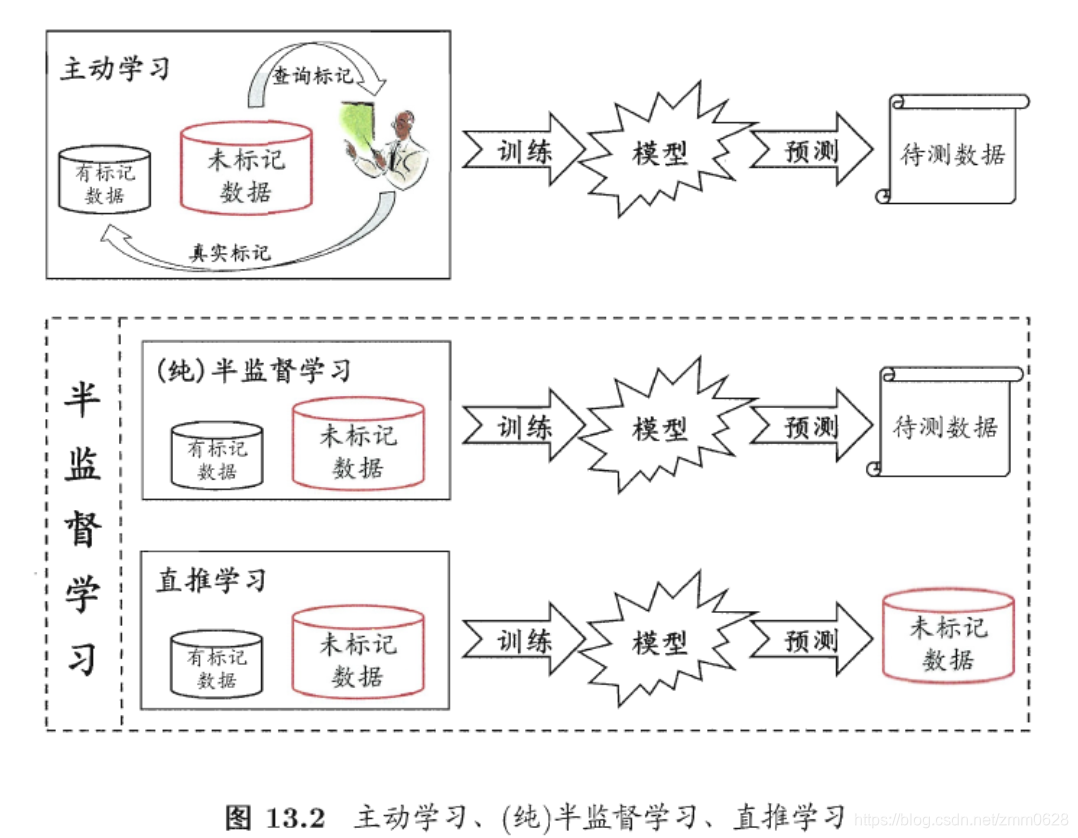
半监督学习可进一步划分为纯(pure)半监督学习和直推学习(transductive learning),前者假定训练数据中的未标记样本并非待测的数据,
而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。
1-2、无标记样本的意义
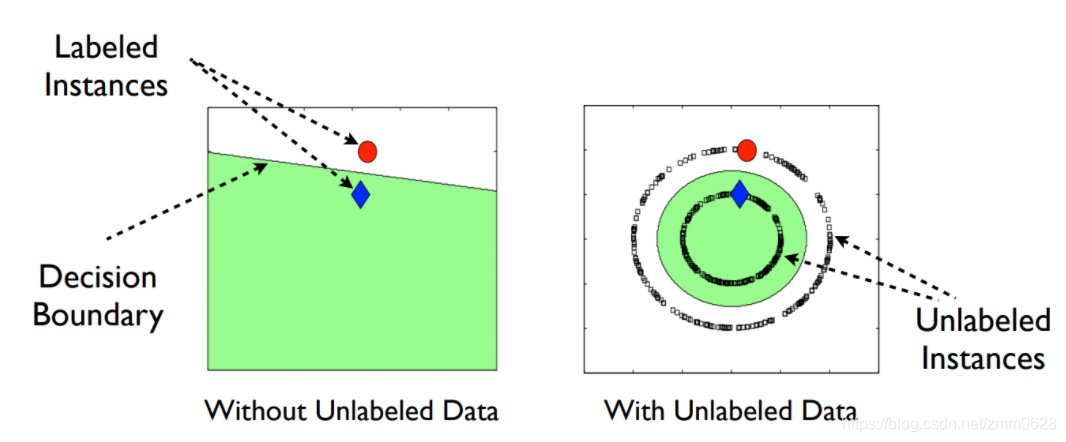
左图表示根据现有的数据,我们得到的分类边界如左图中蓝线所示。但是当我们有了无标签数据的分布信息后,两个类的分类超平面就变得比较明确了。
因此,使用无标签数据有着提高分类边界的准确性,提高模型的稳健性。
1-3、伪标签(Pseudo-Labelling)学习
伪标签学习也可以叫简单自训练(simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,
这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
上图反映的便是简单的伪标签学习的过程,具体描述如下:
i)使用有标签数据训练模型;
ii)使用训练的模型为无标签的数据预测标签,即获得无标签数据的伪标签;
iii)使用(ii)获得的伪标签和标签数据集重新训练模型;
最终的模型是(iii)训练得到,用于对测试数据的最终预测。
伪标签方法在实际的使用过程中,会在(iii)步中增加一个参数:采样比例(sample_rate),表示无标签数据中本用作伪标签样本的比率。
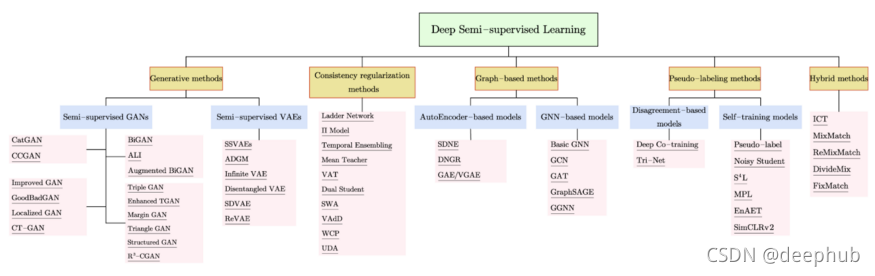
一般,半监督学习算法可分为:self-training(自训练算法)、Graph-based Semi-supervised Learning(基于图的半监督算法)、Semi-supervised supported vector machine(半监督支持向量机,S3VM)。简单介绍如下:
1.简单自训练(simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器。
2.协同训练(co-training):其实也是 self-training 的一种,但其思想是好的。假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。
3.半监督字典学习:其实也是 self-training 的一种,先是用有标签数据作为字典,对无标签数据进行分类,挑选出你认为分类正确的无标签样本,加入字典中(此时的字典就变成了半监督字典了)
4.标签传播算法(Label Propagation Algorithm):是一种基于图的半监督算法,通过构造图结构(数据点为顶点,点之间的相似性为边)来寻找训练数据中有标签数据和无标签数据的关系。是的,只是训练数据中,这是一种直推式的半监督算法,即只对训练集中的无标签数据进行分类,这其实感觉很像一个有监督分类算法…,但其实并不是,因为其标签传播的过程,会流经无标签数据,即有些无标签数据的标签的信息,是从另一些无标签数据中流过来的,这就用到了无标签数据之间的联系
5.半监督支持向量机:监督支持向量机是利用了结构风险最小化来分类的,半监督支持向量机还用上了无标签数据的空间分布信息,即决策超平面应该与无标签数据的分布一致(应该经过无标签数据密度低的地方)(这其实是一种假设,不满足的话这种无标签数据的空间分布信息会误导决策超平面,导致性能比只用有标签数据时还差)
其实,半监督学习的方法大都建立在对数据的某种假设上,只有满足这些假设,半监督算法才能有性能的保证,这也是限制了半监督学习应用的一大障碍。
**
半监督深度学习
**
终于来到正题——半监督深度学习,深度学习需要用到大量有标签数据,即使在大数据时代,干净能用的有标签数据也是不多的,由此引发深度学习与半监督学习的结合。
如果要给半监督深度学习下个定义,大概就是,在有标签数据+无标签数据混合成的训练数据中使用的深度学习算法吧…orz.
半监督深度学习算法个人总结为三类:无标签数据预训练网络后有标签数据微调(fine-tune);有标签数据训练网络,利用从网络中得到的深度特征来做半监督算法;让网络 work in semi-supervised fashion。
1.无标签数据预训练,有标签数据微调
对于神经网络来说,一个好的初始化可以使得结果更稳定,迭代次数更少。因此如何利用无标签数据让网络有一个好的初始化就成为一个研究点了。
目前我见过的初始化方式有两种:无监督预训练,和伪有监督预训练
无监督预训练:一是用所有数据逐层重构预训练,对网络的每一层,都做重构自编码,得到参数后用有标签数据微调;二是用所有数据训练重构自编码网络,然后把自编码网络的参数,作为初始参数,用有标签数据微调。
伪有监督预训练:通过某种方式/算法(如半监督算法,聚类算法等),给无标签数据附上伪标签信息,先用这些伪标签信息来预训练网络,然后在用有标签数据来微调。
2.利用从网络得到的深度特征来做半监督算法
神经网络不是需要有标签数据吗?我给你造一些有标签数据出来!这就是第二类的思想了,相当于一种间接的 self-training 吧。一般流程是:
先用有标签数据训练网络(此时网络一般过拟合…),从该网络中提取所有数据的特征,以这些特征来用某种分类算法对无标签数据进行分类,挑选你认为分类正确的无标签数据加入到训练集,再训练网络;如此循环。
由于网络得到新的数据(挑选出来分类后的无标签数据)会更新提升,使得后续提出来的特征更好,后面对无标签数据分类就更精确,挑选后加入到训练集中又继续提升网络,感觉想法很好,但总有哪里不对…orz
个人猜测这个想法不能很好地 work 的原因可能是噪声,你挑选加入到训练无标签数据一般都带有标签噪声(就是某些无标签数据被分类错误),这种噪声会误导网络且被网络学习记忆。
参考文献
https://zhuanlan.zhihu.com/p/33196506
https://www.cnblogs.com/kamekin/p/9683162.html