Spark学习之使用idea开发Spark应用
该文章是基于jdk1.8,idea开发工具,maven都配置好的前提下进行讲述的。
背景
由于已经在远程centos服务器上部署了saprk服务,但基于spark的应用程序的代码却是在本地idea开发的,那么如何能让本地开发的spark代码能在远程spark服务上运行调试便成了迫切需要解决的问题。
idea下scala插件安装
idea开发工具,File->setting->Plugins->Browse respositories,搜索scala,下载和自己idea版本对应的插件。
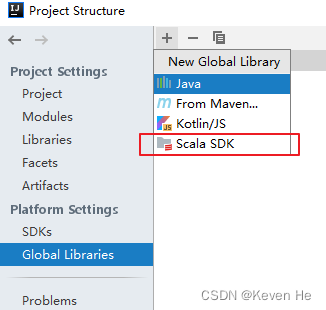
idea下新建maven项目

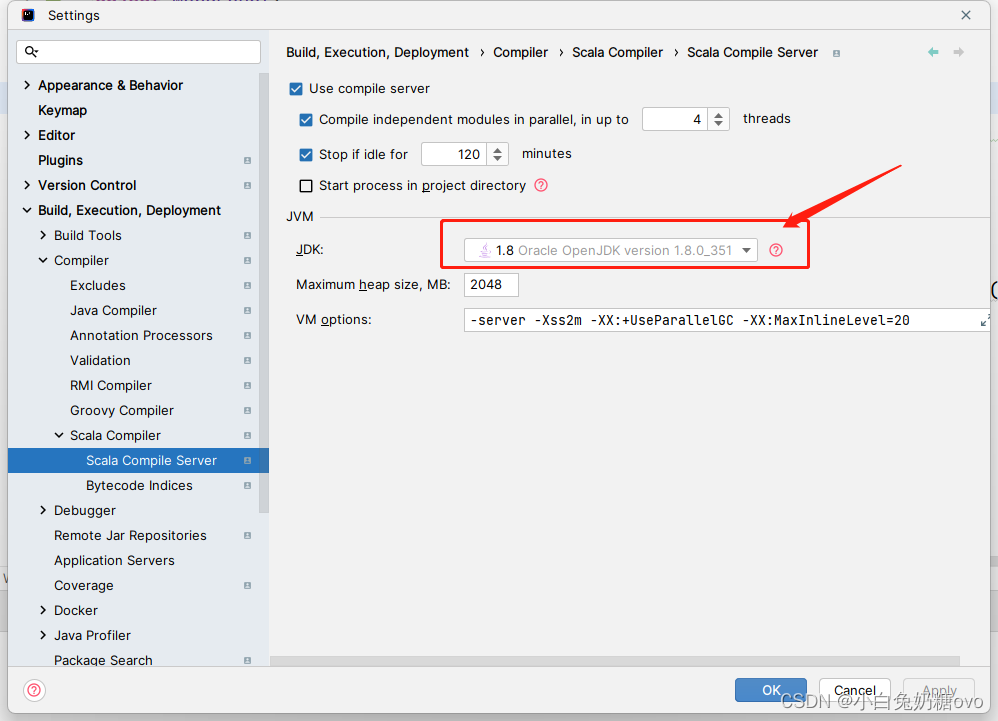
配置项目的Scala

配置maven依赖
修改pom.xml文件,新增如下内容:
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.5</version></dependency>
</dependencies><build><plugins><plugin><groupId>org.scala-tools</groupId><artifactId>maven-scala-plugin</artifactId><version>2.15.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins>
</build>
其中,spark-core版本要和《spark3.1.2 单机安装部署》文章中部署的spark版本一致,因为在文章《Spark开发实战之Scala环境搭建》中本地scala配置的版本是2.12,否则程序运行会报错。
配置完成后等待依赖包加载完毕。
新建一个Scala对象,代码如下:
object WordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("WordCount").setMaster("spark://localhost:7078")val sc = new SparkContext(conf)val file = sc.textFile("/home/bigData/softnew/spark/README.md")// val rdd = file.flatMap(line => line.split("")).map(word => (word,1)).reduceByKey(_+_)// rdd.collect()// rdd.foreach(println)// rdd.collectAsMap().foreach(println)println("#####################"+file.count()+"#####################")println("#####################"+file.first()+"#####################")}}
配置远程部署路径
Scala文件最终会被打包成jar文件,然后使用spark-submit工具提交到spark主节点执行任务。由于spark-submit工具在远程服务器,所以需要配置jar包到远程服务器的部署,如下:
idea Tools->deployment->configuration,弹出deployment窗口,点击+号,按下图选择Type,name自定义:

配置connection:

其中,sftp host、user name、Password 是远程服务器ip、账号、密码,配置完后可以点击 SFTP host后的TestSFTP connection按钮测试是否可连接。Root path 是远程服务器部署jar包的目录。
配置Mappings:

其中,deployment path on server spark 路径是相对于配置connection 中的 Root path。
idea Tools->deployment->option,配置如下:

调用 mvn package 打包,然后上传到远程服务器:

到远程服务器Root path 下 找到 上传jar包,然后执行如下命令将jar上传到spark服务器,并在开启jvm在8336端口监听:
spark-submit --class com.spark.WordCount --master spark://localhost:7078 --driver-java-options "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=8336" spark-1.0-SNAPSHOT.jar
其中,–master spark master 节点地址
address=8336 jvm监听端口
server=y y表示启动的JVM是被调试者。如果为n,则表示启动的JVM是调试器
suspend=y y表示启动的JVM会暂停等待,直到调试器连接上才继续执行,如果为n,则JVM不会暂停等待
如下图,启动监听成功。
[root@localhost target]# spark-submit --class com.spark.WordCount --master spark://localhost:7078 --driver-java-options "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=8336" spark-1.0-SNAPSHOT.jar
Listening for transport dt_socket at address: 8336
配置远程调试
如下:

在右上角debug处选择刚才建立的远程调试项目,点击运行。
可以看到刚才spark-submit启动的监听界面产生了调试日志,如下:
21/07/09 13:58:57 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
21/07/09 13:58:57 INFO DAGScheduler: Job 0 finished: count at WordCount.scala:18, took 3.201509 s
#####################108#####################
21/07/09 13:58:57 INFO SparkContext: Starting job: first at WordCount.scala:19
...
21/07/09 13:58:57 INFO TaskSchedulerImpl: Killing all running tasks in stage 1: Stage finished
21/07/09 13:58:57 INFO DAGScheduler: Job 1 finished: first at WordCount.scala:19, took 0.088650 s
###################### Apache Spark#####################
21/07/09 13:58:57 INFO SparkUI: Stopped Spark web UI at http://192.168.136.53:4040
21/07/09 13:58:57 INFO StandaloneSchedulerBackend: Shutting down all executors
本地开发环境配置
本地开发环境配置中不需要搭建windows版的spark环境,直接使用项目中引入的spark的相关jar包来运行spark程序,提交到本地spark运行。只需要做如下配置(setMaster设置为local):val conf = new SparkConf().setAppName("WordCount").setMaster("local")
运行结果如下:

结论
本文讲述的调试方式仅适合单人学习开发的场景,不适合多人开发,因为都要观察远程服务器的调试日志,会搞混。若是在实际公司开发场景中,还是建议在在本地进行开发调试。
参考文章
window+idea搭建远程调试spark环境