目录
前言
传统常见的
Free Lunch for Few-shot Learning: Distribution Calibration
Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
NER任务数据增强
(1)An Analysis of Simple Data Augmentation for Named Entity Recognition
(2)Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
前言
有许多场景,我们只有少量样本,而训练网络模型时是需要吃大量数据的,一般来说解决的方法是:
- 利用VAEs(variational auto encoders )变分自编码重构句子,通过学习重构句子的隐藏变量预测句子的标签, 论文是(Chen et al., 2018; Yang et al., 2017; Gururanganet al., 2019)
- 通过self-training使模型对无标签的数据输出预测的置信度, 论文Lee, 2013; Grandvalet and Bengio,2004; Meng et al., 2018)
- 通过添加对抗噪声或数据增强然后进行一致性训练, (Miy-ato et al., 2019, 2017) ( (Xieet al., 2019)
- 使用大规模无标签数据进行预训练,然后使用有标签数据微调, (Devlinet al., 2019).
关于第4点就是目前比较火的以bert为代表的预训练模型,关于预训练的一些当前研究进展,可以看笔者另外一篇
预训练模型的那些方向和研究成果_爱吃火锅的博客-CSDN博客
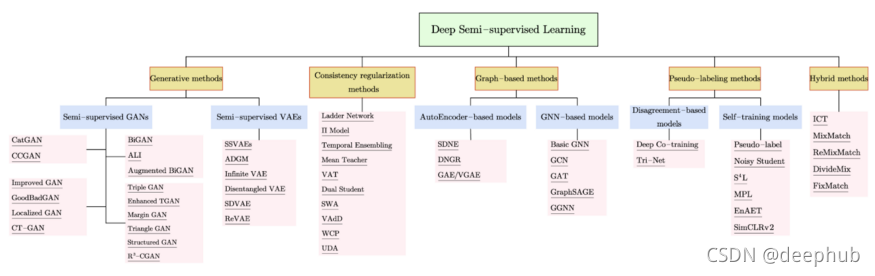
其实总结一下就是半监督学习一般有两个方法一致性正则和打伪标签法即 consistency regularization 和 pseudo-label, 其中一致性正则主要是基于数据增强的一致性正则,目前比较成熟
关于打伪标签法笔者另一篇博客
《半监督之伪标签法》:半监督之伪标签法_爱吃火锅的博客-CSDN博客
本篇这里主要说说基于数据增强这一分支,下面首先介绍一些比较传统的,然后接着介绍一些截止目前(2021.2.6)最新的论文idea。都比较有意思,很有想法,哈哈。一起学习一下吧。
关于NLP领域数据增强的一些总结:
NLP提效,除了选择合适的模型,就是数据增强了
哈工大|NLP数据增强方法?我有15种
传统常见的
比如对于文本数据来说,最容易的就是shuffle, drop, 同义词替换,回译,随机插入,等等,这些都是一些最基本的方法,依据token 在本身上面做些扰动改变来数据增加,更多的可以看一下nlpcda这个python包
https://github.com/425776024/nlpcda
同时来自EMNLP2021的一篇论文:AEDA
论文地址:https://arxiv.org/pdf/2108.13230.pdf
代码地址:https://github.com/akkarimi/aeda_nlp
主要方法就是随机插入一些标点符号,感兴趣的可以看看。
对于图像来说就是旋转、平移、裁剪等等。
总结一下为:图片来源于JayJay:打开你的脑洞:NER如何进行数据增强 ? - 知乎
JayJay大家知乎可以关注一下,写的文章都挺好的。

Free Lunch for Few-shot Learning: Distribution Calibration
发表于2021 ICLR的一篇论文,有代码
论文:https://arxiv.org/pdf/2101.06395.pdf
作者本人解读:ICLR2021 Oral |利用一个样本估计类别数据分布 9行代码提高少样本学习泛化能力 - 知乎
一些代码解读:[论文笔记]一个样本就能估计新类数据分布? - 知乎
其中的N-way K-shot任务,可以参考
小样本学习之N-way K-shot - 知乎
一篇就够!数据增强方法综述
其主要思路就是:先在整体数据集(大的数据集)上面统计每一个类的均值base_mean和协方差base_cov(假设有10个类,那就是10对均值和协方差),然后在生成的时候,对于每一个类的每一个样本,计算它和10个类的均值的差值,选取最接近的的k个(自己设置的一个参数,比如2),这样就选出两个均值和协方差,然后当前这个样本的均值就更新为这个样本的+选出的两个样本均值一共三个,对这三个取均值作为新的均值,方差是选出这两个协方差的均值,这样就得到当前这个样本更正后的均值和方差,依次构建一个高斯分布,然后从这个分布中抽取m个样本(就是生产m个样本吧),假设小样本是20个,那么扩充完后就是20*m个啦,而且这新生成的20*m个样本是根据数据分布来生成的。
需注意,这里用到一个大的前提就是base_mean和base_cov,这个是大数据的先验知识,如果没有一些基数据分布供我们统计,就单单凭借一个小样本其实是生成不了数据集的,我们用的先验知识就是大数据集上面的统计量,具体到这里就是均值和方差
这里笔者在isir数据集上面简单做了一个实验:

每一个颜色代表一个类别,一共3类,五角星代表小样本,每个类我们取5个,用这5个来生成数据,圆圈就是真实的数据,每个类50个真实样本,三角形是生成的样本每个样本(即五角星)生成10个,一共生成3*5*10=150个样本。
全部代码:
import pandas as pd
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.manifold import TSNEdef load_iris_dataset():iris=datasets.load_iris()feature = iris.datadataset = pd.DataFrame(feature)dataset.columns = iris.feature_namesdataset["label"] = iris.targetreturn dataset, iris.feature_namesdef distribution_calibration(query, base_means, base_cov, k, alpha=0.5):dist = []for i in range(len(base_means)):dist.append(np.linalg.norm(query-base_means[i]))index = np.argpartition(dist, k)[:k]mean = np.concatenate([np.array(base_means)[index], query[np.newaxis, :]])calibrated_mean = np.mean(mean, axis=0)calibrated_cov = np.mean(np.array(base_cov)[index], axis=0)+alphareturn calibrated_mean, calibrated_covdef get_min_sample(dataset, feature_name): base_means = []base_cov = []df_group = dataset.groupby("label")print(" label num :" + str(len(df_group)))result = pd.DataFrame(columns=feature_name+["label"])for label, df in df_group:#抽取少量的一部分样本, 10%的比例df_temp = df.sample(frac=0.1,axis=0)result = result.append(df_temp, ignore_index=True)feature = df[feature_name].valuesmean = np.mean(feature, axis=0)cov = np.cov(feature.T)base_means.append(mean)base_cov.append(cov)return result, base_means, base_covdef generate_dataset(result, base_means, base_cov, feature_name, num_sampled = 10, return_origion=False):df_group = result.groupby("label")sampled_data = []sampled_label = []sample_num = result.shape[0]feature = result[feature_name].valueslabel = result["label"].valuesfor i in range(sample_num):mean, cov = distribution_calibration(feature[i], base_means, base_cov, k=1)sampled_data.append(np.random.multivariate_normal(mean=mean, cov=cov, size=num_sampled))sampled_label.extend([label[i]]*num_sampled)sampled_data = np.concatenate([sampled_data[:]]).reshape(result.shape[0] * num_sampled, -1)result_aug = pd.DataFrame(sampled_data)result_aug.columns = feature_nameresult_aug["label"] = sampled_labelif return_origion:result_aug = result_aug.append(result, ignore_index=True)'''#返回包括Support setif return_origion:result_aug = pd.DataFrame(columns=iris.feature_names+["label"])for label, df in df_group:feature = df[iris.feature_names].valueslabel = df["label"].valuesnum = feature.shape[0]for i in range(num):mean, cov = distribution_calibration(feature[i], base_means, base_cov, k=2)sampled_data.append(np.random.multivariate_normal(mean=mean, cov=cov, size=num_sampled))sampled_label.extend([label[i]]*num_sampled)sampled_data = np.concatenate([sampled_data[:]]).reshape(num * num_sampled, -1)X_aug = np.concatenate([feature, sampled_data])Y_aug = np.concatenate([label, sampled_label])df_aug = pd.DataFrame(X_aug)df_aug.columns = iris.feature_namesdf_aug["label"] = Y_augresult_aug = result_aug.append(df_aug, ignore_index=True)else:#返回不包括Support setsampled_data = []sampled_label = []for label, df in df_group:feature = df[iris.feature_names].valueslabel = df["label"].valuesnum = feature.shape[0]for i in range(num):mean, cov = distribution_calibration(feature[i], base_means, base_cov, k=2)sampled_data.append(np.random.multivariate_normal(mean=mean, cov=cov, size=num_sampled))sampled_label.extend([label[i]]*num_sampled) sampled_data = np.concatenate([sampled_data[:]]).reshape(result.shape[0] * num_sampled, -1)result_aug = pd.DataFrame(sampled_data)result_aug.columns = iris.feature_namesresult_aug["label"] = sampled_label '''return result_augdef Visualise(base_class_dataset, result, result_aug, feature_name):dataset = base_class_dataset.append(result)dataset = dataset.append(result_aug)feature = dataset[feature_name].valueslabel = dataset.label.valueslabel_map = {"0":'red', "1":'black', "2":'peru'}transform = TSNE # PCAtrans = transform(n_components=2)feature= trans.fit_transform(feature)base_class_dataset_feature = feature[:base_class_dataset.shape[0]]result_feature = feature[base_class_dataset.shape[0]:base_class_dataset.shape[0]+result.shape[0]]result_aug_feature = feature[base_class_dataset.shape[0]+result.shape[0]:]base_class_dataset_label = label[:base_class_dataset.shape[0]]base_class_dataset_label_colours = [label_map[str(target)] for target in base_class_dataset_label]result_label = label[base_class_dataset.shape[0]:base_class_dataset.shape[0]+result.shape[0]]result_label_colours = [label_map[str(target)] for target in result_label]result_aug_label = label[base_class_dataset.shape[0]+result.shape[0]:]result_aug_label_colours = [label_map[str(target)] for target in result_aug_label]plt.figure(figsize=(20, 15))plt.axes().set(aspect="equal")plt.scatter(base_class_dataset_feature[:, 0], base_class_dataset_feature[:, 1], c=base_class_dataset_label_colours, marker='o', s=100)plt.scatter(result_aug_feature[:, 0], result_aug_feature[:, 1], c= result_aug_label_colours, marker='^', s=100)plt.scatter(result_feature[:, 0], result_feature[:, 1], c=result_label_colours, marker='*', s=800)plt.title("{} visualization of node embeddings".format("All_class"))#plt.savefig("AllNode.png")plt.show()for i in label_map:print(label_map[i])print(i)print("*********************************")def main():#获取iris原数据集base_class_dataset, feature_name =load_iris_dataset()print(base_class_dataset.shape)print("******"*5)print(base_class_dataset.head(3))#获取数据分布统计量, 参数k和alpha就是超参, k和类别数有关,如果总类别数(num_label)多,这个#可以调大一点,总之k<num_labelresult, base_means, base_cov = get_min_sample(base_class_dataset, feature_name)#生成数据,result_aug = generate_dataset(result, base_means, base_cov, feature_name, num_sampled = 10)print(result.shape)print(result_aug.shape)#可视化Visualise(base_class_dataset, result, result_aug, feature_name)if __name__=='__main__':main()总结一下:
主要利用的理论依据就是大数据基类的均值和方差这两个统计量,给我们的启示就是或许我们可以找到基类更好的分布统计量来辅助我们生产数据,但该方法也有弊端吧,那就是假如没有大数据基类或者面对跨域Cross Domain问题就恐怕不行了。这里没有涉及到模型的优化,只是单纯的数据增强方面的idea。
Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
这是发表在AAAI2021的一篇论文。有代码,正在整理,后续会开源,笔者也在期待中,因为看效果很好。
论文:https://arxiv.org/pdf/2101.08106.pdf
该论文的背景是解决bert蒸馏的,但是也是小样本的场景,为此希望通过数据增加来达到目的。

teacher model和student model就是bert知识蒸馏的模块,不再累述,不是重点。
这里的Generator就是数据生成器,就是数据增强的,这里其实也不是重点,我们可以理解为他就是生成一批一批数据,甚至我们可以用我们上面讲的传统方法来生成,当然啦论文中用的不是这么low哦,用的大概是这样的:
随机选一个长度,即一个位置,然后替换该词,用什么词替换呢?就是用bert的预测结果来提换

Reinforced selector就是使用强化学习模型的一个数据选择器,这个是全文的核心idea,它的基本思路就是,我们生成的样本不一定都是高质量的,我们要通过selector来选出高质量的参与训练,或者用论文的话就是这个selector会指导generator生成的数据越来越高质量。那怎么动态指导呢?那就是强化学习,具体到这里:

对应到强化学习中的几个关键术语
state : 模型的输出,具体到这里就是teacher和student model的输出
action : 就是0和1,即选与不选
reward: 选择这个样本和不选择这个样本前后在验证集上面评价的变化,变大了,reward就大。
效果:

L2A就是论文的方法,效果可以说很好啦。
作者还探究了一下,模型在越小的样本上面效果越明显

可以看到,在很小样本量的时候,甚至可以超过teacher模型啦。
总结一下:
该论文的核心就是利用这个强化学习,去动态的调整生成器的策略,他调整的依据就是验证集指标是否提高(直接和我们想要提高的指标挂钩),这里可以看到该方法是不需要像上篇论文那样有一个天然基类的大数据的,非要对比这两篇文章方法的话,第一篇其实是通过<一次性>利用 “基类的统计量” 去监督生成数据,而该篇是通过 “结果指标”去<动态>监督生成数据,当我们有一个基类大数据的话,我们甚至可以结合两篇论文,即生成器生成数据的时候就用“基类的统计量” 去生成一批数据,然后再用“结果指标”去<动态>监督指导生成器。
该篇论文给我们的一个思路就是,我们的模型可以各种变变变(这里的场景是bert蒸馏,我们的自己的可以是文本分类啊,阅读理解啊啥的),但是要用强化学习去监督(直接用我们想要提升的指标)生成伪数据即:
强化学习通过指标reward监督生成器生成伪数据。
这里其实怎么数据增强不是它的创新点,核心创新点是筛选生成的数据。
再说的大一点就是解决动态更新问题的话记得想一想:
强化学习方法
MixText: Linguistically-Informed Interpolation of Hidden Space for Semi-Supervised Text Classification
这是发表在ACL2020的一篇论文,使用TMix的数据增强方法,思想的起因其实是图像领域的Mixup的数据增强方式。关于该篇论文网上已有很多解读如下,这里就简单总结一下吧。
论文:https://arxiv.org/pdf/2004.12239.pdf
英文代码:https://github.com/GT-SALT/MixText
一些中文解读博客:
NLP之MixText 半监督文本分类(2020年4月论文解读) - 知乎
不要浪费没有标注的数据!超强文本半监督方法MixText来袭!
适用到中文上的代码解读:
NLP之MixText 半监督文本分类(中文实现代码) - 知乎
中文代码:
https://github.com/johnson7788/MixText
想要跑的话,可以参考上述中文代码,有着注释,可快熟熟悉。
这里主要总结一下:
首先Tmix的主要思想:类似图片的Mixup数据增强算法,图片的Mixup数据增强算法是给定2个打了标签的点(xi,yi)and(xj,yj),其中x是图片,y是one-hot过的标签,算法是通过创建虚拟的训练集通过线性插入的方法:

注意:这里的新标签其实是一种混合了两种图片的标签,假如原始的两种图片一个是狗,一个是猫,当
那其实这种图片就是一半是狗一半是猫,那么
的标签就是[0.5,0.5]
基于这个思想,引入到文本的话,文本本身没有办法插入,那么就在隐藏层插入,模型如下:

同时之前的方法都是把标签数据和无标签数据分开训练,这里是联合糅在一起训练,具体的就是分三步:
第一步:对无标签数据进行数据增强生成对应的增加数据
,论文中采用的增强方式是回译方式,这里其实不是最重要的创新点,甚至这里可以使用各种文本增强的方法生成
。
第二步:对未标注的数据进行标签预测,这里采用的是平均加权的方式

可以看到假设原始有一个样本x1, 通过数据增强产生的是x1_1 , x1_2, x1_3 ,那么四个样本进入到bert分类模型后会有四个标签预测结果,那么对这四个预测结果有权求和取平均得到最后的标签作为这个四个样本的统一标签。注意,这里的和
不是什么学习参数,就是人为设定的,其实就是要看生成的增强文本质量高不高,高的话其预测标签偏重也要高一点。
第三步:
此时用少量有标签数据和大量无标签数据,增强的无标签数据(其实此时通过第二步也有标签了,但是这个标签可不是但一个类即【0,1,0】,可能是【0.2,0.4,0.4】)进行Tmix
即将有标签数据、大量无标签数据和增强的无标签数据组成一个新的数据集,然后每次从中选两个x和进行Tmix。然后loss就是KL散度。

这里有一点点疑惑,首先论文中说当x来源于有标签数据时,这个时候的loss就是有监督loss,当来源于大量无标签数据或者增强的无标签数据时这是后就用kL散度。
代码中也进行了区分

我理解两则都是一样的吧,为啥要进行区分计算呢?关于x和假设一个来源于有标签一个来源于无标签的进行的Tmix,和两个都来源于有标签的样本,看代码来说都是425行计算。注意代码的

280-282行 ,idx1就是打乱的有标签数据,idx2就是无标签打断的数据。这还是分开有标签数据和无标签数据分开进行TMix
285-287行,idx1其实是在有标签和增强的无标签数据上面打乱的数据,idx2是无标签原始打乱数据。
总的合起来数据(有标签,无标签,无标签增强)是input_a
那么idx是idx1和idx2 cat的数据大小和input_a是一样的,只不过打乱的策略不同(就是上面说的两种)
然后input_a作为x,input_b作为进行Tmix。
注意这里的batch_size就是原始的有标签数据大小,batch_size_2是原始的无标签数据大小。
input_a的大小是[batch_size, batch_size_label, batch_size_u, batch_size_2],对应的是有标签数据,有标签数据增强大小(这个可选,这里假设在有标签数据上面也进行了增强),无标签数据增强大小,原始的无标签数据大小。
可以看到当采用280-282行时,有标签数据只和有标签数据Tmix,而采用285-287行时候,有标签数据是会和【有标签数据,增强的无标签数据】进行Tmix
看loss函数

outputs_x就是batch_size
outputs_u就是 batch_size_label, batch_size_u。
这里分开算两个两个loss的意义是什么呢?就算是有标签的loss,此时他的标签也是Tmix后的标签(不是属于某一个类的hard指标),直接算KL散度不就行了?
总结:
该篇论文将Tmix思想用到文本领域,对比前两篇的话,这里也用到了模型来做学习,即隐藏层的mix,并且在无标签数据集上面进行了标签预测,这个在开始的话可能不太准,但是是一个动态的过程,会越来越准,且最重要的是无标签和有标签进行Mix, 不是以往的分开利用,其实严格意义来讲,这篇论文和数据增强没有多少关系,即放到本博客来讲数据增强这一分支不是太合适,假设已有很大的一个无标签数据直接Tmix就行,该论文主要想说的就是Tmix的事,当然了,要进行Tmix那么无标签数据就必须有标签啊,所以就通过数据增强来生成一些样本,然后通过取平均来预估标签而不是单用一个(就是原始的),这样更准确一点,由此引出一点点数据增强,扯远了,主要idea还是Tmix, 总之也是一个不错的idea吧。
NER任务数据增强
NER的数据增强比较特殊,相比于sentence_level,它是token_level的,对局部更敏感,关于NER的增强,大家可以看
打开你的脑洞:NER如何进行数据增强 ? - 知乎
这里简单记录一下
(1)An Analysis of Simple Data Augmentation for Named Entity Recognition
论文:https://arxiv.org/pdf/2010.11683.pdf
这是一篇发表在COLING20的论文,其主要其实还是一些传统的方法,只不过贡献在于将这些传统的方法用到NER任务中,看看哪一个更有效。
大家直接看JayJay的知乎就可以啦,最主要的就是:

实验结论:

(2)Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
论文:DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks - ACL Anthology
这是发表在EMNLP20的一篇paper, 其是专门针对NER任务进行数据增强,怎么增强呢?很简单就是用一个语言模型去生成新样本,即训练一个生成器,其主要创新点在于怎么训练这个生成器,话句话说怎么构建生成器的训练样本,很简单,那就是 “标签线性化”。即

有了这个语言生成模型,就可以源源不断的产生新样本了,当然还可以利用大量无标签数据,如果有外部KB的话,通过匹配也可以得到有标签的数据,总之

效果呢,就是各种好吧
总结:
第一篇的传统的数据增强也可以用,有效果,第二篇的时候是训练一个数据生成器,是不是可以联合上篇阿里paper那个数据生成器,这里也用一个强化学习来保留淘汰数据生成器生成的样本的好还呢?当然啦这是一个联想啦,这篇paper的贡献idea就是标签线性化构建数据生成的训练样本。
更新
UDG
题目:Towards Zero-Label Language Learning
地址:https://arxiv.org/abs/2109.09193
解读:谷歌新大招UDG|直接生成训练数据送给你
主要创新就是改变了以往努力的点,以前都是根据x设计y,但是这篇paper是根据y生成x,主要应用的领域就是生成数据或者说数据增强,效果还是不错的
AllenAI | 用GPT-3帮助增建数据,NLI任务直接提升十个点!?
百篇论文分类整理看数据增广最新研究进展
ACL'22 | 快手+中科院提出一种数据增强方法:Text Smoothing,非常简单且有效尤其在数据不足的情况下
笔者github:
https://github.com/Mryangkaitong
看到很多小伙伴私信和关注,为了不迷路,欢迎大家关注笔者的微信公众号,会定期发一些关于NLP/ML的干活总结和实践心得,当然别的方向也会发,一起学习: