原问题是这样的:
给定一个DNA序列,这个系列只含有4个字母ATCG,如 S =“CTGTACTGTAT”。给定一个整数值k,从S的第一个位置开始,取一连续k个字母的短串,称之为k-mer(如k= 5,则此短串为CTGTA), 然后从S的第二个位置, 取另一k-mer(如k= 5,则此短串为TGTAC),这样直至S的末端,就得一个集合,包含全部k-mer 。 如对序列S来说,所有5-mer为{CTGTA,TGTAC,GTACT,TACTG,ACTGT,TGTAT}。
通常这些k-mer需一种数据索引方法,可被后面的操作快速访问。例如,对5-mer来说,当查询CTGTA,通过这种数据索引方法,可返回其在DNA序列S中的位置为{1,6}。
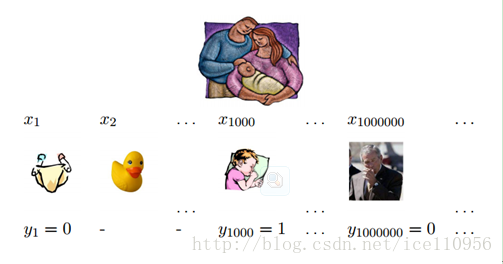
现在以文件形式给定 100万个 DNA序列,序列编号为1-1000000,每个基因序列长度为100 。
(1)要求对给定k, 给出并实现一种数据索引方法,可返回任意一个k-mer所在的DNA序列编号和相应序列中出现的位置。每次建立索引,只需支持一个k值即可,不需要支持全部k值。
(2)要求索引一旦建立,查询速度尽量快,所用内存尽量小。
(3)给出建立索引所用的计算复杂度,和空间复杂度分析。
(4)给出使用索引查询的计算复杂度,和空间复杂度分析。
(5)假设内存限制为8G,分析所设计索引方法所能支持的最大k值和相应数据查询效率。
(6)按重要性由高到低排列,将依据以下几点,来评价索引方法性能
l 索引查询速度
l 索引内存使用
l 8G内存下,所能支持的k值范围
l 建立索引时间
本题主要是有关DNA序列的k-mer index查找问题,可将其转化为字符串的查找匹配模型问题,在处理字符串查找问题上,现在得到广泛认可的算法有适合处理字符串单模匹配的KMP算法,BM算法,以及适合处理字符串多模匹配的AC算法,WM算法等等。我们队以hash算法为基础,并作了几点优化和改进,使算法的内存占用有了一定程度的降低,查找效率也有很大提高。
本文中的算法和其它大多数算法一样,在建立索引时采用了hash算法,不同的是,我们利用一个hash函数(将DNA序列中的ATCG分别用二进制位的00,01,10,11来表示),这样做不但把DNA序列映射为一个整数,便于存储与查找,而且可以减少内存的使用,在k值取值较大时减耗尤其明显。在解决hash函数的地址冲突时,我们采用了拉链法,并且采用多级链表的形式,这样在确保查询效率较高的情况下,同样也可以减少内存的使用。
由于我们将DNA序列的ATCG分别表示为00,01,10,11,则我们可以将任意一个k-mer串映射为一个十进制整数。
假如我们的k-mer串长度为5,DNA序列ATCGA,则出于二进制左高位右低位的表示习惯考虑,我们也按照从左到右的顺序表示。则转化后如图所示。

在使用hash算法时,我们不可避免会遇到地址冲突的情况,在该算法中我们采用拉链法解决地址冲突。
我们首先以hash 表的数组元素为链表的头结点,然后采用直接插入法插入到有序链表中,假如已经存在一个key值为781的结点,如图所示。

为了进一步提高查找效率,我们将key值相同的元素采用头插法插入到一个新的链表中。
假如我们又插入一个key值为228的结点,如图。

好了,废话少说了,现将源码附录如下:
#include <stdio.h>
#include <malloc.h>
#include <math.h>
#include <process.h>
#include <time.h>
#define M 14557
typedef struct seq
{
int value;
int num;
char index;
struct seq *next1;
struct seq *next2;
}*Seq,Sequence;
void initNode(Seq *r,int i)
{
if(*r==NULL)
{
*r=(Seq)malloc(sizeof(Sequence));
(*r)->next1=NULL;
(*r)->next2=NULL;
}
}
void addNode(Seq *r,int v,int n,int i)
{
Seq s=(*r)->next1;
Seq p=*r;
if(s)
{
while(s&&v>s->value)
{
p=s;
s=s->next1;
}
if(s&&v==s->value)
{
Seq qsub=(Seq)malloc(sizeof(Sequence));
qsub->value=v;
qsub->index=(char)i;
qsub->num=n;
qsub->next1=NULL;
qsub->next2=s->next2;
s->next2=qsub;
}
else
{
Seq q=(Seq)malloc(sizeof(Sequence));
q->next1=s;
q->value=v;
q->index=(char)i;
q->num=n;
q->next2=NULL;
p->next1=q;
}
}
else
{
Seq q=(Seq)malloc(sizeof(Sequence));
q->next1=s;
q->value=v;
q->index=(char)i;
q->num=n;
q->next2=NULL;
(*r)->next1=q;
}
}
void consultNode(Seq s,int v,int *count)
{
Seq r;
if(s)
r=s->next1;
while(r&&v>=r->value)
{
if(v==r->value)
{
(*count)++;
printf("%d,%d\n",r->num,r->index);
Seq q=r->next2;
while(q)
{
(*count)++;
printf("%d,%d\n",q->num,q->index);
q=q->next2;
}
}
r=r->next1;
}
}
int main(){
int k,j,i;
int num,n;
int m=0;
int pos=1;
char s[200];
Seq seqarray[M]={NULL};
printf("请输入k值:\n");
scanf("%d",&k);
FILE *fp;
if((fp=fopen("h.fa","r"))==NULL)
{
printf("File open error!\n");
exit(1);
}
long int start=clock();
while(!feof(fp))
{
fscanf(fp,"%*s%s%d%d",s,&num,&j);
fgetc(fp);
fgetc(fp);
j=0;
m=0;
pos=1;
for(i=0;i<k;i++) //A:00 T:01 C:10 G:11
{
//建立索引的时间与k值有关,当k值较大时,当hash选择的p值为合适的质数时,建立索引的时间明显缩短
switch(fgetc(fp))
{
case 'A':
j+=2;
break;
case 'T':
m+=(int)pow(2,j);
j+=2;
break;
case 'C':
j++;
m+=(int)pow(2,j);
j++;
break;
case 'G':
m+=(int)pow(2,j);
j++;
m+=(int)pow(2,j);
j++;
break;
default:
break;
}
}
n=m%M;
initNode(&seqarray[n],n);
addNode(&seqarray[n],m,num,pos);
pos++;
while(pos<=100-k)
{
j-=2;
m>>=2;
switch(fgetc(fp))
{
case 'A':
j+=2;
break;
case 'T':
m+=(int)pow(2,j);
j+=2;
break;
case 'C':
j++;
m+=(int)pow(2,j);
j++;
break;
case 'G':
m+=(int)pow(2,j);
j++;
m+=(int)pow(2,j);
j++;
break;
default:
break;
}
n=m%M;
initNode(&seqarray[n],n);
addNode(&seqarray[n],m,num,pos);
pos++;
}
fgets(s,50,fp);
}
/
getchar();
long int end=clock();
printf("*************建立索引%ldms*************\n",end-start); //计算建立索引时间
printf("请输入要查询的K串\n");
gets(s);
m=0;
j=0;
for(i=0;i<k;i++)
switch(s[i])
{
case 'A':
j+=2;
break;
case 'T':
m+=(int)pow(2,j);
j+=2;
break;
case 'C':
j++;
m+=(int)pow(2,j);
j++;
break;
case 'G':
m+=(int)pow(2,j);
j++;
m+=(int)pow(2,j);
j++;
break;
default:
break;
}
n=m%M;
int count=0;
long int start1=clock();
consultNode(seqarray[n],m,&count);
printf("*****查询到记录%d条*****\n",count);
long int end1=clock();
printf("*************查询时间%ldms*************\n",end1-start1); //计算查询时间
fclose(fp);
/
for(j=0;j<M;j++) //释放内存从前往后
if(seqarray[j])
{
Seq p=seqarray[j]->next1;
Seq q;
Seq q1,q2;
while(p)
{
q=p->next1;
q1=p->next2;
while(q1)
{
q2=q1->next2;
free(q1);
q1=q2;
}
free(p);
p=q;
}
free(seqarray[j]);
}
return 0;
}