文章目录
- 亚太杯C题第一小问
- 亚太杯C题第二小问
- 亚太杯C题第三小问
- 亚太杯C题第四小问
- 亚太杯C题第五小问
昨天晚上刚出了亚太杯的成绩,获得了三等奖,毕竟是第一次参加数学建模比赛,不是成功参与奖就很高兴了,结束了之后,还要进行总结复盘,接下来,就是我们队伍的思路。
因为A题和B题都读不懂,所以我们才选了C题,但是坏处是,选C题的人数也很多。
亚太杯C题第一小问


读完第一问,我们不难发现,有几个关键词需要我们注意。
请选择合适指标,收集相关数据,建立塞罕坝对生态环境影响的评价模型,为了定量评价。。。。。。。。对塞罕坝恢复前后的环境状况进行对比分析。
所以我们从第一步开始,先选择合适指标:
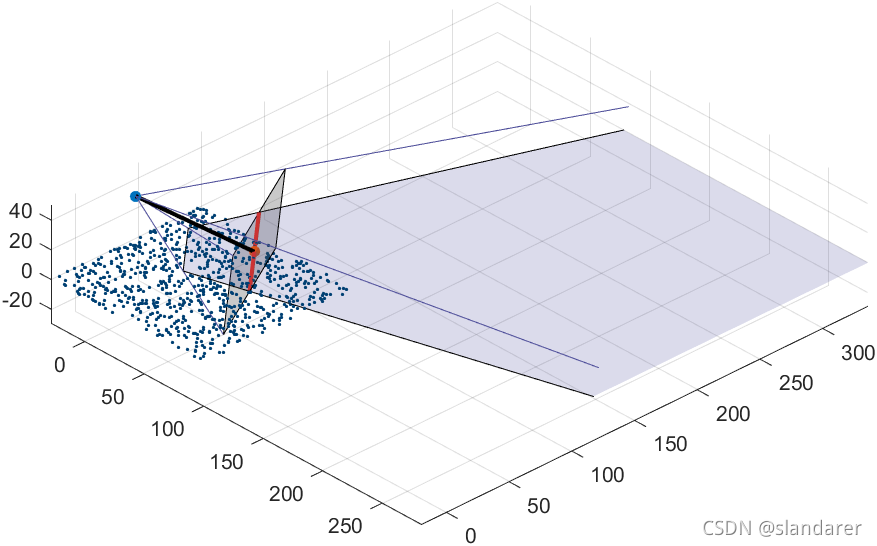
通过对以往环境对比评价类型的论文的参考,我们选择了三个方面,分别是,经济情况,土壤情况,以及二氧化碳情况,六个指标,对环境情况进行分析,采用了层次分析模型,下面是我们的模型示意图:
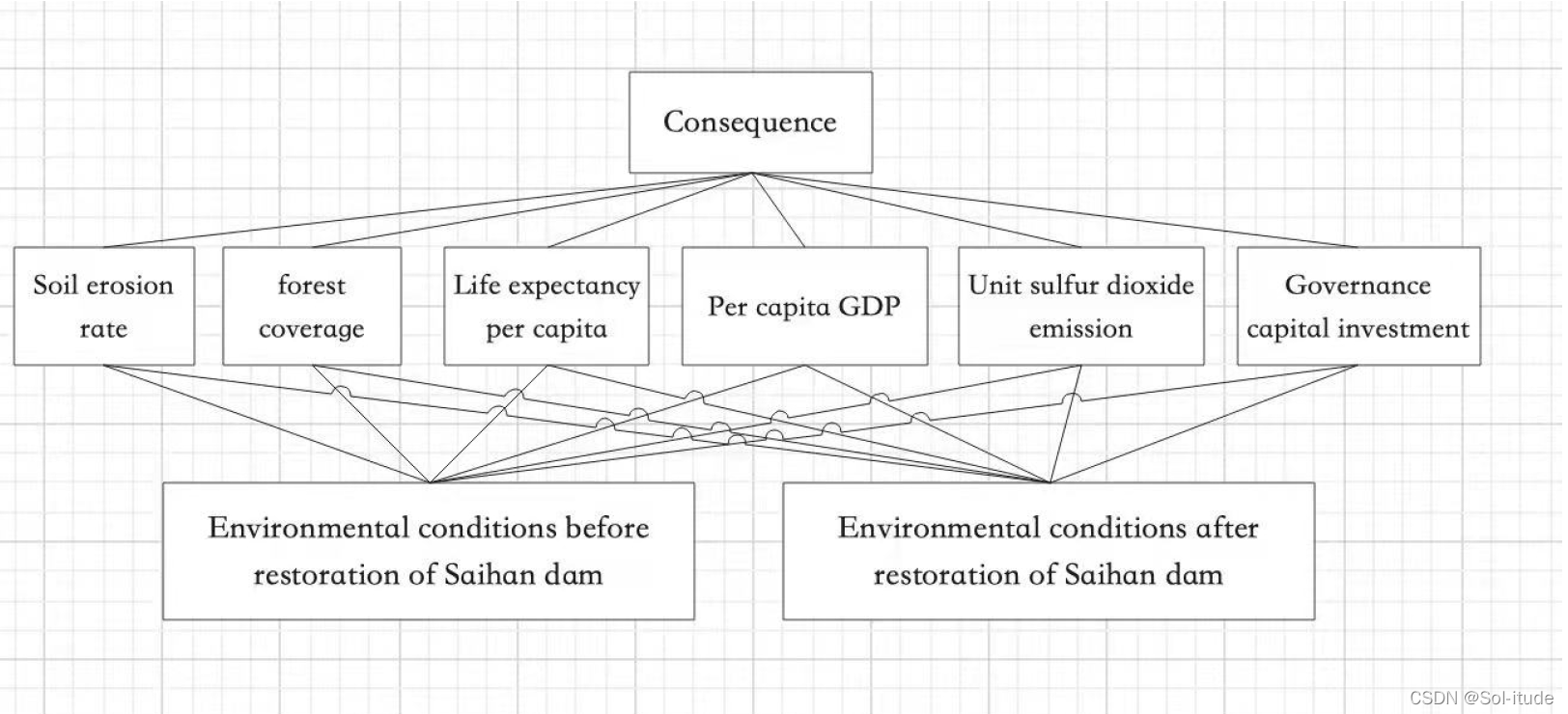
备选层只有两个选择,一个是恢复前的塞罕坝,一个是恢复后的塞罕坝,
第二步就是构建权重矩阵,我们可以得到
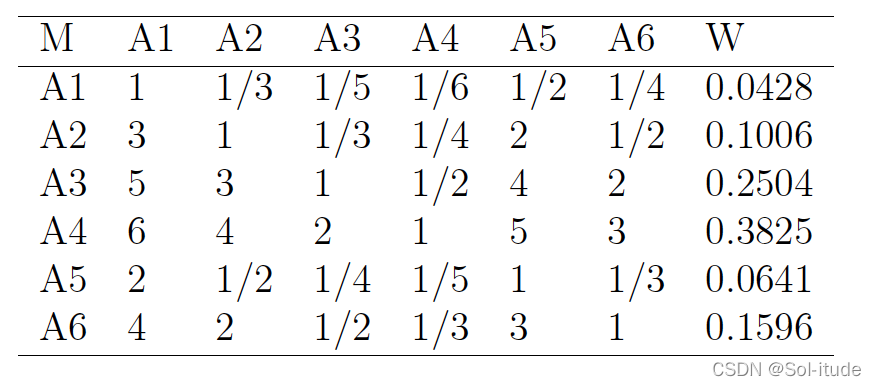
代码如下
disp('input A');
A=input('A=');
[n,n]=size(A);
[V,D]=eig(A);
tempNum=D(1,1);
pos=1;
for h=1:nif D(h,h)>tempNumtempNum=D(h,h);pos=h;end
end
w=abs(V(:,pos));
w=w/sum(w);
t=D(pos,pos);
disp('rules w=');disp(w);disp('bigget t=');disp(t);
CI=(t-n)/(n-1);RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59 1.60 1.61 1.615 1.62 1.63];
CR=CI/RI(n);
if CR<0.10disp(' ACCE PT!');disp('CI=');disp(CI);disp('CR=');disp(CR);
else disp(' NOT ACCEPCT!');
end
最后得到的CR<0.1,一致性检验通过,所以第一题就算是做完了。
优点:
- 快速,用了一个上午就做出来了;
- 简单,因为备选对象只有两个,所以算起来,矩阵很好列
缺点:
-
不准确,因为图速度,选取的指标太少了,其实结果是不准确的;
-
人为因素较多,在建模的时候,一想就知道恢复后更好,所以靠眼看,都知道谁好,有种从结论写过程的感觉;
到这里第一题就做完了,看起来还很顺利,但后面我们就陷入了瓶颈
亚太杯C题第二小问

读完题目之后,我们可以从其中选取几个关键词:请选择合适的指标,收集相关数据,建立数学模型,评估塞罕坝对北京抗沙能力的影响,定量评估塞罕坝在北京抗沙尘暴中的作用。
- 选取合适的指标,我们采用的是主成分分析法,根据第一问,我们选择从经济与森林面积出发建立经济层面与森林面积层面的指标,经过数据收集并且对数据进行了优化处理,通过对京津冀2019年的影响抗沙能力的林业面积和林业经济的各项指标进行主成分分析(在做主成分分析之前一定要进行数据优化,要不然就会因为尺度不一样而出大问题),根据总方差的解释结果,找到占比最大的指标,即为影响最大的指标,通过主成分分析法,找到四个主要指标,分别为林业总产值、林业用地面积、森林覆盖率,找到相关专业论文,找到了AQI,一共四个主要指标。
- 评估塞罕坝对北京抗沙能力的影响,这个要求我们当时也是没读明白,为什么塞罕坝会影响北京的抗沙能力,后来想了想,就是塞罕坝建立前怎么样,与建立后,北京的一些指标的对比,所以根据这四个指标在2001年与2019年的数据对比,得出了结论,(2001年塞罕坝已初步建成,但是国家统计局的网站上,最早只能找到2001,所以我们只选了2001年的),可以看出,2019年北京的四项指标,明显好于2001年。
- 关于塞罕坝在北京抗沙过程中的作用,我们的找到NOx 与SO2 比值的年际变化图:
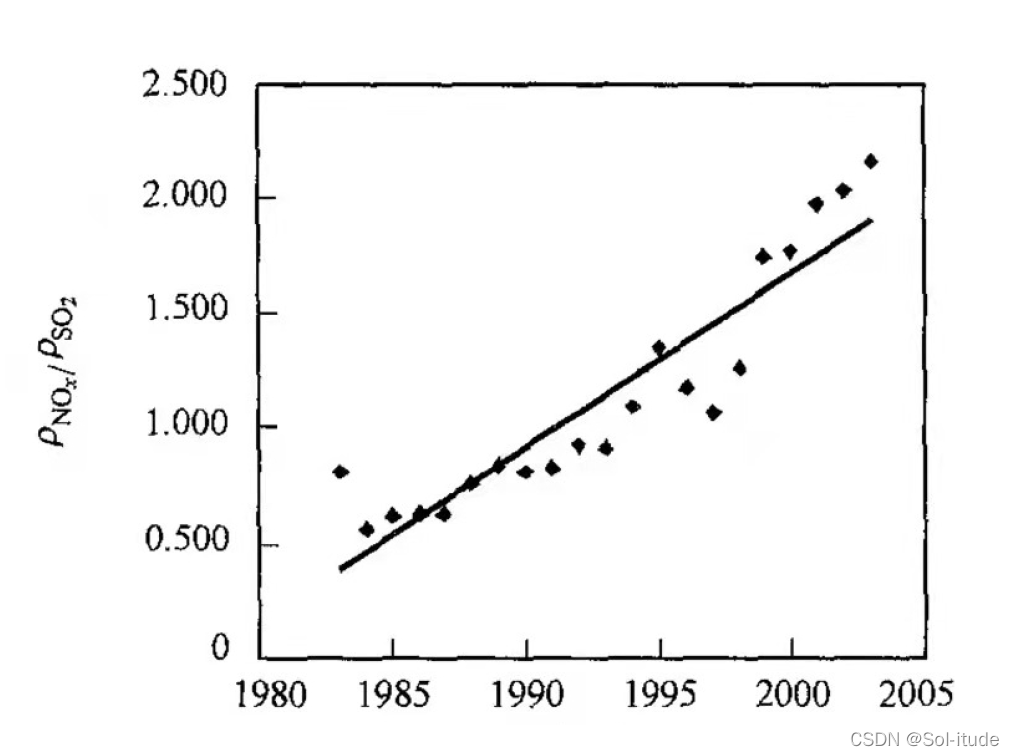
根据增长趋势,我们得出结论:塞罕坝人工林不仅改善了当地的生态环境,而且对京、津及其周边地区的生态环境质量的改善起到重要作用。
亚太杯C题第三小问

刚看到这题,瞬间就懵了,来确定中国哪些地理位置需要建设生态区,一开始没有进行深入思考,就开始疯狂查找数据,我们发现,生态区分为:植物、动物、地形等,还有国家级,市级、县级。。。。。。。一开始就想无头苍蝇一样搜集数据,后来我们发现了关键的一点,将塞罕坝的生态保护模式推广到全国,我们就要弄清楚,塞罕坝的生态模式是什么,通过查阅资料,塞罕坝的生态模式就是,通俗来说,就是有风沙,然后,种树,那我们可不可以找到中国风沙最严重的地区,于是就开始根据全国风沙地图来选择,
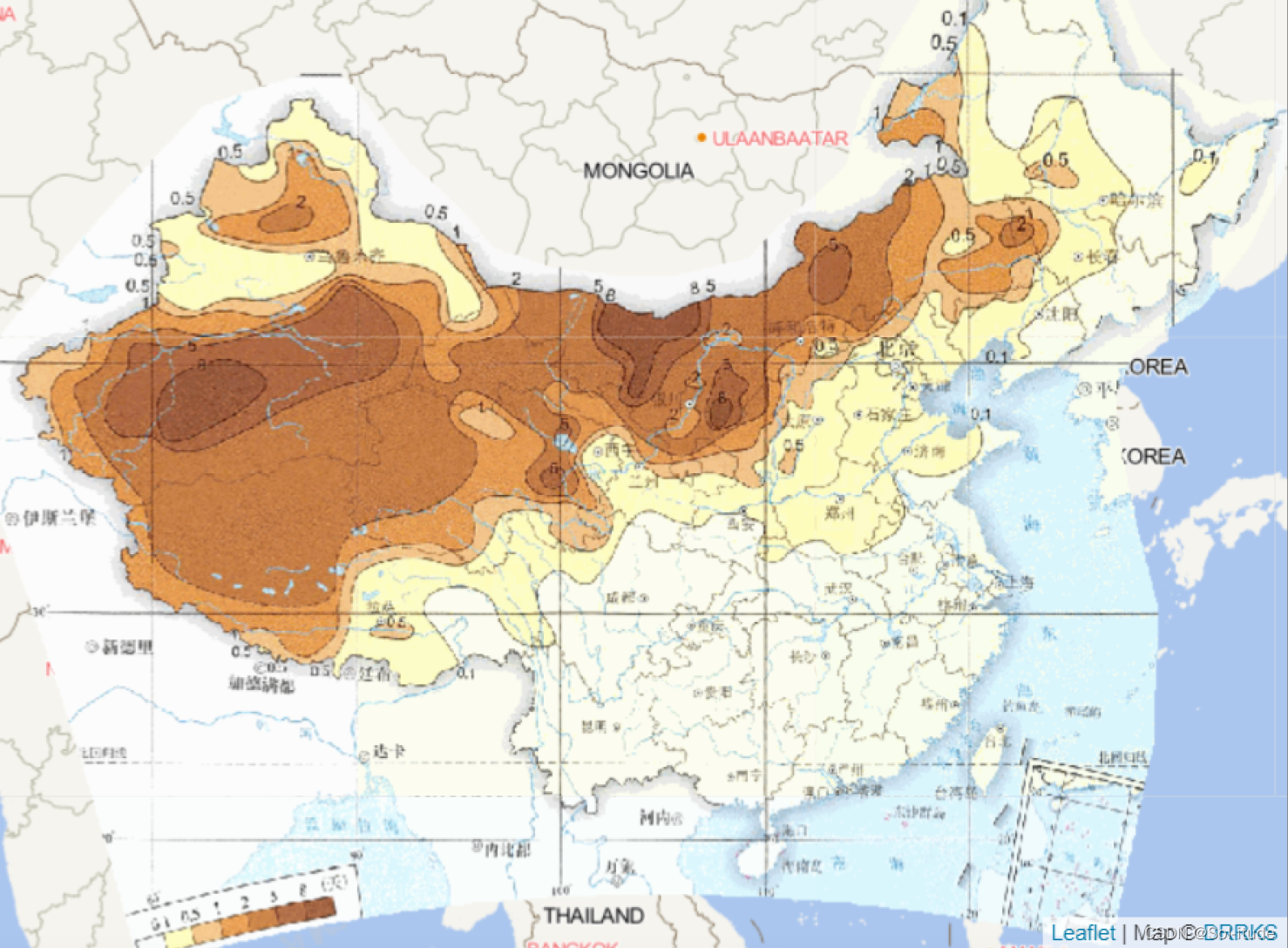
不难看出来,那几个颜色最深的地方,就是风沙最严重的地方,来建立生态保护区。
1.生态保护区的指标:分为两层,一层是森林覆盖率和森林产值,第二层是几个乱七八糟的指标,因为我国建立生态区的标准过于复杂,所以我们从政府文件中选取了几个关键的指标。
2.判断其是否能建立:开始查找数据,因为地理位置偏远而且有的还是小县城,所以数据基本上,只有1年的数据,那没办法了,也只能硬着头皮来上,那么,该如何判断呢,这时,我突发奇想,既然我们这些小地方找不到数据,那我们找全国最大的,于是,我们利用神经网络算法,倒入了几组成功建立生态区的地区数据,经过机器学习,来判断我们找的这几个地方是否能建立生态区,后来一试,误差居然很小
代码如下
y=input(' input data');
n=length(y);
yy=ones(n,1);
yy(1)=y(1);
for i=2:nyy(i)=yy(i-1)+y(i)
end
B=ones(n-1,2);
for i=1:(n-1)B(i,1)=-(yy(i)+yy(i+1))/2;B(i,2)=1;
end
BT=B';
for j=1:(n-1)YN(j)=y(j+1);
end
YN=YN';
A=inv(BT*B)*BT*YN;
a=A(1);
u=A(2);
t=u/a;
t_test=input(' numbers');
i=1:t_test+n;
yys(i+1)=(y(1)-t).*exp(-a.*i)+t;
yys(1)=y(1);
for j=n+t_test:-1:2ys(j)=yys(j)-yys(j-1);
end
x=1:n;
xs=2:n+t_test;
yn=ys(2:n+t_test);
plot(x,y,'^r',xs,yn,'*-b');
det=0;
for i=2:ndet=det+abs(yn(i)-y(i));
end
det=det/(n-1);
disp([' deviation:',num2str(det),'%']);disp([' predict:',num2str(ys(n+1:n+t_test))]);
net = newff(minmax(P),[7,1],{'tansig','purelin'},'trainlm');net.trainParam.show=50;%net.trainParam.lr=0.05;net.trainParam.epochs=1000;net.trainParam.goal=1e-5;[net,tr]=train(net,P,T);net.iw{1,1}net.b{1}net.lw{2,1}net.b{2}
P2=[-1;2];y3=sim(net,P2);
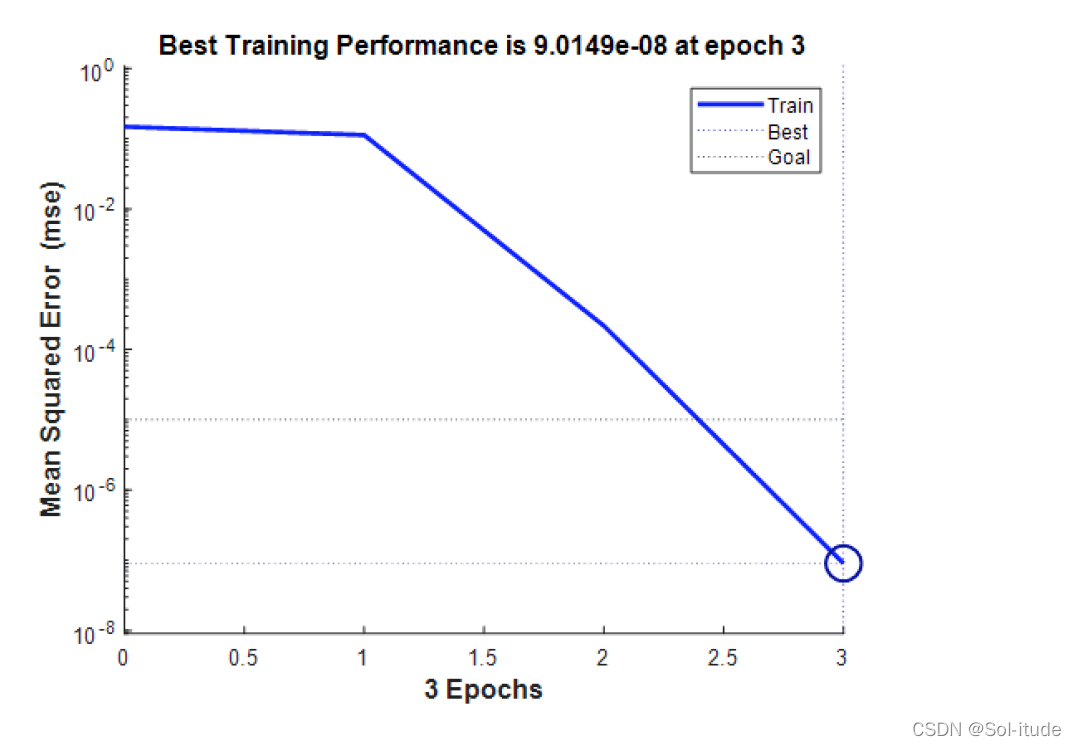
喜出望外,于是我们就利用神经网络算法给解决了问题,最大的缺点就是,数据根本找不到,我们后来都想编上几组 ,但是还好成功做出来了。
当时囫囵吞枣,做出来题就得意忘形了,而且当时都是调用已经写好的函数,也没有搞懂其中的意思,现在才看到我们当时只训练了3轮,怎么说也要100轮起步了。。。。
亚太杯C题第四小问

请从亚太地区选择另一个国家建立数学模型,因为不知道有什么可选取的规则,为了查找数据方便,我们就选了中国的好朋友,巴基斯坦,和第四问的思路差不多,还是寻找风沙图,但我们遇到了一个问题,就是找不到风沙图,毕竟不是在国内,于是转变思路,我们找了森林的分布图以及降水图
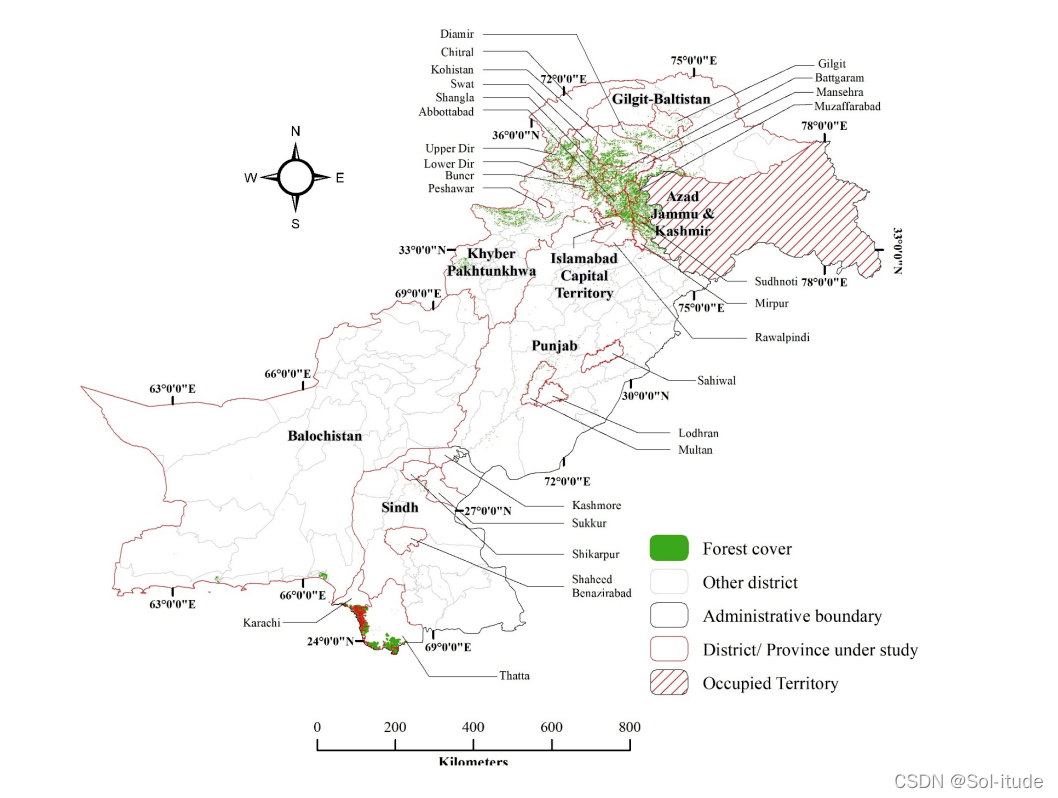
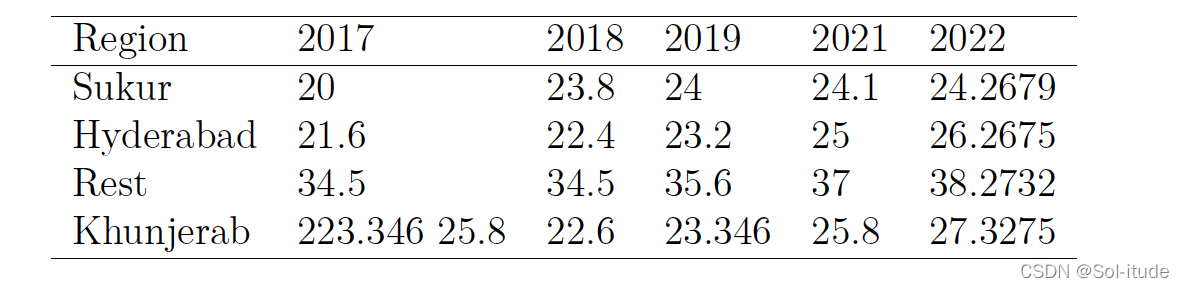
通过枚举法,说白了就是拿眼看 ,我们找到了以下地区的4项指标

通过灰色关联分析,和灰色预测,先判断其关联性,再通过灰色预测的斜率判断其建立生态区的规模,最终得出结果,找到了适合建立生态区的地区
代码如下
y=input(' input data');
n=length(y);
yy=ones(n,1);
yy(1)=y(1);
for i=2:nyy(i)=yy(i-1)+y(i)
end
B=ones(n-1,2);
for i=1:(n-1)B(i,1)=-(yy(i)+yy(i+1))/2;B(i,2)=1;
end
BT=B';
for j=1:(n-1)YN(j)=y(j+1);
end
YN=YN';
A=inv(BT*B)*BT*YN;
a=A(1);
u=A(2);
t=u/a;
t_test=input(' numbers');
i=1:t_test+n;
yys(i+1)=(y(1)-t).*exp(-a.*i)+t;
yys(1)=y(1);
for j=n+t_test:-1:2ys(j)=yys(j)-yys(j-1);
end
x=1:n;
xs=2:n+t_test;
yn=ys(2:n+t_test);
plot(x,y,'^r',xs,yn,'*-b');
det=0;
for i=2:ndet=det+abs(yn(i)-y(i));
end
det=det/(n-1);
disp([' deviation:',num2str(det),'%']);disp([' predict:',num2str(ys(n+1:n+t_test))]);
亚太杯C题第五小问

第五问应该是纯文字描述我们的模型,不用再建模了,所以就基本上把前四题叙述了一遍。
写完了之后,算上附录一共26页,成就感满满,也没想到能够取得三等奖,今年国赛加油。