2021年美国数学建模C题的数据处理
- C题数据分类存放部分
- 批量提取图像数据
- 转化jpg图像格式
C题数据分类存放部分
在拿到C题的数据后,避让要做的一个事情是图像数据的分类。根据2021MCM_ProblemC_ Images_by_GlobalID表格中,可以将图片和ID号对应起来,而ID号在2021MCMProblemC_DataSet表格中明确标识了Positive ID 、Negative ID、Unverified和Unprocessed。因此,在将类别跟ID对应起来后,就可以将数据进行分类,这里我是将图片划分到不同的文件夹中,使用的表格,是我将ID和Lab Status对应起来后的Images_by_GlobalID表格。
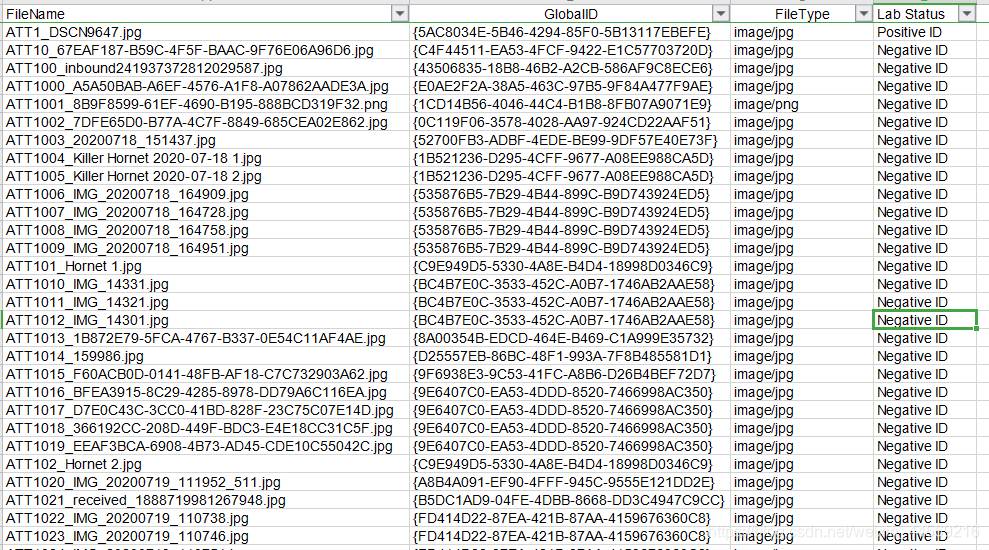
python代码如下
# 系统操作
import os
# 文件移动
import shutil
import cv2
import matplotlib.pyplot as plt
import numpy as np
import cv2
import pandas as pdname = "2021MCM_ProblemC_ Images_by_GlobalID.xlsx"
df = pd.read_excel(name,header = 0,engine='openpyxl')
dfdef remove(path, output):"""path:存放图像数据的文件夹路径output:将图像数据转移分类的目标路径"""pos = os.path.join(output, 'POS')neg = os.path.join(output, 'NEG')unp = os.path.join(output, 'UNP')unv = os.path.join(output, 'UNV')# 如果该文件夹不存在则创建文件夹if not os.path.exists(output):print("创建目标文件夹")os.makedirs(output)os.makedirs(pos)os.makedirs(neg)os.makedirs(unv)os.makedirs(unp)for i in range(listname.shape[0]):try:if listname.loc[i]["Lab Status"]=="Positive ID":print("找到正例")name = listname.loc[i]["FileName"]src = os.path.join(path, name)dst = os.path.join(pos, name)shutil.copyfile(src, dst)elif listname.loc[i]["Lab Status"]=="Negative ID":name = listname.loc[i]["FileName"]src = os.path.join(path, name)dst = os.path.join(neg, name)shutil.copyfile(src, dst)elif listname.loc[i]["Lab Status"]=="Unverified":name = listname.loc[i]["FileName"]src = os.path.join(path, name)dst = os.path.join(unv, name)shutil.copyfile(src, dst)elif listname.loc[i]["Lab Status"]=="Unprocessed":name = listname.loc[i]["FileName"]src = os.path.join(path, name)dst = os.path.join(unp, name)shutil.copyfile(src, dst)except IOError:print("获取文件异常")
remove(r"C:\Users\13086\Desktop\2021MCM_ProblemC_Files", "E:\jupyter文件\data")
最后得到的效果是,在我的目标路径中,创建了四个类别名称的文件夹,每个文件夹下存放着对应类别的图像数据。如下图
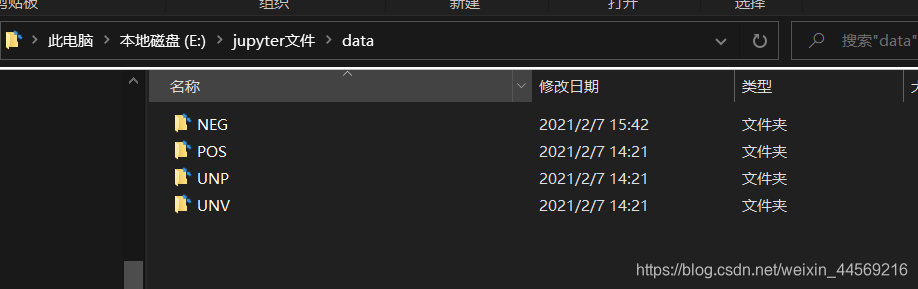
批量提取图像数据
将压缩包中的图片解压出来
import zipfile
def Unpack_zip(filepath, dir_path):"""参数:filepath:压缩包路径dir_path:解压目标路径函数作用:将压缩包解压目标路径并删除压缩包"""try:# open the zipextracting = zipfile.ZipFile(filepath)# 解压到路径extracting.extractall(dir_path)# close zipextracting.close()os.remove(filepath)except:name = os.path.split(filepath)[-1]print(name+" 文件提取异常, 文件路径为:"+filepath+ " 存储位置为:"+dir_path)
将pdf中的图片提取出来
import pdf2image
import tempfile
import os
def pdf2image2(file_path, dir_path):"""参数:file_path:pdf文件路径dir_path:图像保存路径作用:将pdf中的图像提取到目标路径中,并删除pdf文件"""try:images = pdf2image.convert_from_path(file_path, dpi=200)if not os.path.exists(dir_path):os.makedirs(dir_path)i = 0for image in images:# 根据路径生成图片的名称name = os.path.split(file_path)[-1] # 提取包含后缀名的文件名new_name = os.path.splitext(name)[0] + "image{}.png".format(i) # 修改后缀名new_path = os.path.join(dir_path, new_name)image.save(new_path, 'png')i+=1os.remove(file_path)except:name = os.path.split(file_path)[-1]print(name+" 文件提取异常, 文件路径为:"+file_path+ " 存储位置为:"+dir_path)
将视频文件转化为图像文件
import numpy as np
import os
import cv2
import matplotlib.image as mp
def get_pic_from_mov(filename, dir_path):"""参数:filename:视频文件路径dir_path:图像保存路径作用:将视频文件中的第一帧图像提取到目标路径中,并删除视频文件"""try:# 从文件读取视频内容cap = cv2.VideoCapture(filename)# ret 读取成功True或失败False# frame读取到的图像的内容# 读取一帧数据ret,frame = cap.read();assert ret==True, "图像读取失败"# 根据路径生成图片的名称name = os.path.split(filename)[-1] # 提取包含后缀名的文件名new_name = os.path.splitext(name)[0] + ".jpg" # 修改后缀名new_path = os.path.join(dir_path, new_name)if not os.path.exists(dir_path):os.makedirs(dir_path)mp.imsave(new_path,frame)cap.release()os.remove(filename) # cv.write()只能使用英文路径,同时会打开文件占用视频文件导致无法删除视频except:name = os.path.split(filename)[-1]print(name+" 文件提取异常, 文件路径为:"+filename+ " 存储位置为:"+dir_path)
将word中的图片提取出来
import zipfile
import os
import shutil
def word2pic(path, tmp_path, store_path):'''参数param path:源文件param tmp_path:中转图片文件夹param store_path:最后保存结果的文件夹(需要手动创建)作用:将docx文件中的图片提取到目标路径中'''try:imgType = os.path.splitext(path)[-1]assert imgType==".docx", "文件并非docx,只有docx文件才能转化为zip"zip_path = os.path.splitext(path)[0] + ".zip"if not os.path.exists(tmp_path):print("创建目标文件夹")os.makedirs(tmp_path)if not os.path.exists(store_path):print("创建目标文件夹")os.makedirs(store_path)# 将docx文件重命名为zip文件os.rename(path, zip_path)# 进行解压f = zipfile.ZipFile(zip_path, 'r')# 将图片提取并保存for file in f.namelist():f.extract(file, tmp_path)# 释放该zip文件f.close()# 将docx文件从zip还原为docxos.rename(zip_path, path)# 得到缓存文件夹中图片列表pic = os.listdir(os.path.join(tmp_path, 'word/media'))# 将图片复制到最终的文件夹中for i in pic:# 根据word的路径生成图片的名称name = os.path.split(path)[-1]new_name = os.path.splitext(name)[0] + inew_path = os.path.join(store_path, new_name)print(new_path)# 复制到对应文件夹下shutil.copy(os.path.join(tmp_path + '/word/media', i), new_path)# 删除缓冲文件夹中的文件,用以存储下一次的文件for i in os.listdir(tmp_path):Type = os.path.splitext(i)[-1]# 如果是文件夹则删除if os.path.isdir(os.path.join(tmp_path, i)):shutil.rmtree(os.path.join(tmp_path, i))# 如果是xml文件,同样删除elif Type==".xml":os.remove(os.path.join(tmp_path, i))os.remove(path)except:name = os.path.split(path)[-1]print(name+" 文件提取异常, 文件路径为:"+path+ " 存储位置为:"+store_path)
使用上述编好的函数,将对应的文件提取图像文件
def get_image(path,tmp_path):"""参数:path: 目标文件夹路径tmp_path: 数据缓冲路径作用:检测.mp4、.MOV .mov .MP4的视频文件,.pdf的pdf文件,.docx的word文件,.zip的压缩包文件,并从中提取出图像存储在目标路径中"""for name in os.listdir(path):filepath = os.path.join(os.path.split(path)[0],name)Type = os.path.splitext(name)[-1]dir_path = os.path.split(fielpath)[0]if Type==".mp4" or Type==".MOV" or Type==".mov" or Type==".MP4":get_pic_from_mov(filepath, dir_path)elif Type==".pdf":pdf2image2(filepath, dir_path)elif Type==".docx":word2pic(filepath, tmp_path, dir_path)elif Type==".zip":Unpack_zip(filepath, dir_path)
由于在分好类的文件夹中,只有NEG文件夹和UNV文件夹中有非图片文件的数据文件,因此支队这两个文件夹进行提取。
fielpath = "E:/jupyter文件/data/NEG/"
tmp_path = "E:/jupyter文件/2021年美赛/pic"
get_image(fielpath,tmp_path)
path = "E:/jupyter文件/data/UNV/"
tmp_path = "E:/jupyter文件/2021年美赛/pic/"
get_image(path,tmp_path)
转化jpg图像格式
由于png图像除了RGB三个颜色通道外,还有第四个透明度的通道。因此,为了将所有图片格式统一,需要将四个文件夹中的png图片文件转化为jpg格式。
import os
from PIL import Image
def png2jpg(path):"""参数:path:图片文件夹路径作用:批量将png格式图片转化为jpg格式"""for name in os.listdir(path):imgpath = os.path.join(path, name)Type = os.path.splitext(name)[-1]if Type==".png" or Type==".PNG":try:img = Image.open(imgpath) # 打开图片img = Image.open(dir)#打开图片img = img.convert("RGB") # 将一个4通道转化为rgb三通道file = os.path.splitext(name)[0] + ".jpg"img.save(path + file)os.remove(imgpath)except:print(imgpath+" 文件转化失败")
fielpath = "E:/jupyter文件/data/NEG/"
png2jpg(fielpath)
fielpath = "E:/jupyter文件/data/POS/"
png2jpg(fielpath)
fielpath = "E:/jupyter文件/data/UNP/"
png2jpg(fielpath)
fielpath = "E:/jupyter文件/data/UNV/"
png2jpg(fielpath)